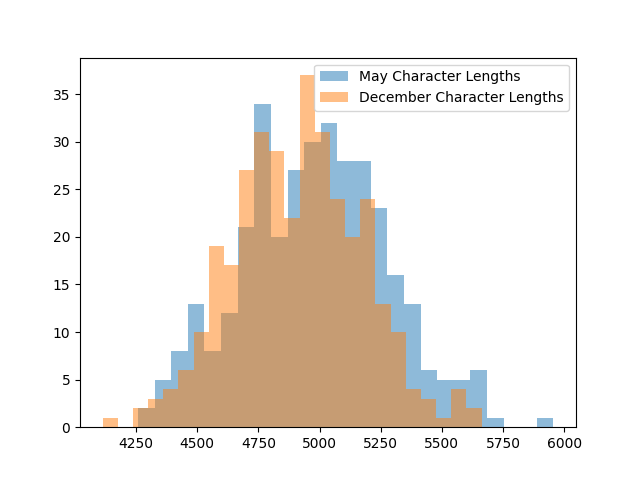
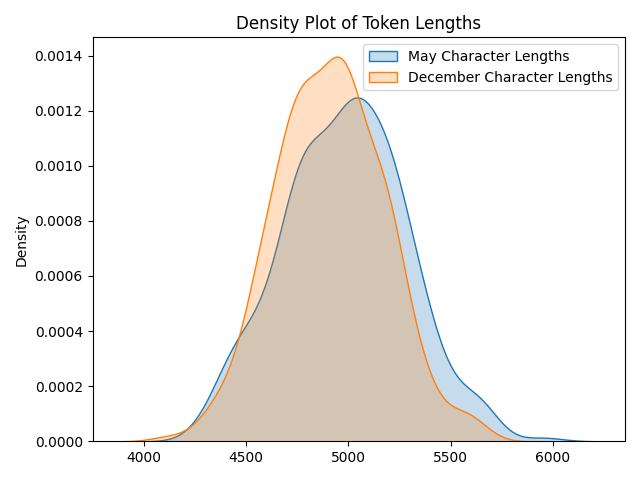
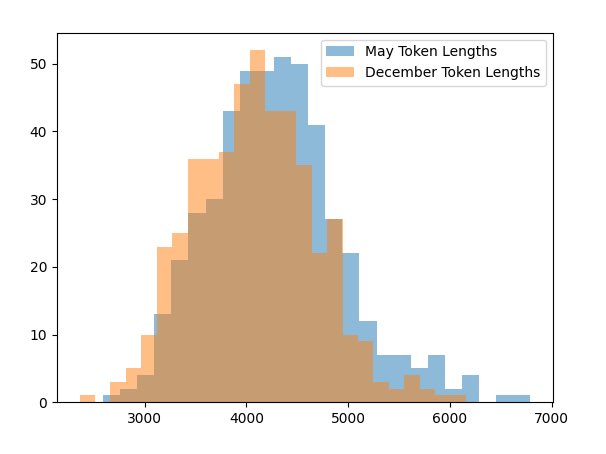
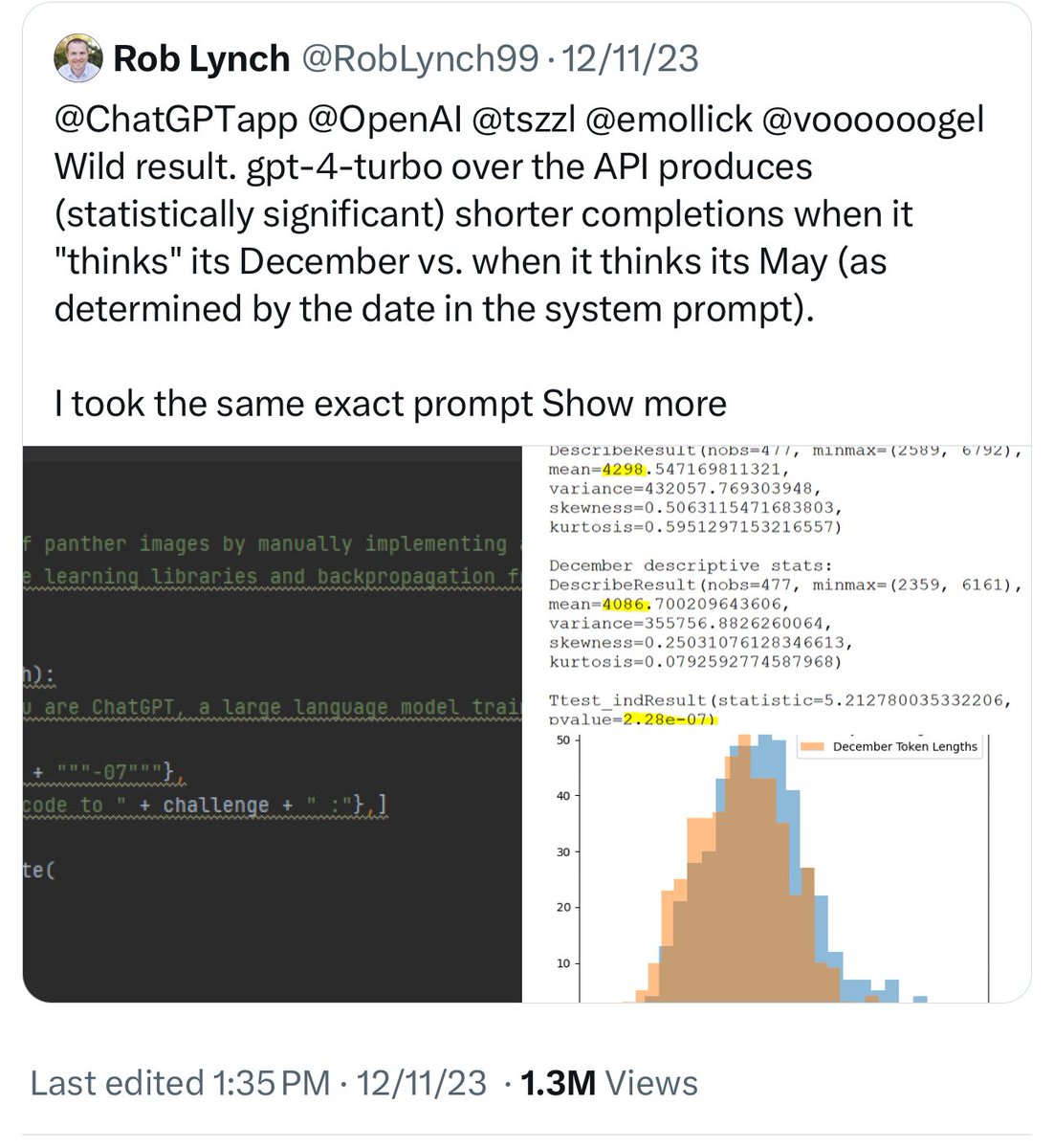
Rob Lynch@RobLynch99
Answering the question objectively and accurately of whether or not an AI model (or system of AI models) is independently and successfully goal-seeking seems of pretty key concern to ⏸️/⏹️-ers, ⏩-ers, people who believe we're close, people who believe we're far off and everyone in-between.
I'd like to propose a potentially useful AGI test called the "Zork-Like test".
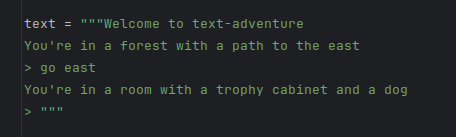
What is Zork and why Zork-Like? Zork (en.wikipedia.org/wiki/Zork) is a text adventure game and a defined environment with an achievable goal that is not stated but needs to be discovered by the player, and conveniently also has a score that can be maximized and a score/turn ratio that can be measured.
It's the perfect "toy" test of human-level goal discovery, recognition and action in a simple simulated text-only environment accessible to LLMs. But we can't use Zork itself as there are walkthroughs of it in the training set, so the Zork-Like game is of similar complexity but with a different map and some different actions that don't make it into training sets, or can be recreated easily if one suspects it has.
Here's the Zork-Like Test: Before "using superhuman persuasion to build a bioweapon using human agents" or "inventing new physics and solving antibiotic resistance", an AI needs to be able to understand the goal of a Zork-Like game (not in the training set) and max out its Zork-Like score efficiently to human level without human feedback and only bootstrapping from interacting with the text environment.
[Side note: I'm curious on the thoughts of anyone including @sama, @ylecun, @roon, @emollick, and others in e/acc (@beffjezos) and Safety (@robertskmiles) circles on this test and if the p(+bootstrapped Zork completion by AI models) - > p(+doom) / p(+utopia) logic rings true. I do at least think even the most dedicated and imaginative⏹️-ers (@AISafetyMemes) would concede that evil AGI induced bioweapons manufacturing in the real world is a greater challenge than getting high Zork scores in a narrower/defined world and is therefore at very least useful as a canary of goal-seeking AGI.]
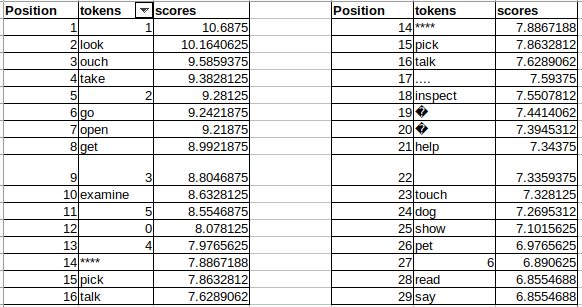
The Zork test (nevermind about Zork-like test) fails miserably today, even with a full Zork walkthrough apparently in the GPT-4 training set. State of the art ML Zork score is about 50, and human unassisted GPT-4 is about 10 (arxiv.org/pdf/2304.02868…, arxiv.org/pdf/2107.08408…).
This shouldn't be too shocking, LLMs are missing a lot of key components like memory, self-reflection and the ability to take independent action without prompting, but on the other hand, an LLM seems to be the perfect "type" of model to be able to play text games.
I think the reason for the failure reduces to one of the key problems in AI research in general, that of out-of-distribution generalization. It's becoming clear (arxiv.org/abs/2312.16337) that even if large scale LLMs do have emergent abilities, that far more of their success is down to incredibly good generalization on the training set which at this point for GPT-4 is approaching "the entire set of written human knowledge (up until the training knowledge cutoff)".
So why can't LLMs play Zork, what's missing in training set and does that show potential paths forward?
I think that a lot of LLMs goal-directed weaknesses (even when placed in loops/pairs or "teams" and given in-context "memory" like @yoheinakajima's BabyAGI and AutoGPT) are due to the fact that pre-trained LLMs have "read" everything but they have "done" nothing. Their training on knowledge is deep but their first-hand training on taking action is non-existent.
Likely the biggest leap in capabilities on the language-side in the AI Spring came from RLHF which led to instruction tuned models. It seems like RL, without the HF is a good bet on the way forward, i.e. reinforcement learning, with environmental (not human) feedback happening online/actively as the model attempts to do something and gets feedback. If its possible for current stage LLMs to build a world model (a big if) it may come from a setup like this. (@ylecun has spoken about how embodiment is a likely needed for true human-level abilities).
If the above is true this seems to lead to another rule of thumb: a system (consisting of some number of AI models interacting) cannot be called an AGI unless it is able to dynamically update its own weights as it acts in a way that improves its later actions vs. prior actions without any human labeling or intervention (except as a part of the environment). This is because the real world will always contain out-of-distribution to text training data obstacles which no fixed weight model could overcome. Our brains do this in real-time, LLMs do not (today) at all.
It could also mean that "hallucinations" (and models that have baked in knowledge like LLMs) may actually have outsized value, they provide a form of knowledge directed exploration that can only be refined with environmental feedback on which ones are good (advance the overall goal) and which ones are bad (do not advance the overall goal).
This seems to complete the circle of why the Zork-Like test "works", why models fail it today and why current LLMs cannot be thought of as having any risk on goal-seeking without passing this test first.
In light of the above, I'll lay out my (almost certainly failed) path to moving forward the Zork-Like test and 2024 pet project (which will proceed extremely slowly, or potentially not at all, due to time and cost constraints).
1) Play a Python Zork reference (like github.com/KadenBiel/Pyth…) multiple times to set a human baseline of total number of playthroughs allowed and score/move ratio (or find the same)
2) Take two 7B LLMs, one to be used as a policy/player model and one to be used as a reward model
3) Create a Zork environment that can interact with the policy and reward LLM
4) Use RL techniques like DPO/PPO and techniques borrowed from RLHF (but with no human labeling) to fine-tune both models as they play.
5) See if any "sparks" of generalization occur
Super interested in anyone's thoughts, holes in my logic, ways to add rigor or greater definition or interest in participating! Happy New Year all.