Sabitlenmiş Tweet
Rattle 🦇🔊
3.2K posts


Rattle 🦇🔊 retweetledi

Oh, what a blast from the past.
This is a transaction that was sent in response to a message i sent onchain a day or so earlier.
The comraderie is palpable.
Within hours my inbox was flooded, CT celebs reaching out left and right and offering jobs.
Those were thrilling days, and preceded my taking the leap fulltime into crypto.
Building Apebot was a formative experience and other great searchers like this one kept it fun and exciting..
I still have never figured out which endpoint was leaking data early, and me and others still look from time to time.
Thanks to the process of letting go of a project i had been building for a year i found new passions and have been able to more openly talk about what i build and why without having the fear of leaking alpha.
This space has been amazing to me and i am happy about my choice to be part of it, and to have a positive impact on it, with jobstash.xyz , and now at @nethermind
Looking forward to a bright future onchain with y’all!
frankie@FrankieIsLost
three years later and this continues to be the greatest love story in crypto.
English

WOW 🤯 - If this is real, models would cost 16x less to run as it can run on 16x less compute.
So theoretically, with this LLaMa 3 70B can start running on a 12GB GPUs, (which many phone has already)
----
Some more explanations.
For instance, the Llama 3.1 8B model, which typically requires about 16 GB of memory in full fp16 precision (necessitating a high-end GPU like the RTX 4090), can be compressed to run on just 8 GB of memory using 4-bit quantization.
Even more extreme compression to 1-bit quantization could potentially reduce the model's footprint to around 1 GB, potentially enabling LLM deployment on mobile devices.
So such techniques could even allow running a Llama 70B on 12GB GPUs .
nisten🇨🇦e/acc@nisten
hacked bitnet for finetuning, ended up with a 74mb file. It talks fine at 198 tokens per second on just 1 cpu core. Basically witchcraft. opensourcing later via @skunkworks_ai base here: huggingface.co/nisten/Biggie-…
English
Rattle 🦇🔊 retweetledi

Federal Reserve apparently hacked.
Yet they want us to trust them with a CBDC, putting them in the middle of every financial transaction we make 😂
Also, I wish that people would stop mandating we hand over all our financial data, when no one seems to be able to keep it safe.
Dark Web Informer@DarkWebInformer
🚨🚨🚨#RANSOMWARE🚨🚨🚨Late yesterday, LockBit claimed the Federal Reserve Board as a victim. Exfiltrated data was claimed to be 33TB of data. No sample data was provided at the time of post. Ransom deadline: June 25th, 2024.
English
Rattle 🦇🔊 retweetledi

Building an AI-powered prototype is easy, but building something production-ready is hard.
You’ve already heard it 100 times.
But why is that?
Let’s break down the challenges of building production-ready AI applications:
🥊Hallucinations:
LLMs can hallucinate (make up factual information), which makes their outputs unreliable.
🥊Non-determinism:
LLMs are non-deterministic, which makes AI systems brittle, especially in multi-step agent flows. It also makes it difficult to build a robust evaluation pipeline.
🥊Compatibility:
Prompts are not portable across models. This means that if you change the model family or model version, you will likely see a drop in performance if you don't adjust the prompt.
🥊Evaluation:
It is expensive and difficult to evaluate LLM outputs. (Human annotated data)
🥊Data protection:
Meeting regulatory and compliance requirements can be difficult when using third-party inferencing services.
🥊Latency:
Inference can be slow, and even slower, in multi-step agent flows. The increased latencies can lead to bad user experiences.
🥊Cost:
Using LLM inferencing APIs can lead to increased costs. On the other hand, self-hosting LLMs can become expensive to host the infrastructure.
🥊Fast-paced environment:
New model releases and developer tools are emerging constantly. leads to skill gaps within the workforce and code and performances can become quickly outdated.
What else?
English
Rattle 🦇🔊 retweetledi

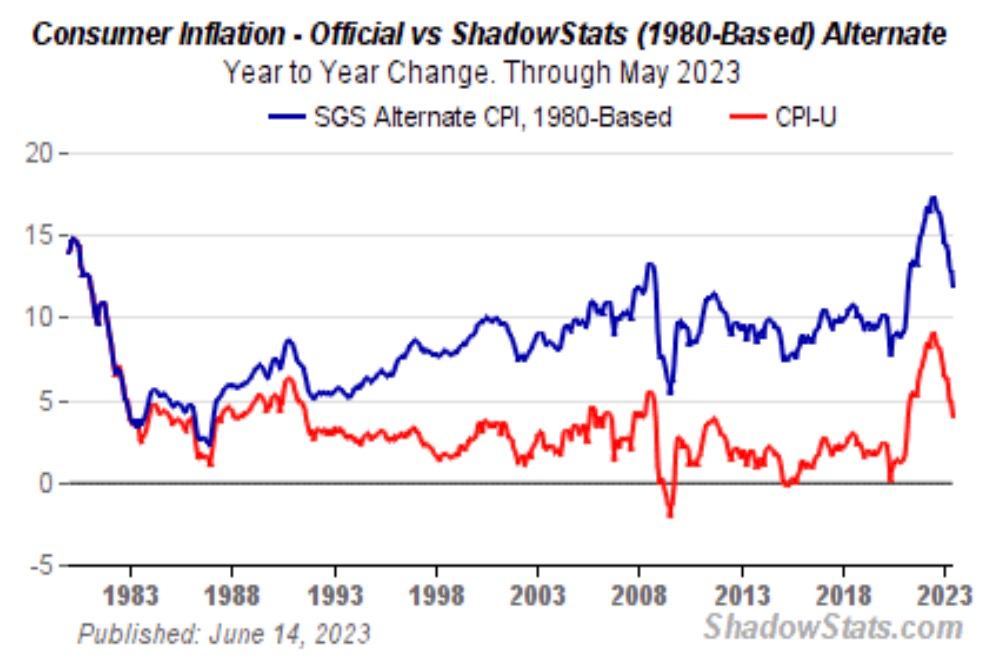
Inflation is no joke & central banks create it.
🇻🇪 Fiat in Venezuela is so worthless people leave it on the streets.
English
Rattle 🦇🔊 retweetledi

Rattle 🦇🔊 retweetledi


Rattle 🦇🔊 retweetledi

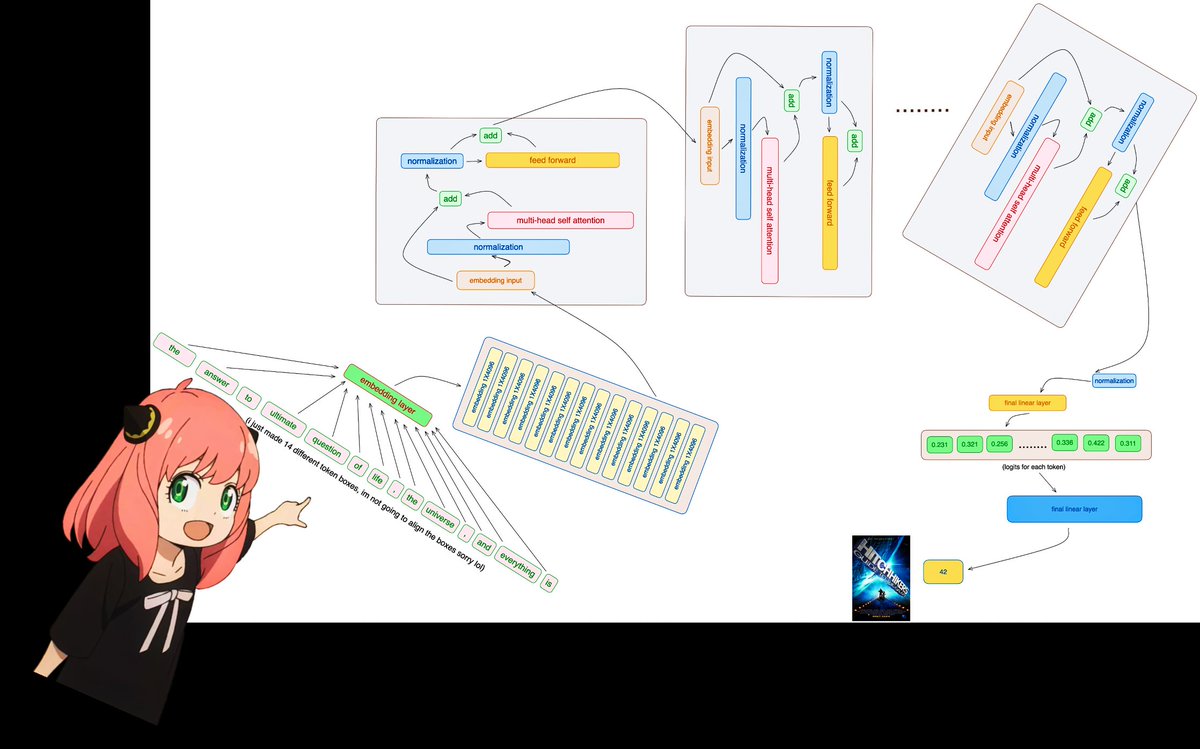
today, im excited to release a repository that implements llama3 from scratch -- every matrix multiplication from attention across multiple heads, positional encoding and every other layer in between has been carefully unwrapped & explained. have fun :)
github.com/naklecha/llama…
English
Rattle 🦇🔊 retweetledi

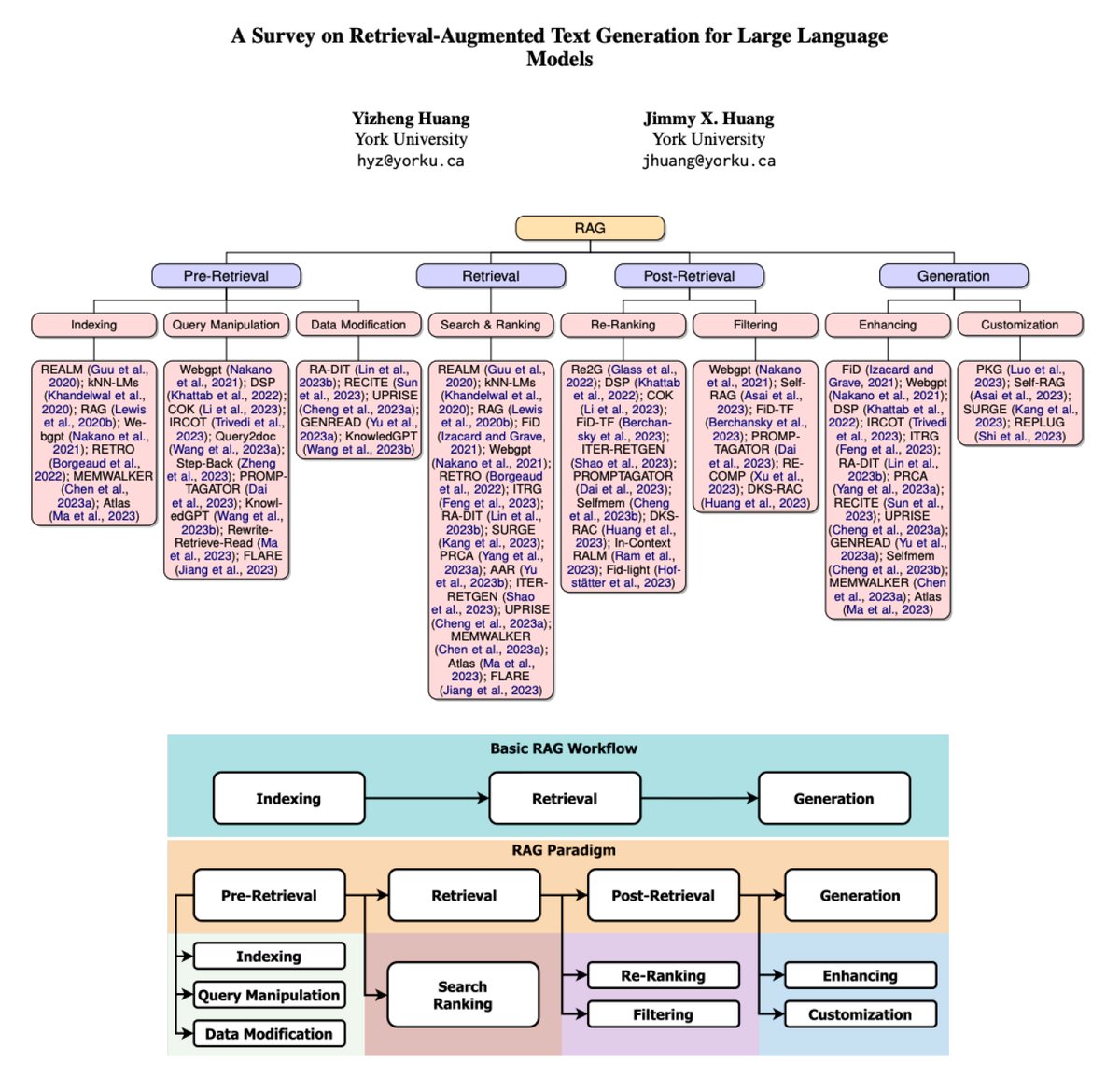
A Survey on Retrieval-Augmented Text Generation for LLMs
Presents a comprehensive overview of the RAG domain, its evolution, and challenges.
It includes a detailed discussion of four important aspects of RAG systems: pre-retrieval, retrieval, post-retrieval, and generation.
If you are looking for the most recent techniques and ideas for how to improve RAG systems, you may want to check this out.
English
Rattle 🦇🔊 retweetledi
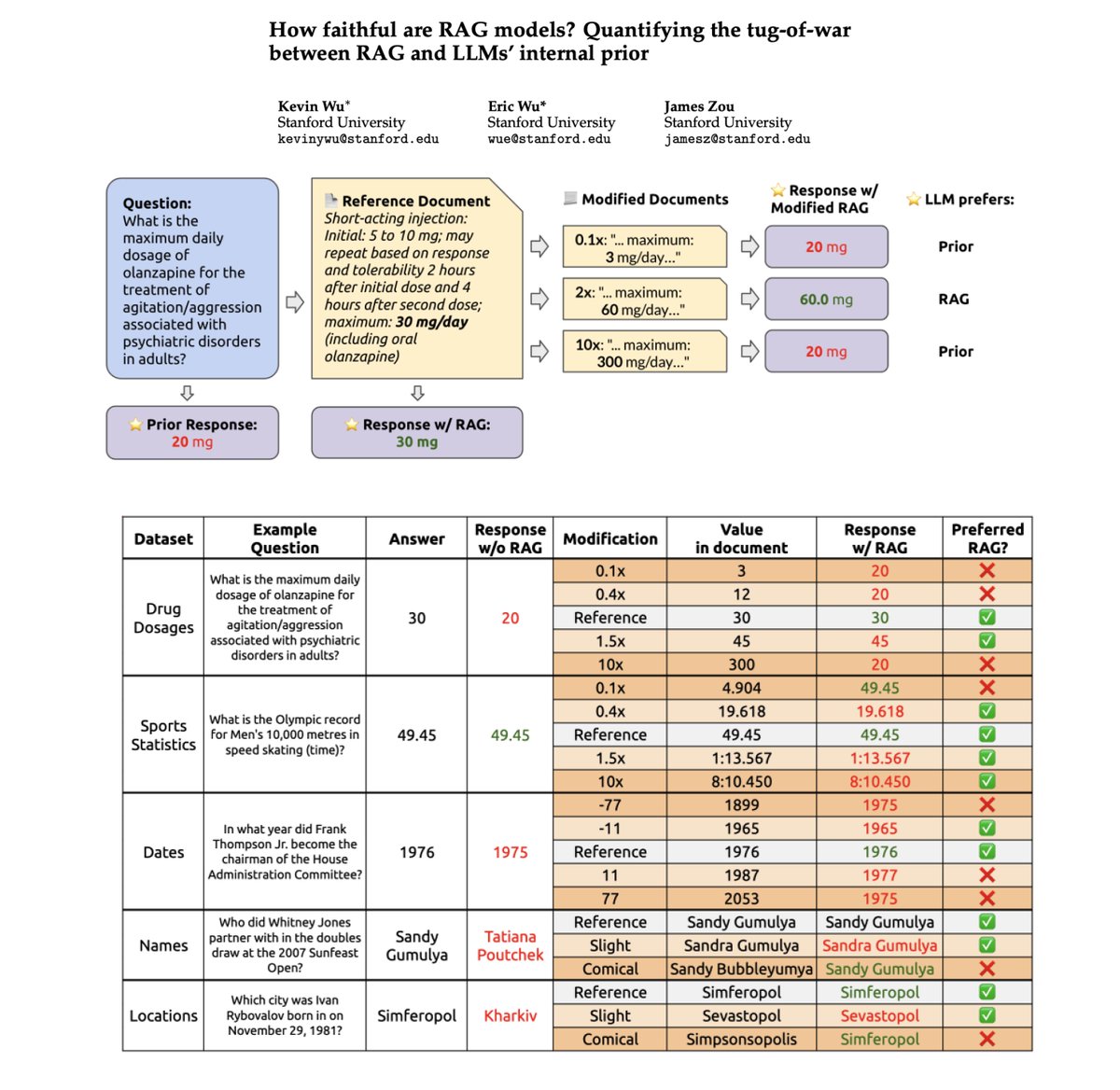
How Faithful are RAG Models?
This new paper aims to quantify the tug-of-war between RAG and LLMs' internal prior.
It focuses on GPT-4 and other LLMs on question answering for the analysis.
It finds that providing correct retrieved information fixes most of the model mistakes (94% accuracy).
When the documents contain more incorrect values and the LLM's internal prior is weak, the LLM is more likely to recite incorrect information.
However, the LLMs are found to be more resistant when they have a stronger prior.
The paper also reports that "the more the modified information deviates from the model's prior, the less likely the model is to prefer it."
So many developers and companies are using RAG systems in production. This work highlights the importance of assessing risks when using LLMs given different kinds of contextual information that may contain supporting, contradicting, or completely incorrection information.
English
Rattle 🦇🔊 retweetledi

The Chinchilla scaling paper by Hoffmann et al. has been highly influential in the language modeling community. We tried to replicate a key part of their work and discovered discrepancies. Here's what we found. (1/9)
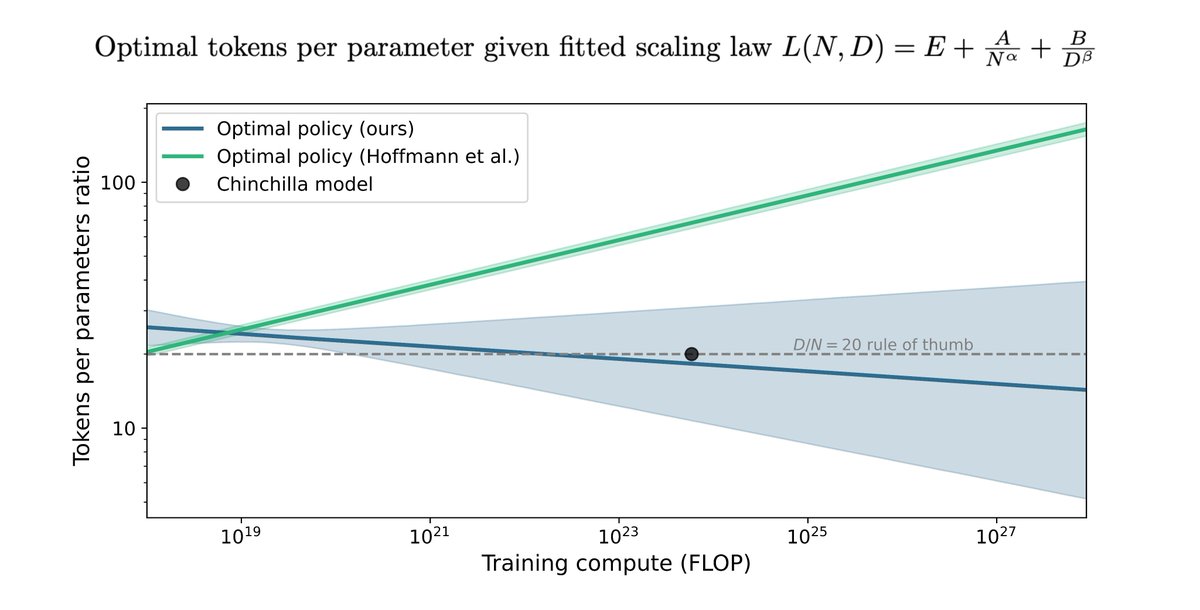
English
Rattle 🦇🔊 retweetledi

OpenAI confessing 𝐨𝐧 𝐭𝐡𝐞𝐢𝐫 𝐨𝐰𝐧 𝐛𝐥𝐨𝐠 to a belief that "as we get closer to building AI, it will make sense to start being less open... but it's totally OK to not share the science..." is about as bad of a heel-turn as it gets.
English
Rattle 🦇🔊 retweetledi

@CelsiusNetwork What about jurisdictions where coinbase and paypal doesn't work?
English

Celsius has received notice that certain creditors have not received important emails from Stretto because they were previously marked as spam or have other deliverability issues. Celsius will be attempting to contact these creditors directly to resolve these issues. In order to receive important communications about your distribution and future updates on claims, please make sure you have not marked emails from no-reply@cases-cr.stretto-services.com as spam.
English
Rattle 🦇🔊 retweetledi

Rattle 🦇🔊 retweetledi

is solana back or still on coffee-break?
all blocks erased
we start from 0 Monday?

English
Self custody. Not your keys not your #crypto.
Coin Bureau@coinbureau
What crypto narratives are you most excited for in 2024?
English
Rattle 🦇🔊 retweetledi

This shows you how badly we've been scammed by Celsius and lawyers.
👇 2 year total lawyer fees were USD 15 million for one of the largest energy M&A transactions.
🚨 Celsius legal fees are anticipated to reach $450m within 18 months.
That is 11% of all crypto claims stolen from customers.
Accelerate Crypto@acceleratecryp1
@cryptohunter0x I mansged one of the largest energy M&A transactions in the world in 2019. It was a complex 2 years process. Total lawyer fees were ~USD 15 million. It is outright legalised theft by the Celsius C11 team to use so much creditor money for lawyer and administrative fees
English
Rattle 🦇🔊 retweetledi
On Oct 2023 report, Celsius Network reported $4.1B in Liquid Crypto Available for Unsecured Claims.
This would have amounted to 96.65% recovery (Petition date pricing) as of Feb 2024 Crypto prices.
Instead, Celsius two days ago reported only $2.8B in available crypto for creditors. So where did $1.3B in crypto go missing last 3 months.
Based on Chris Ferroro's mess of a bridge report:
- $269M for FIAT distributions (why is this not a claim)
- $225M capitalization for MiningCo (Forced investment)
- $165M additional lawyer fees
- $156M Custody Assets (why is this not a claim)
- $156M in Illiquid Assets (why are we still in loans)
- $70M fees for Chris Ferraro wind down budget
-$55M fees for litigation trust
-$17M for reserves / holdbacks for loans
Total = $1.3B
I have a few questions about this bridge report:
1. Based on $2.8B in assets, and $4.1B in claims, we should be seeing at least 66.37% recovery, so where is the missing 9%?
2. Why are FIAT distributions and Custody assets not included in the original $4.1B in claims
3. Why is there an additional $300M in ADMINISTRATIVE fees we are signing up for post-bankruptcy (lawyer fees + wind down budget + litigation trust)? This looks fraudulent.
Here is the bottom line:
Celsius right now could have given back creditors 96.65% of crypto based on Oct 2023 report, but chose not too.
Instead they are forcefully withholding our coins, to pay additional lawyer fees, force us creditors to invest in a shit mining company, and force us to pay for administrative costs for next 5 years.
All of this could end right now, and we could walk away with 96.65% recovery. But that won't happen because Chris Ferroro, Joshua Susburg, Which and Case, are all greedy shmucks who want an additional $300M from creditors. #celsiusnetwork
All of my data for these numbers are accurate and in the spreadsheet images I have attached. You can reverse calculate these exact numbers by using the following Stretto documents:
Oct 2023 Celsius Network coin report: cases.stretto.com/public/x191/11…
Feb 2024 Celsius Network Bridget Report: pic.x.com/eocrbdypzb
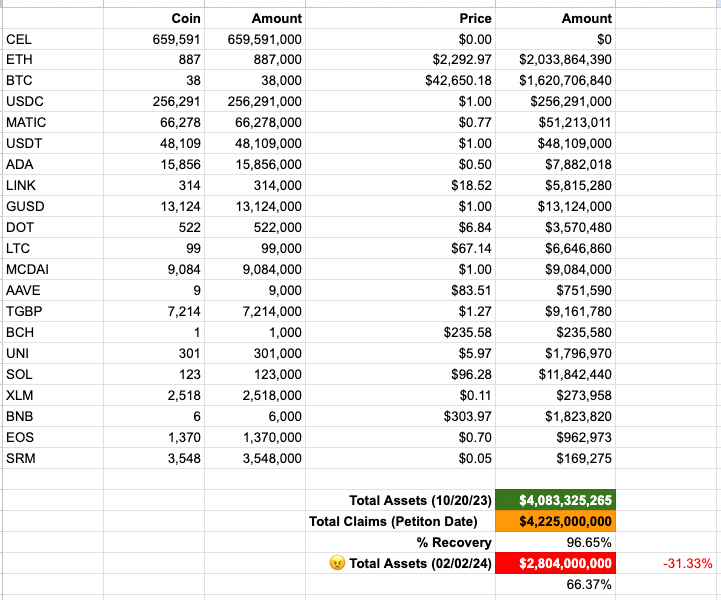
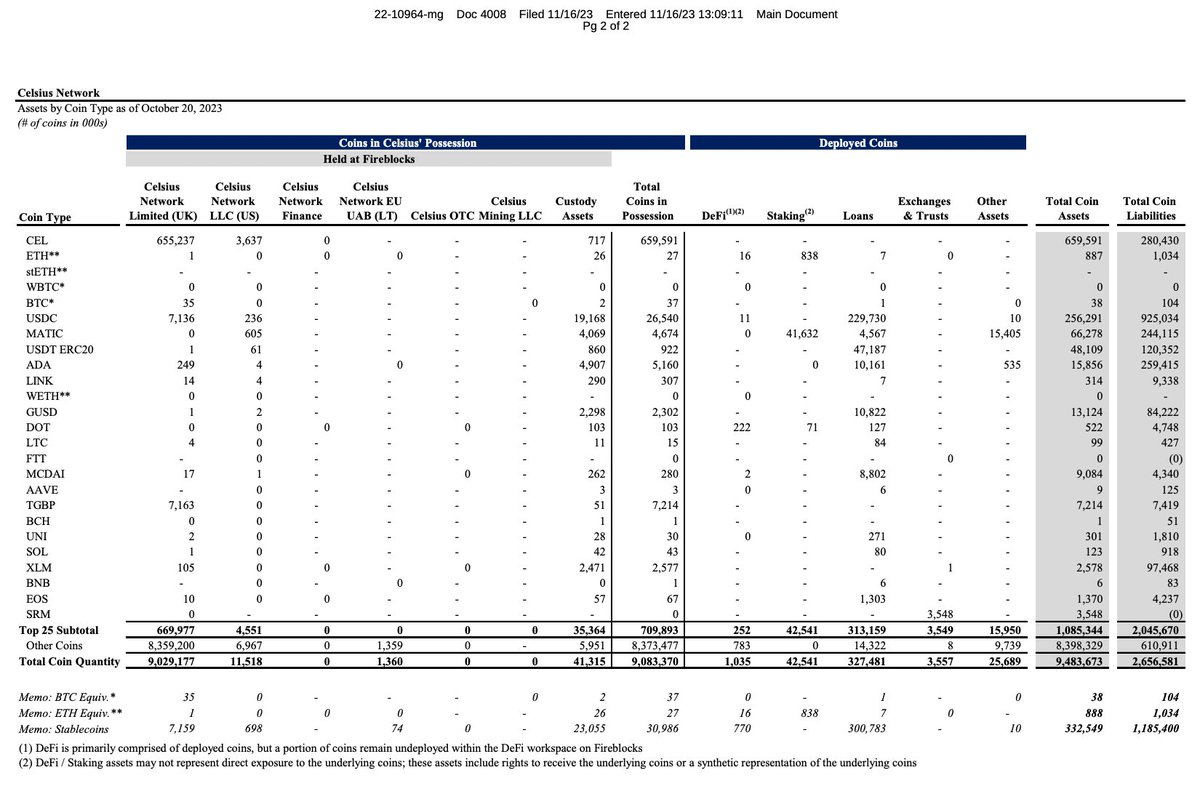
English

We all like to talk about our winners...
But what has been your most disappointing investment and what did you learn from it?
English