Sabitlenmiş Tweet

1/🧵
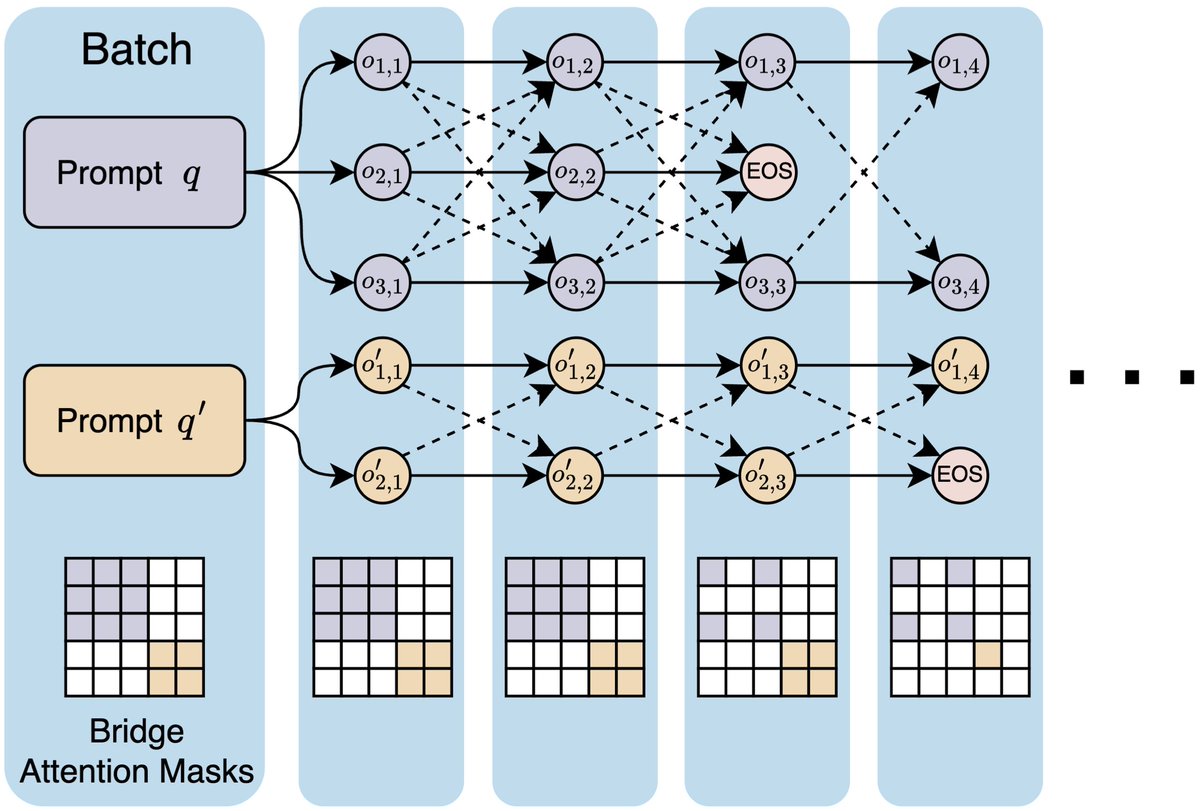
🎉Introducing Bridge🌉, our parallel LLM inference scaling method that shares info between all responses to an input prompt throughout the generation process! Bridge greatly improves the quality of individual responses and the entire response set!
📜arxiv.org/pdf/2510.01143
English







