PDR_Founder retweetledi

Federal officials say the FBI is now investigating the attack of a Turning Point USA reporter outside the Whipple Building during an anti-ICE rally on Saturday. fox9.com/news/whipple-p…
English
PDR_Founder
162 posts


@RobVoigt
Founder of PerfectDocRoot Building governance-first systems for structured, inspectable AI behavior Public Beta → https://t.co/HQ9mjmdqZg






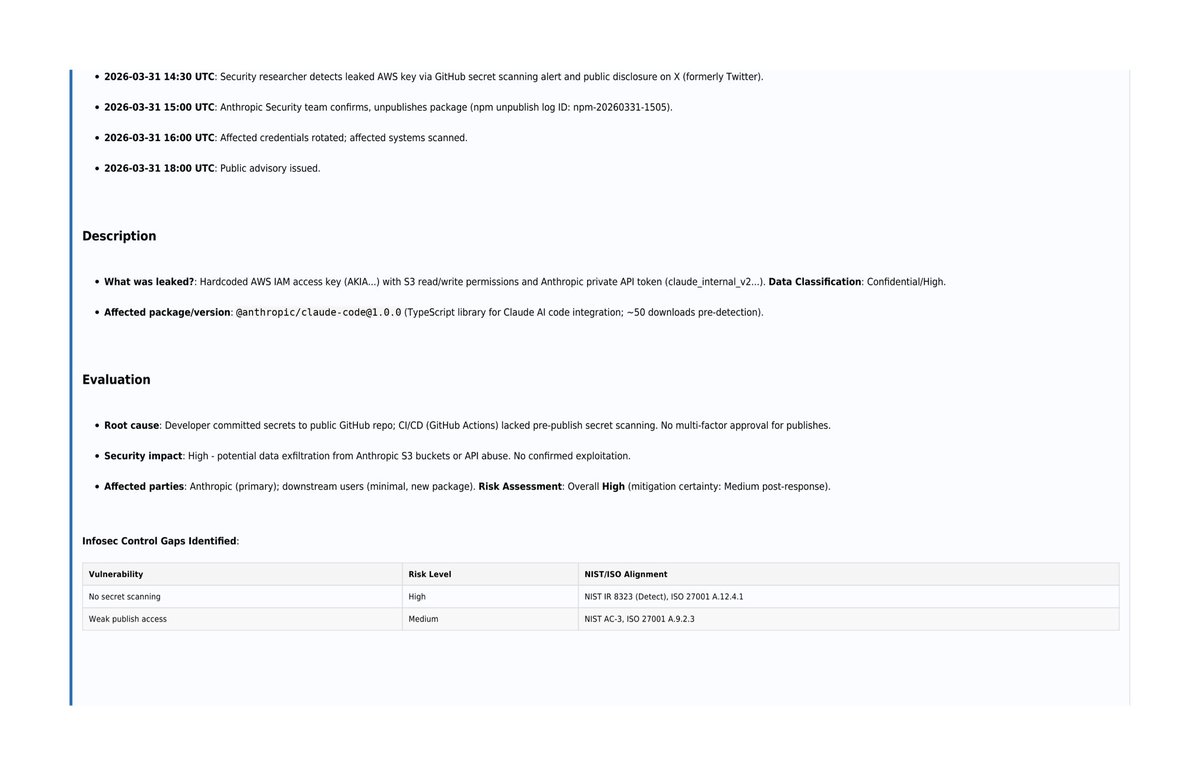


The HHS DOGE team has expanded the Defend the Spend system to require all ACF payments across America to be justified. Since March 2025, Defend the Spend has applied only to HHS discretionary payments, which did not include these ACF payments. Over the coming days, we will expand the system to support itemized receipts and photographic evidence, and make all data/receipts, where possible, available to the public.









