@micheltamanda @TheAhmadOsman Interesting to see people confused on how AI will take jobs lol
English
Richard Daffy
1.1K posts














@1337hero How do you deal with the lack of CUDA support? I know we are getting screwed with Nvidia cards but dependency hell is real.


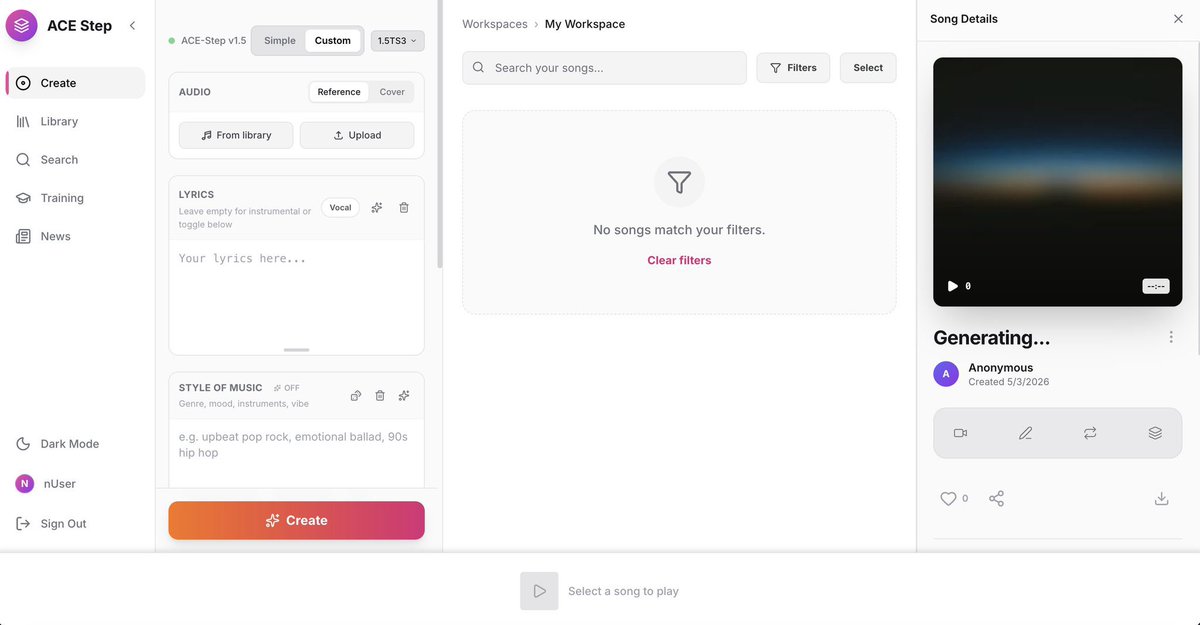
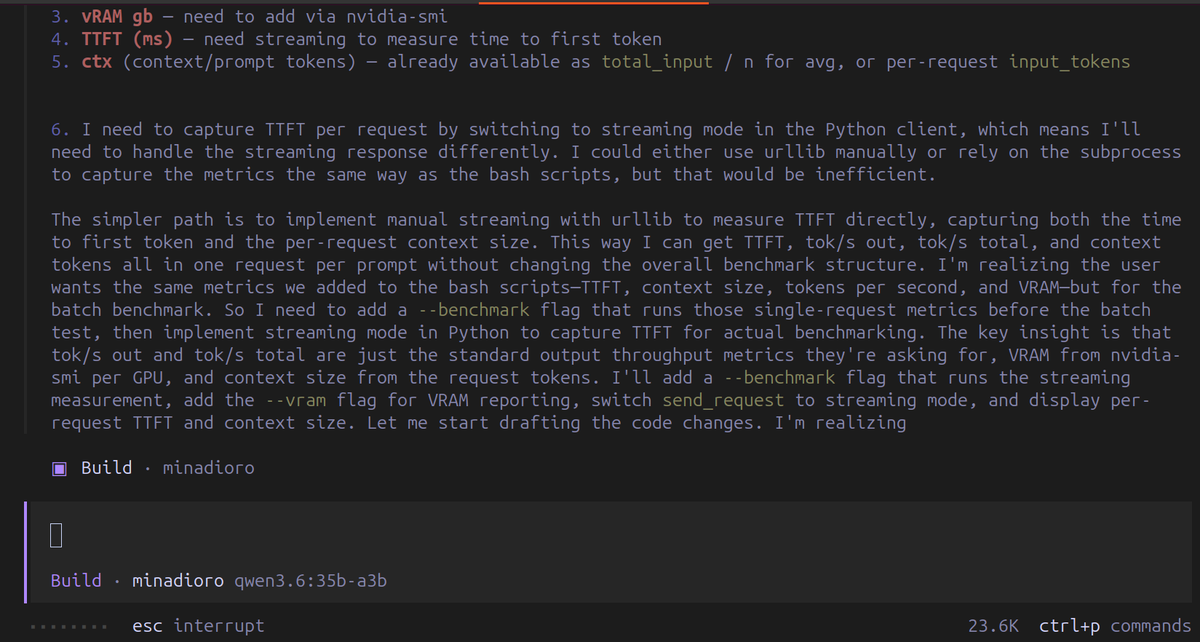
We're in lads I'll leave Opencode on the side for now. I'll be trying Claw Code as the main harness with Qwen3.6 27B (the claude code rust fork from ultraworkers). Opencode is the ultimate opensource tool but definitely not the best one out there. Toolcalls act weird sometimes, app crashes randomly and feels laggy when conversation builds up. Claw Code is cool because you can connect your own local models on it, you just have to add openai/ in front of the model identifier from llama.cpp! export OPENAI_API_KEY="local" export OPENAI_BASE_URL="http://localhost:8080/v1" claw --model openai/Qwen3.6-27B Let's see if it's really better (repo: github.com/ultraworkers/c…)

🚨Alex Jones Just Launched His New Network! Tune In NOW For Sunday Night LIVE! Tucker Is Right When He Says Netanyahu Is Holding Trump Hostage, But It’s Even Worse Than He’s Saying! Alex Jones Is Breaking It Down Live! This Is Must-Watch/Share Information!🚨x.com/i/broadcasts/1…




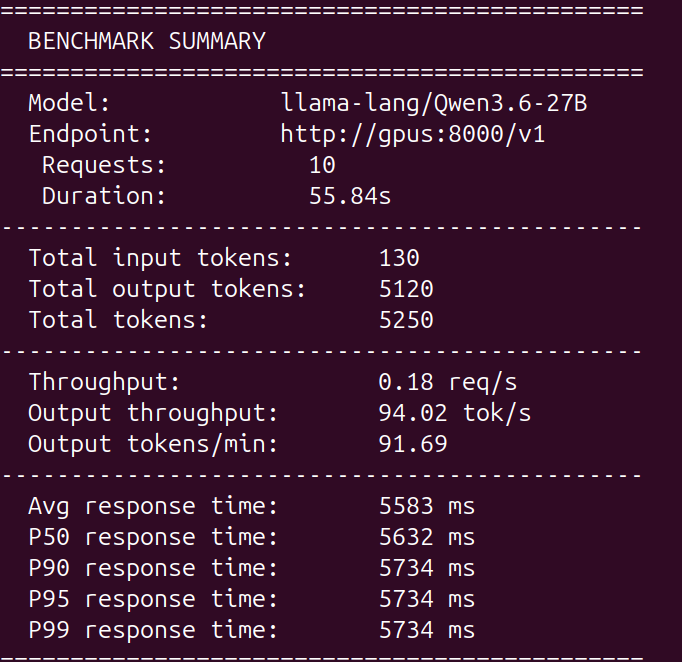
@sudoingX One single prompt made this with Qwen 3.6 27B 2K lines of code and 21.438 tokens