Sabitlenmiş Tweet

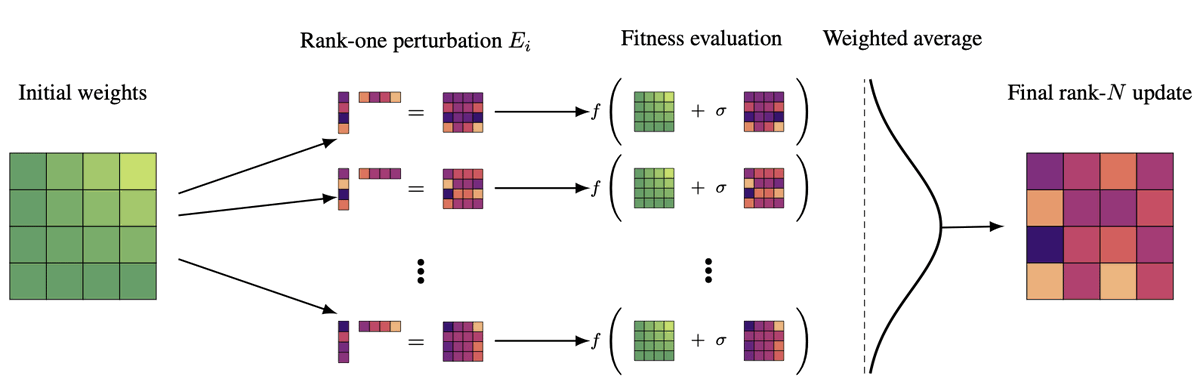
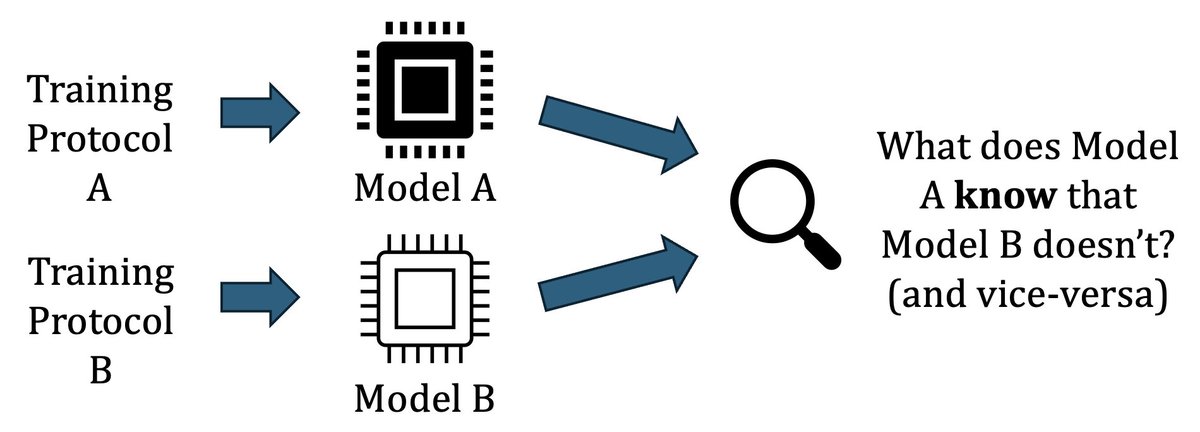
Excited to share our paper Representational Difference Explanations (RDX) was accepted to #NeurIPS2025! 🎉RDX is a new method for model diffing designed to isolate 🔍 representational differences. 1/7
English
Neehar Kondapaneni
78 posts

@TheRealPaneni
Caltech PhD @ The Vision Lab | Researching model interpretability with a focus on model comparison/diffing.

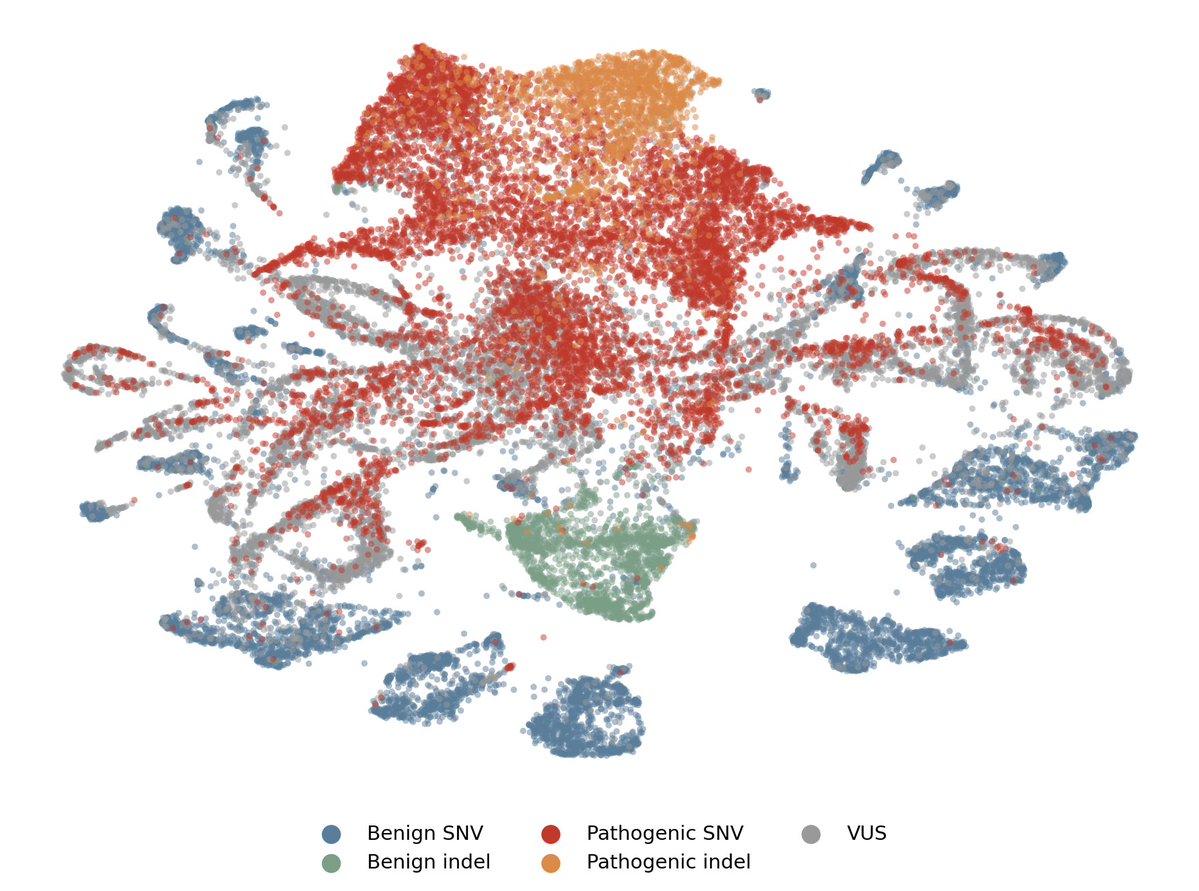
Post-training can introduce harmful side effects. Probes can trace one such effect to specific training data, which can be filtered to cut the behavior by 63% — beating LLM-judge and gradient attribution at 10× lower cost. Bonus: probes can surface unknown side effects! (1/6)



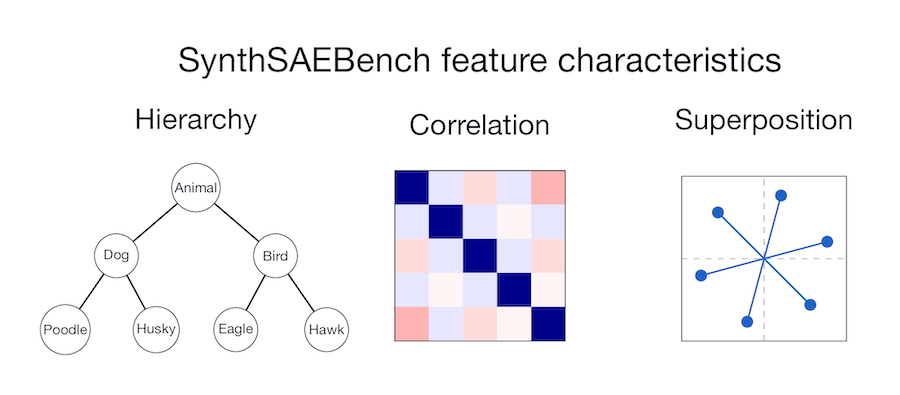


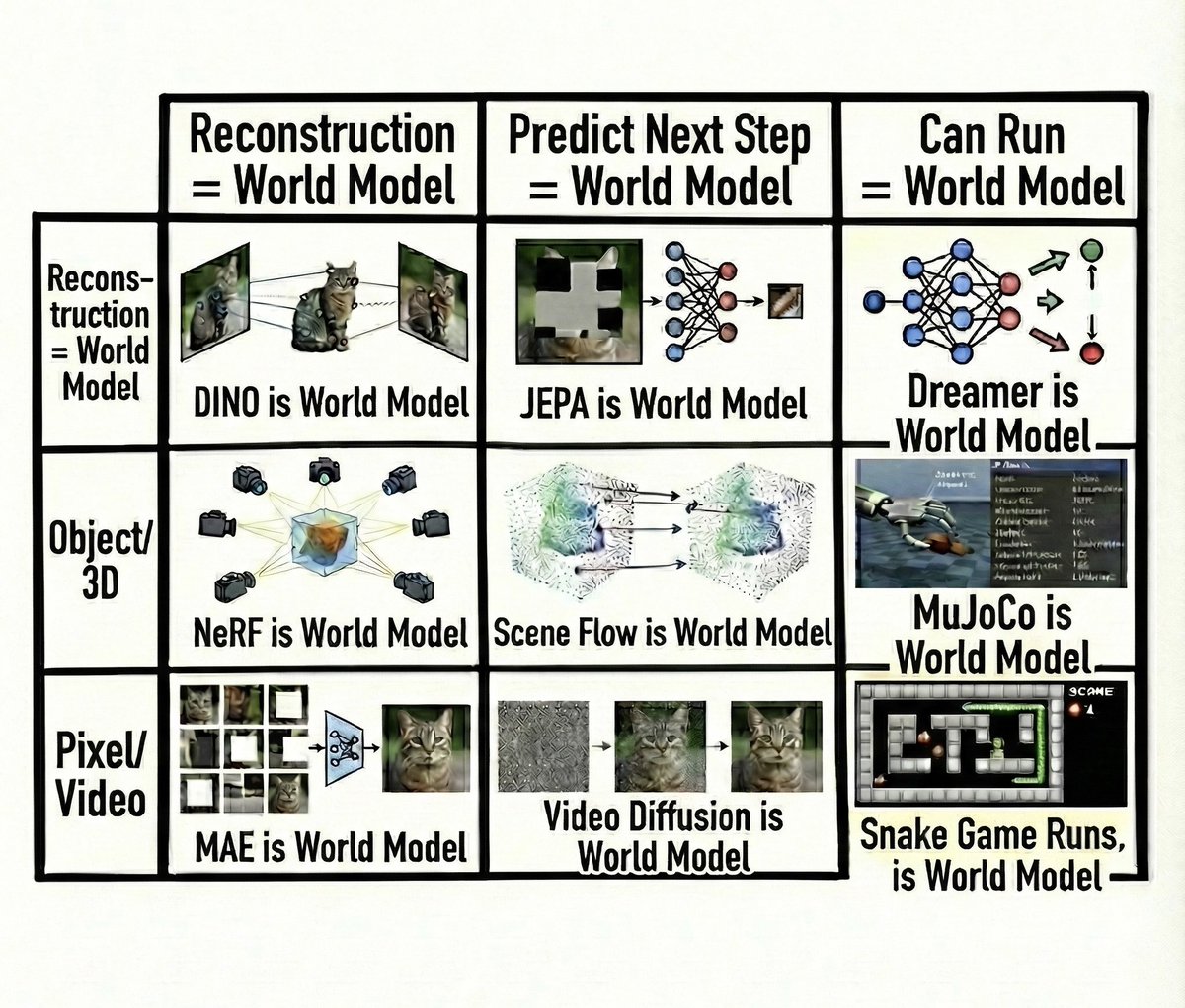
State of the art World Models still lack a unified world memory for representing and predicting dynamics out of their field of view. Why is that, and how can we fix it? Introducing Flow Equivariant World Models: models with memory capable of predicting out of view dynamics!🧵⬇️






We're stoked to see everyone at the first workshop on interpreting cognition in deep learning models today @NeurIPSConf! There will be an extremely exciting lineup of speakers and spotlight talks, with an equally exciting poster session in between. (1/3)
Excited to share our paper Representational Difference Explanations (RDX) was accepted to #NeurIPS2025! 🎉RDX is a new method for model diffing designed to isolate 🔍 representational differences. 1/7