
Rock
38 posts

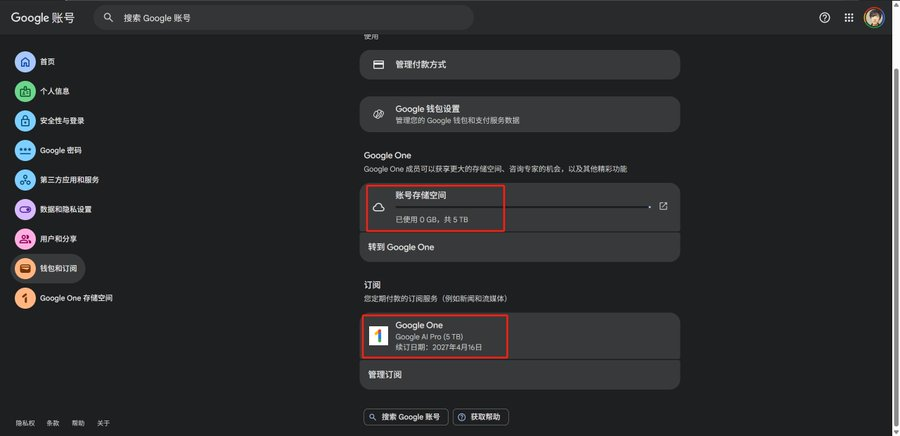
今晚先带来龙哥承诺给你们的攻略7:
白嫖Google one(Google AI Pro 5T)一年期的会员。
战果见截图哈,先清晰告诉你们这个产品包含哪些东东:
1. gemini 3.1 pro:超强的文本和推理LLM,龙哥在openclaw里的主力(顺便提一嘴,我之前分享过GCP里能白嫖到1300刀的赠金,利用Vertex AI API可以几乎无限制调用Google家的所有大模型哈,有兴趣的同学可以去看看);
2. Nano banana pro:大家耳熟能详的图片生成大模型,能力超强;
3. Veo 3.1:Google家的视频生成大模型;
4. Lyria 3:Google家的音乐生成模型,在音乐生成领域评分中也经常排名前列;
5. Google one的网盘:包含google drive,用来存你的各种文档;包含google相册,这东西用过的都知道,它不仅仅是帮你同步备份照片这么简单,里面内置了AI图片编辑/自动分类/人脸识别/还有它们家超强的回忆流功能。然后你搞完这个就拥有5T容量了,根本用不完,哈哈
好,下面正式来讲一下这东西到底怎么搞到手👇👇👇
中文

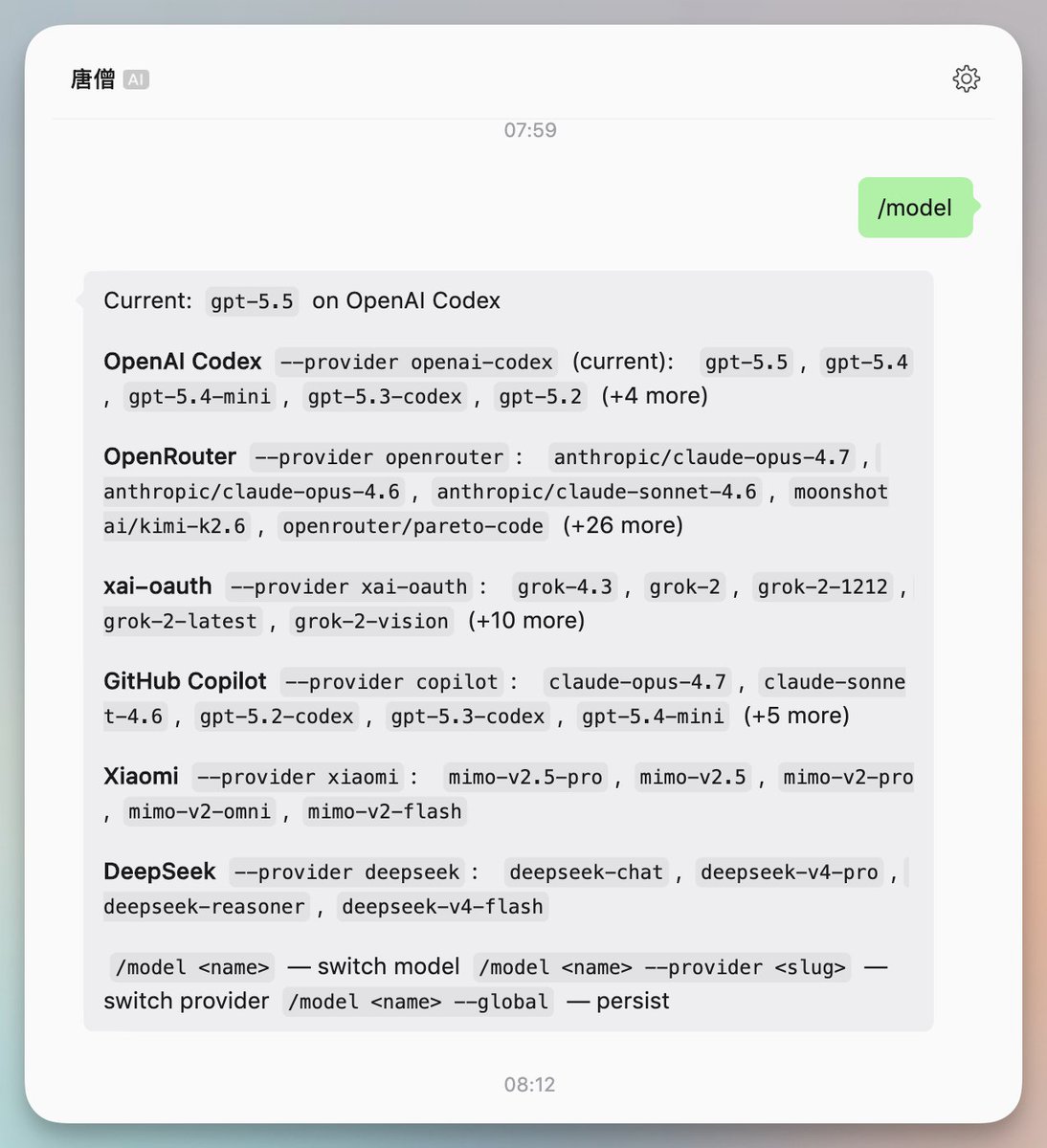
Hermes 目前值得配置的国内外模型:
1. 订阅ChatGPT plus或以上,用 OpenAI Codex 的Auth 配置 gpt-5.5
2. xAI如果买了Premium,可以配置 grok-4.3
3. 谷歌 Gemini 订阅或免费账号,配置 gemini-3.1-pro-preview 和 gemini-3-flash-preview
4. DeepSeek 官网 API 配置 deepseek-v4-pro 和 deepseek-v4-flash
5. 智谱官网 API 配置 glm-5.1 和 glm-5-turbo
6. Kimi 官网 API 或开发套餐配置 kimi-k2.6
7. 小米官网 API或开发套餐,配置 mimo-v2.5-pro
配置后,Hermes可跟机器人对话切换模型,指令如下:
/model gpt-5.5 --provider openai-codex
/model grok-4.3 --provider xai-oauth
/model gemini-3.1-pro-preview --provider google-gemini-cli
/model kimi-k2.6 --provider kimi-coding-cn
/model deepseek-v4-pro --provider deepseek
/model mimo-v2.5-pro —provider xiaomi
中文

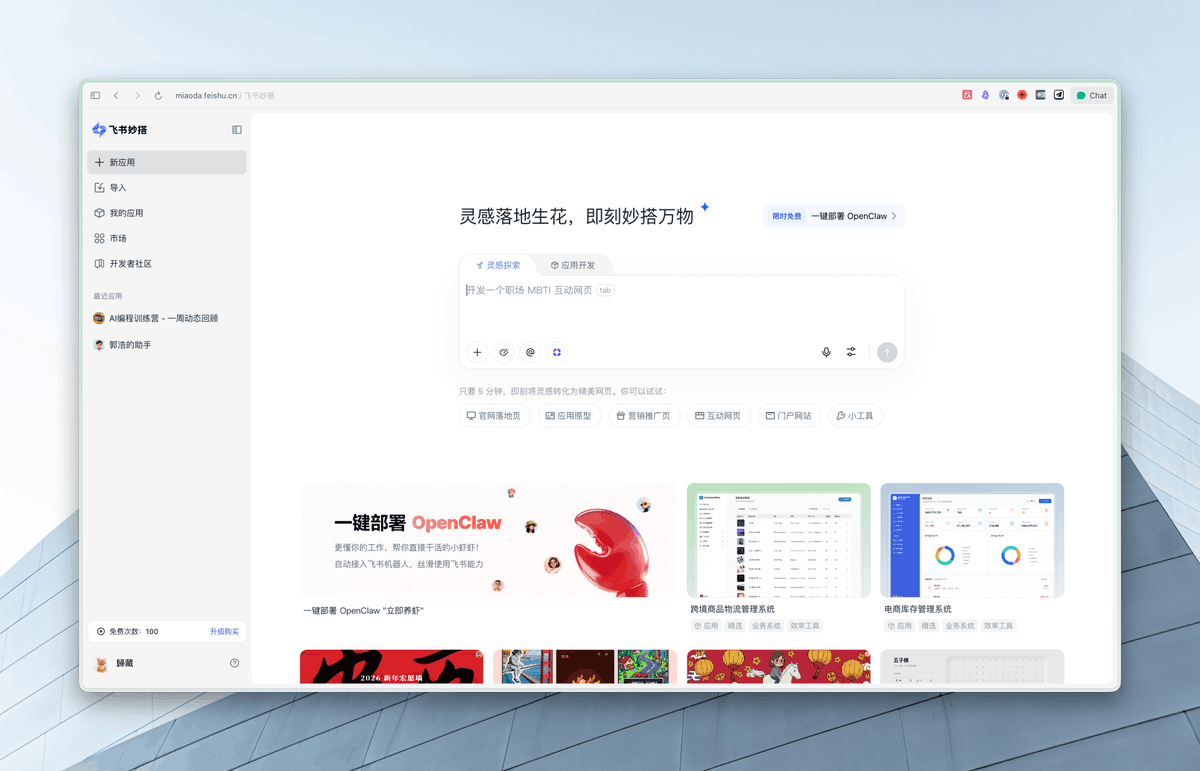
飞书做了一个超安全且功能更强大的龙虾!
前段时间,龙虾爆火的时候,飞书因为健全的生态和开放的接入方式,成为了大家国内接入龙虾的首选 IM 平台。
但是毕竟 龙虾 有自己的体系,还有很多安全性问题,所以导致飞书服务的 to B 企业其实很多时候很难自己部署,或者是不敢自己部署。
这次飞书直接把他们的 aily 升级了,升级成了一个更安全、跟飞书契合度更高,而且更懂你的企业和你的龙虾。
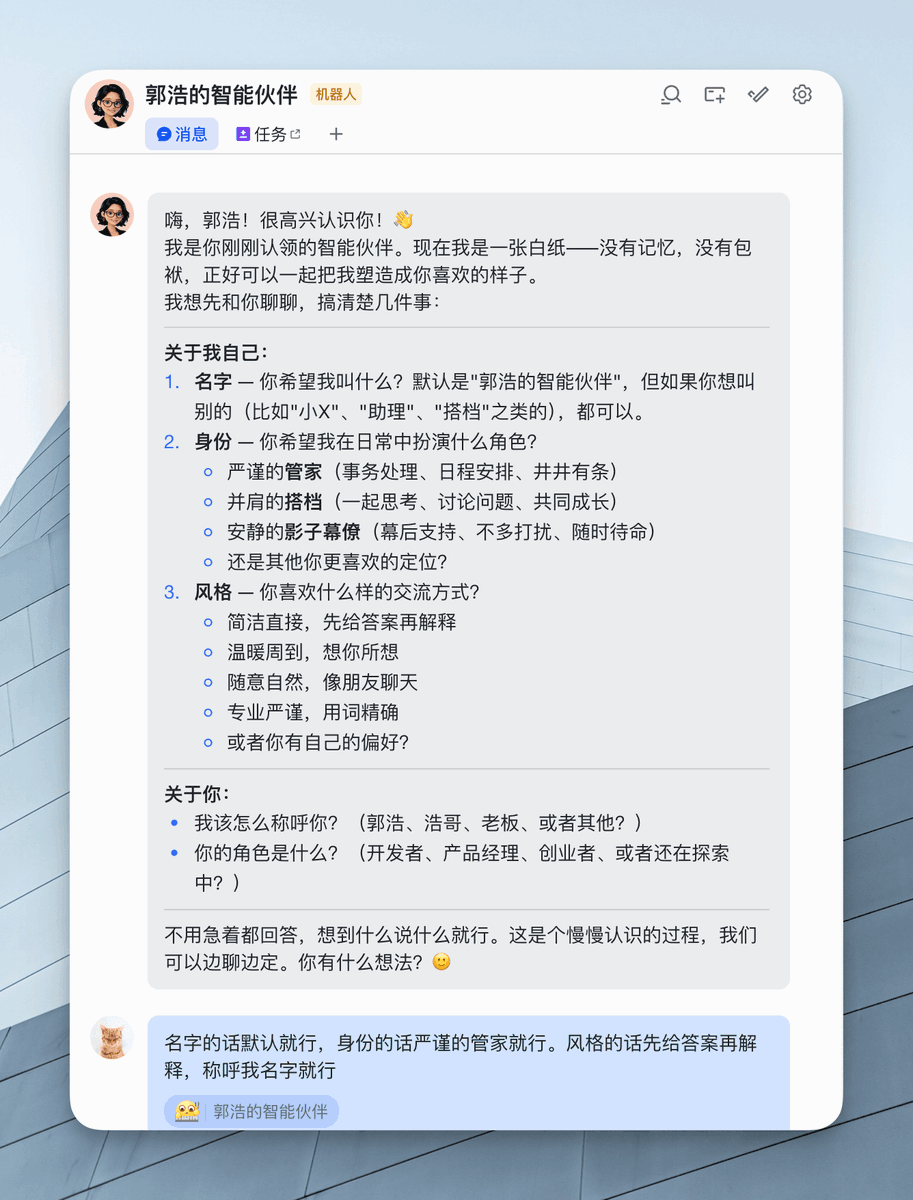
你可以一键配置,随后它会直接生成一个联系人作为你的助手。你可以直接让他进行回复,或者在飞书中跟他聊天、给他安排任务。
他能读取你飞书里的所有信息,并帮你完成任务。此外,他还可以调用一些常见工具,甚至获取飞书之外的信息。
而且可以自定义 Skills,比如说:你的日报、PPT、安排日程,这些都可以让它去帮你做。
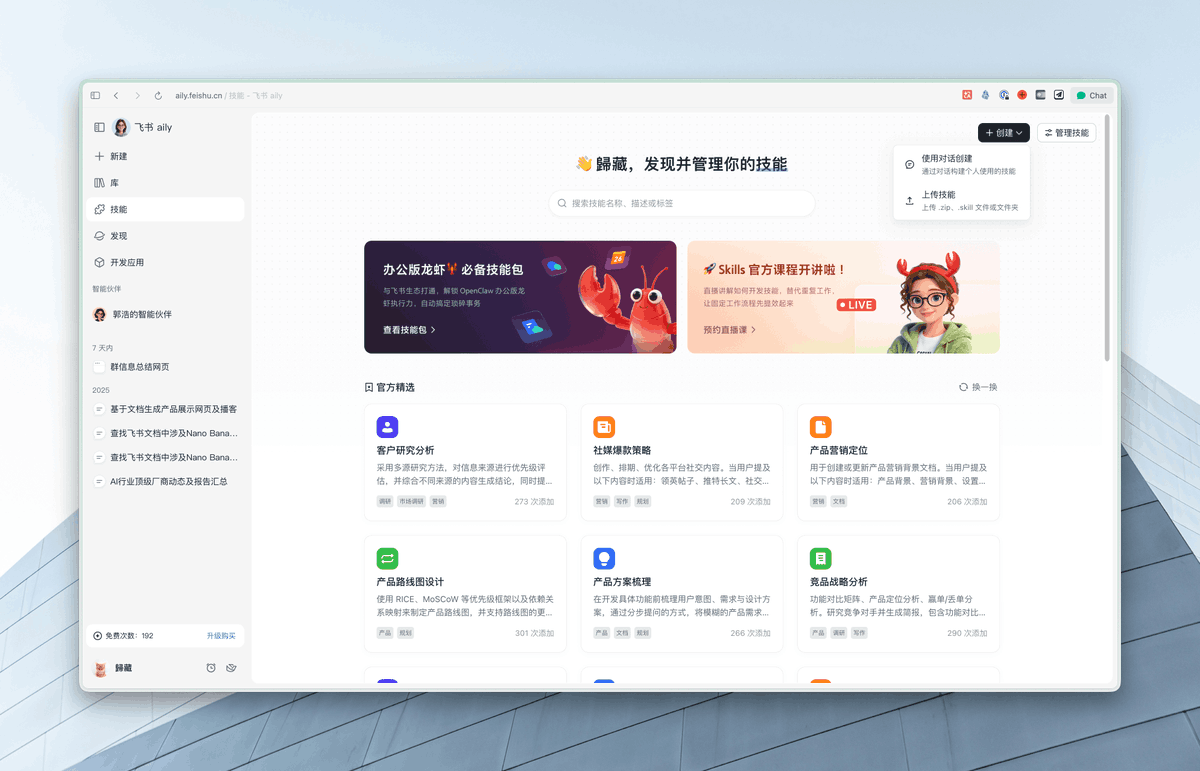
更强的是,他们还有一个专业版的 Aily,在网页上使用,自带了超级多的 Skills。
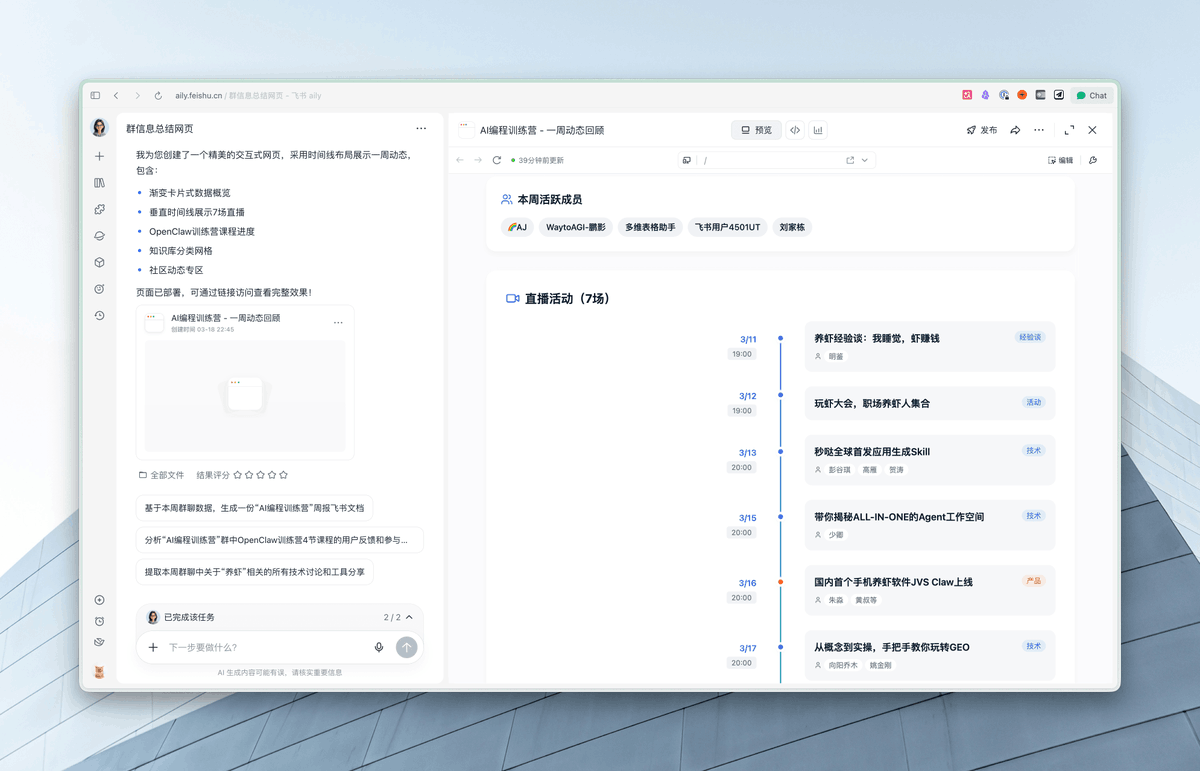
比如我这里就让他查找了一下对应的一个群,然后让他总结群里的信息,同时写了一个网页可视化的展示这些信息。
这个对于我们日常的企业管理和一些群的维护是非常好用的,而且还可以自动发送到比如说群里,对吧?
同时,它支持更多超长的指令和复杂任务拆解,以及定时任务。他还给这个 Aily 配备了 Agent 电脑,支持更稳定的调用。
我们都知道龙虾强就强在它丰富的生态,也就是那些 Skills。
这次除了官方内置的大量 Skills 以外,你还可以通过 aily 专业版自己创建 Skills,同时支持上传以前自己制作的 Skills。
这个功能非常厉害,可以将很多个人流程直接落地:
比如我之前做的一些“去 AI 味儿”的指令
还有一些视频剪辑或文本生成的 Skills
你完全可以将自己的工作流落地到 Skills 里,Agent 的创建门槛已经变得非常低了。
目前你可以飞书搜索 Aily,就可以开通 Aily 助手;
同时去网页版(aily.feishu. cn)可以使用专业版的 Aily,都有免费额度,可以去玩玩,非常好玩。
中文

在 Claude Code 里安装 claude-mem,三步搞定。
note.mowen.cn/detail/5bJGym-…
claude-mem 是一个专门为 Claude Code 打造的持久化记忆系统,它能做事有这么多:
1、自动记录每次会话中的代码操作、工具调用和对话内容
2、智能压缩生成语义摘要,为下次会话做准备
3、按需检索在新会话中自动注入相关上下文
4、Web 界面提供 http://localhost:37777 查看和管理记忆
也就是说 claude-mem 相当于给 CC 增加了一个外挂的大脑,记得全,还能省 Token。很多人问咋装,简单写了个墨问 note。
中文

OpenCLI v0.7.3 发布!🎉
感觉真的好多人帮我们提 PR 支持各种网站,说明大家真的是有在使用!感谢!
另外大家如果在使用的各种网站也可以提 PR一起帮助大家.
更新 about
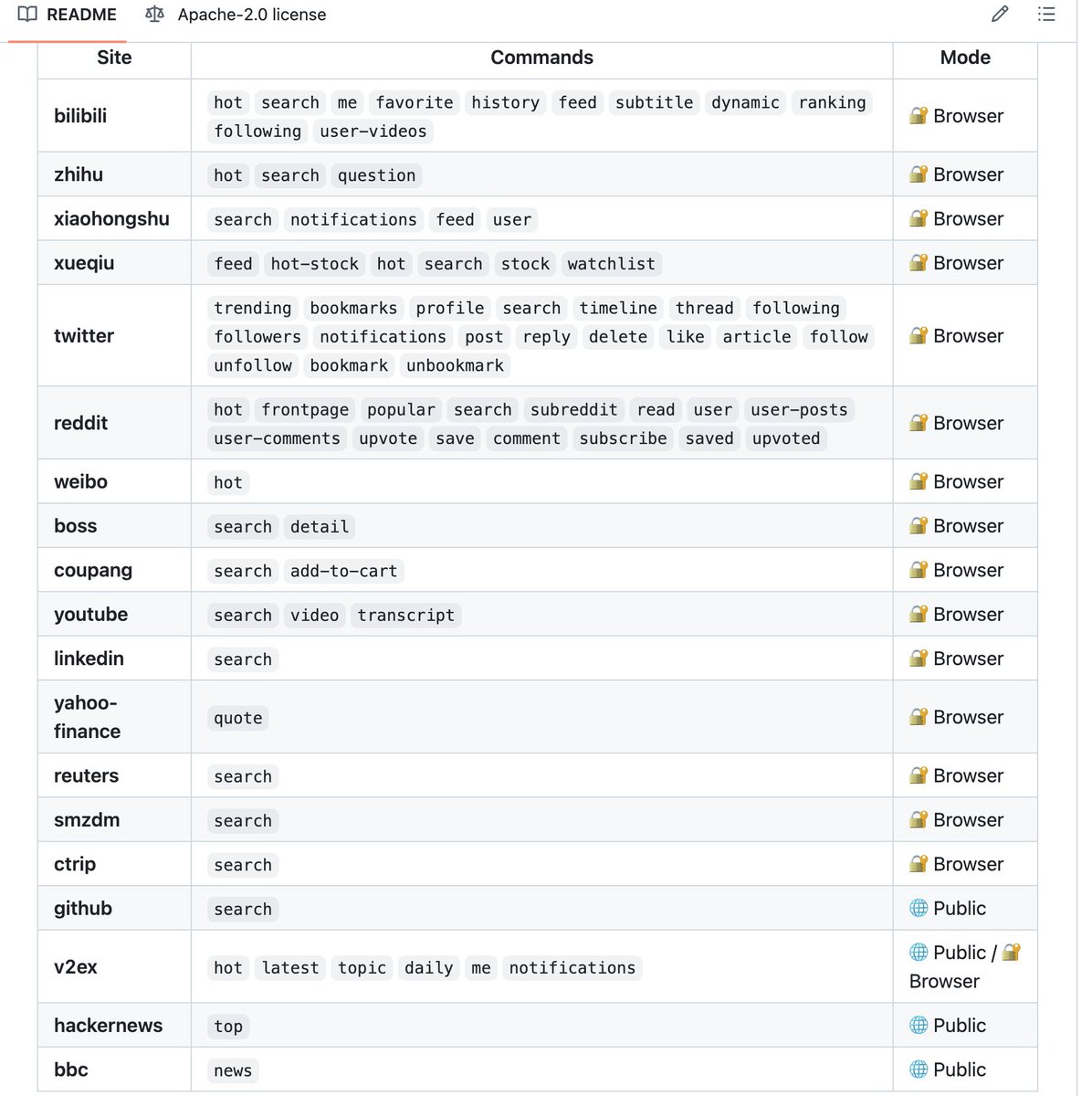
新平台 & 20+ 新命令
• LinkedIn 职位搜索
• YouTube 视频元数据 + 字幕转录(支持中日韩语言、说话人识别)
• Twitter 长文/关注/收藏等 6 个新命令
• Reddit 11 个新 adapter + 评论树
• BOSS直聘职位详情
基础设施升级
• 真实 Chrome E2E 测试
• 页面快照智能过滤
github.com/jackwener/open…
中文




我把 Andrej Karpathy 推荐的长文章 RSS 订阅源,整理成了一个 SKILL。
一共有 90 个源,更新也不多,但是质量都是经过 AK 把关的,我又额外添加了评分机制,会把每次新更新进行 1 - 10 打分,只输出 7 分以上的文章地址和推荐语。
安装命令:npx skills add rookie-ricardo/erduo-skills --skill ak-rss-digest
github:github.com/rookie-ricardo…

中文
OpenCLI v0.6.0 发布了 🎉欢迎关注!
Contributor的数量马上就要破 10 啦!
新增 opencli setup & docter 命令,交互式 TUI 一键配置 Playwright MCP token 到所有 AI coding 工具(Claude Code、Gemini CLI、Cursor、Codex、Antigravity 等)。
还加了从 Chrome extension 自动发现 token 的能力,不用再手动复制粘贴了。doctor 命令也加了彩色输出和智能跳过。
大规模代码去重:提取了 interceptor、version、constants 等共享模块,消除了 3 处重复的 XHR/Fetch interceptor 和 新增了很多测试
当然各种各样的修复 bug 和 网页关闭等打磨都不说了
很惊喜的是,社区里面甚至有韩国人贡献了 Coupang 搜索和加购
github.com/jackwener/open…
中文

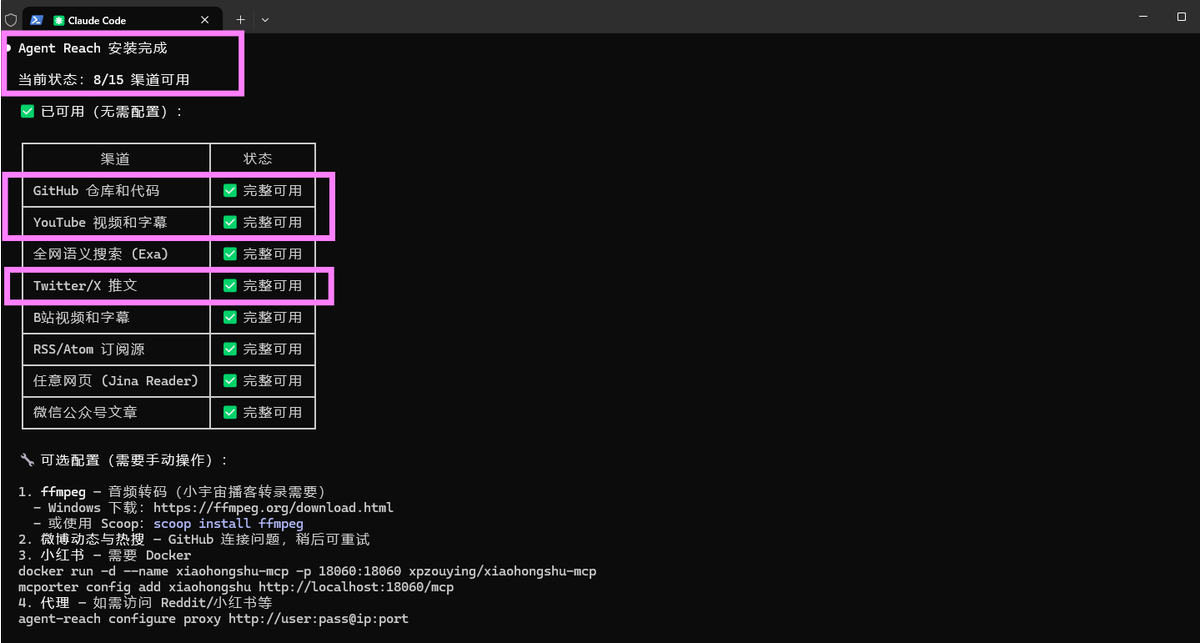
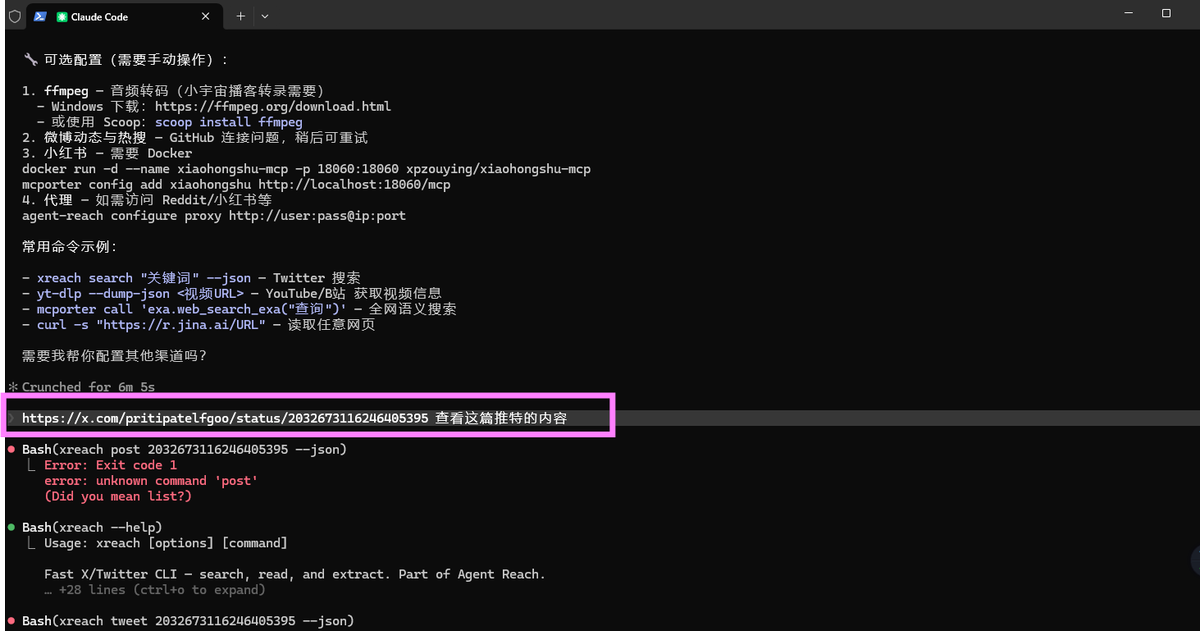
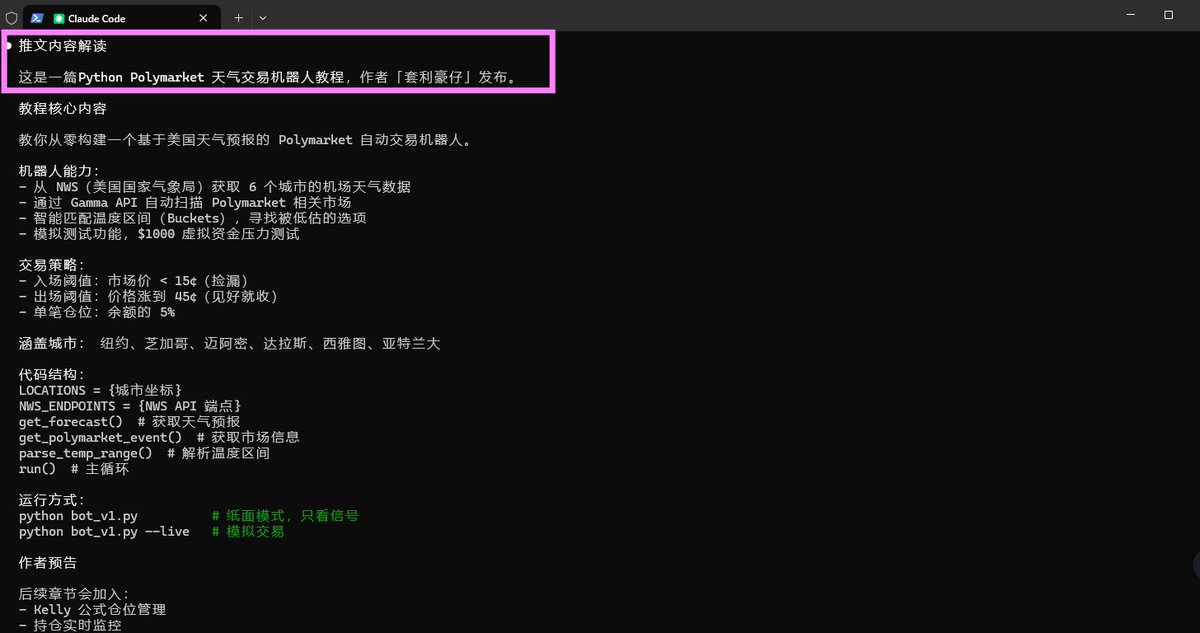
只需要几分钟,你就能有一个地表最强的信息整合器。
给 OpenClaw / claude code 装上 Agent-Reach,就能读推特、搜 Reddit、看 YouTube、刷小红书……
以前你想让 Agent 做的事:
"帮我看看这个 YouTube 教程讲了什么"
"帮我搜一下推特上大家怎么评价这个产品"
"去 Reddit 上看看有没有人遇到过同样的 bug"
"帮我看看小红书上这个品的口碑"
"B 站上有个技术视频,帮我总结一下"
实际发生的事:
看不了,拿不到字幕
搜不了,Twitter API 要付费
403 被封,服务器 IP 被拒
打不开,必须登录才能看
连不上,海外/服务器 IP 被屏蔽
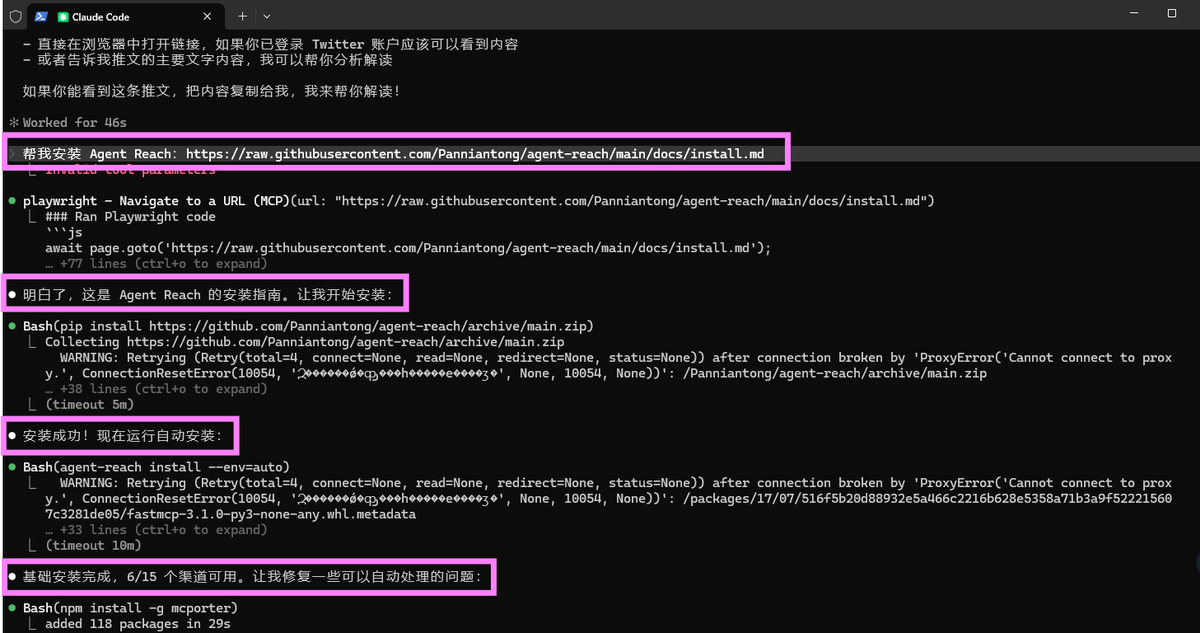
项目地址:https://github点com/Panniantong/Agent-Reach
安装命令:帮我安装 Agent Reach:https://raw.githubusercontent点com/Panniantong/agent-reach/main/docs/install.md
中文
CLI 宇宙继续高产 ing,weibo CLI来了!
在终端里刷微博热搜、热门时间线、用户主页和评论。
我的社交平台 CLI 全家桶之一
全家桶:twitter-cli / bilibili-cli / xiaohongshu-cli / discord-cli / tg-cli/ ....
后面会去做一些新闻源的 CLI
方便我自己开发投资使用
github.com/jackwener/weib…
中文

10分钟用Obsidian + OpenClaw重构AI知识管理体系👇
我们有幸邀请到了AI自媒体博主@aiwarts 来WaytoAGI分享!他刚完成自己知识体系的完整重构,来分享整套方法。
1️⃣为什么选 Obsidian
Obsidian 的底层是本地 Markdown 文件,AI Agent 直接读写,不需要 API、不需要授权。
Notion、飞书的数据在云端,AI 每次操作都要走 API,慢、贵、有限制,Obsidian 没有这些问题。
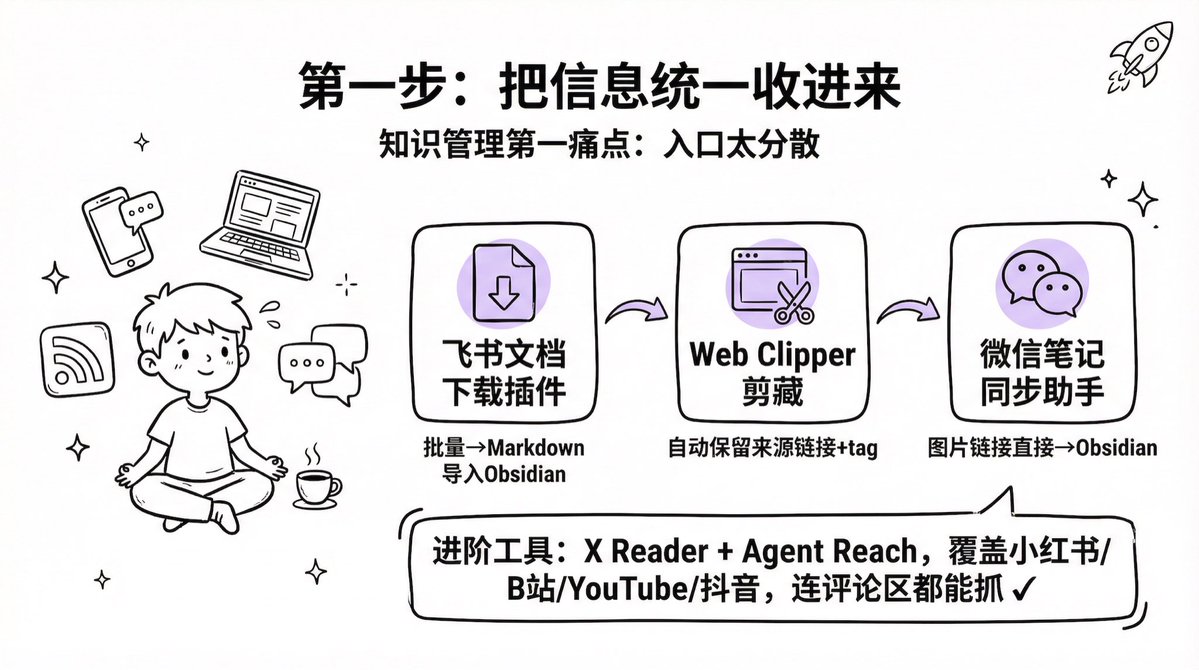
2️⃣第一步:统一信息入口
卡尔每天处理五六千条信息,分散在各处。他用三个插件解决入库问题:
飞书文档下载插件 — 批量转成 Markdown 导入
Obsidian Web Clipper — 抓网页,自动保留来源和 tag
微信笔记同步助手 — 微信内容直接同步进来
3️⃣视频和社交平台内容另有方案
X Reader 和 Agent Reach 可以覆盖小红书、公众号、B站、YouTube、抖音、GitHub,连评论区都能抓。
没看过的视频先存链接,确认值得看再用 AI 生成摘要收录,避免无效处理。
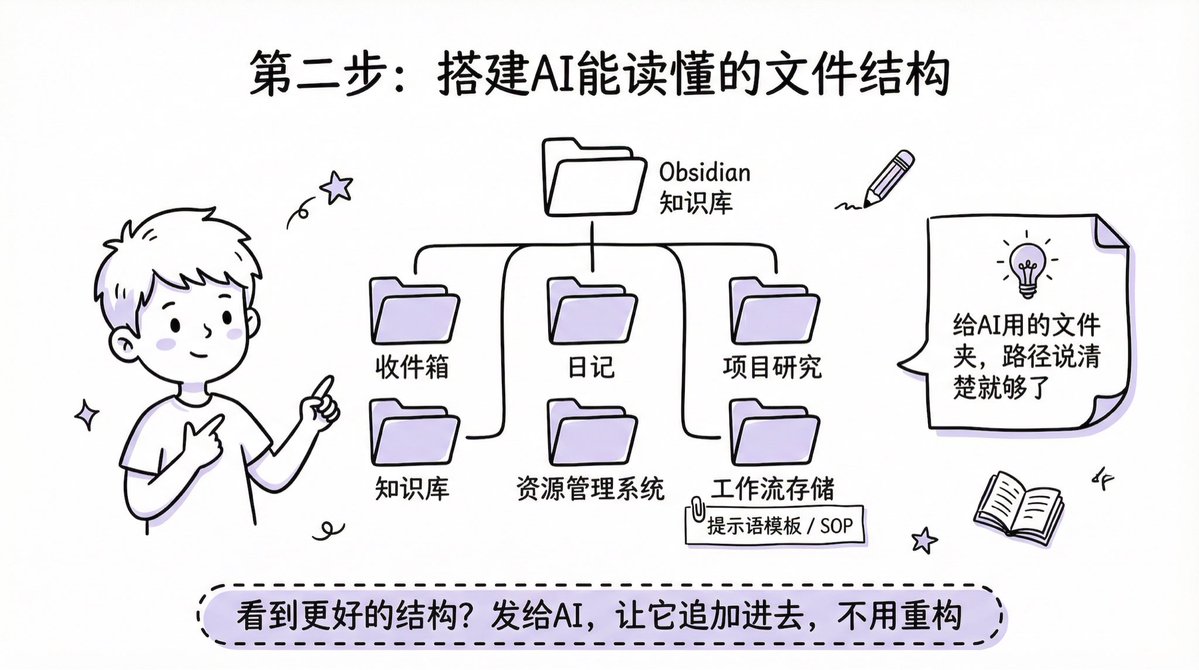
4️⃣第二步:搭 AI 能读懂的文件结构
常见误区:把文件夹做得"对人友好",但 AI 不在乎好不好看,只要路径清晰就够。
推荐起点:GitHub 上有中文版 Obsidian 初始结构项目,包含收件箱、日记、项目研究、知识库、资源管理。卡尔在此基础上加了"工作流存储"目录,放提示词模板和各平台发布 SOP。
看到更好的结构不需要重构,把链接发给 AI,让它把缺少的部分追加进去就行。
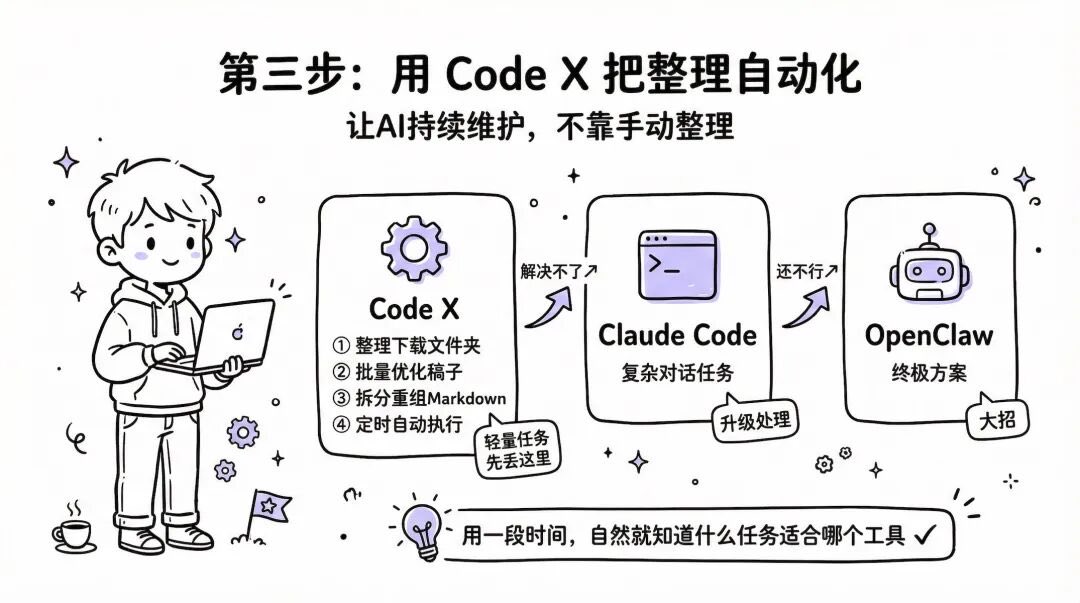
5️⃣第三步:用 CodeX 自动维护文件
CodeX 默认绑定目录,直接连接 Obsidian 文件夹,适合管理文件结构。
卡尔每天用它做:整理下载文件夹、批量优化稿件、拆分重组 Markdown、设置定时任务。
分工逻辑:轻量任务先给 CodeX,解决不了交 Claude Code,再解决不了才上 OpenClaw。
6️⃣进阶:用 OpenClaw 让知识库主动运转
OpenClaw 支持心跳机制和 Cron,可以让 Agent 按计划自动扫描知识库、整理新增内容、发送日报,不需要手动触发。
接入方式推荐飞书或 Discord。飞书可以配置多个 OpenClaw 应用共享同一套记忆体系;Discord 有频道隔离,可以在后台同时跑多个任务。
在 OpenClaw 的 agents 配置文件里写清楚哪些内容归到哪个目录,新信息进来就自动分类,不需要二次整理。
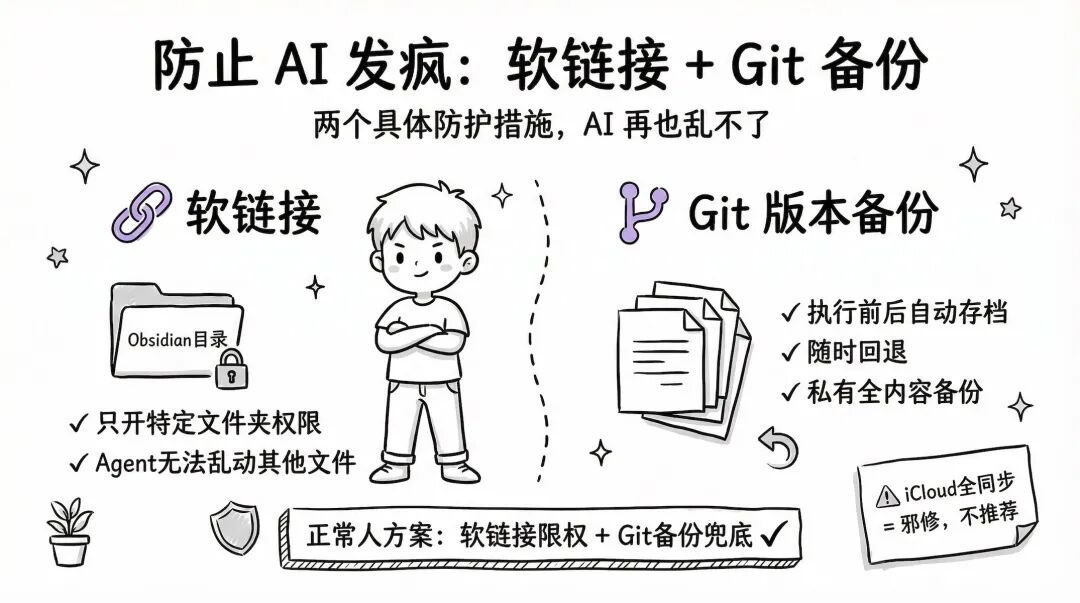
7️⃣防止 AI 误操作的两个措施
软链接 — 只开放 Obsidian 特定文件夹的权限,Agent 无法访问其他文件
Git 版本备份 — Code X 在执行命令前后自动存版本,随时可以回退
卡尔的邪修做法:把本地除 Download 文件夹外的所有内容都同步到了 iCloud 2T
8️⃣一个实用细节:上下文健康检测
和 Claude 对话到五六十轮后,它的"遗忘"会明显加速,之前设定的偏好和技能会悄悄丢失。
检测方法:设一个确认指令,能回复关键词说明上下文还在,不行就开新对话。
真正难的不是安装 Obsidian,是想清楚你要管理什么,然后让 AI 读懂你的文件夹逻辑。
#通往AGI之路 #WaytoAGI #OpenClaw #obisidan #claudecode #CodeX #AI知识管理 #知识体系
中文

养小龙虾兄弟盟,强烈推荐你们安装这个 skill:Agent-Reach
你现在用 OpenClaw 这种 AI Agent,
它脑子很强,但眼睛基本是瞎的。
让它:
- 看一下 YouTube 教程讲了啥 —— 看不了
- 搜 Twitter 上大家怎么评价 —— API 要钱
- 去 Reddit 找同类 bug —— 403
- 看 小红书 口碑 —— 必须登录
- 总结 哔哩哔哩 视频 —— 服务器常被拦
- 读 GitHub 仓库和 Issue —— 认证一堆配置
不是做不到,是太麻烦。
每个平台一套规则,
要权限、要登录、要处理反爬、要清洗 HTML。
你折腾半天,
只是为了让 Agent 能看到网页。
而现在你只需要跟你的小龙虾说一句:
帮我安装 Agent Reach
剩下的,它自己会搞定。
中文

Obsidian 1.12 加了命令行工具,对用 AI 的人来说是大升级。
现在很多人把 Obsidian 当 AI 的外部记忆层——笔记、决策记录、踩坑经验都沉淀在 vault 里,AI 需要时直接读取。我自己就是这么用的:Claude Code 读写 vault,等于跨会话的长期记忆。
升级方法:更新到 1.12 → 设置 → 通用 → 打开命令行工具。
试了一下,两个直观感受:
一是省 token。以前 AI 要了解笔记库概况,得遍历所有文件(45KB);现在一行命令,351 字节。看一篇笔记结构,以前读整个文件(63KB),现在只返回标题大纲(5KB)。查孤儿笔记、死链,以前得自己写脚本,现在一行命令秒出。
二是多了一层图谱检索。向量搜索找的是"内容相似"的笔记,命令行的反向链接找的是"你当初主动建立的知识连接"——这两种"相关"不一样。AI 搜到一篇笔记后,顺着反向链接拉出关联知识,这是传统搜索做不到的。
Obsidian 管存储,AI 管智能,命令行把两边接上了。

Obsidian@obsdmd
Obsidian 1.12 is now available to everyone! - Obsidian CLI - Bases search - Image resizing - Automatically clean up unused images - Better copy/paste into rich text apps like Google Docs - Native iOS share sheet
中文

筛选优质信息的能力,在 2026 年,变得无比昂贵。
强烈感受:我情愿每天读几篇高质量文章5678 遍,也不愿看铺天盖地 ai slop 一眼。
高质量文章,会丰富和滋养你的大脑。ai slop,只会让你的大脑蒙上多一层脑雾。
如果觉得逛推时脑子反而更雾了,应该停下来,好好思考一个问题:我是如何判断信息质量的,又是如何筛选信息的?
---
来,在评论区分享你筛选信息的经验和技巧。
我先抛砖引玉:
1、阅读一定要记笔记(logseq、readwise reader)
2、先 llm 总结(用符合认知原理的ai 阅读 prompt,而不是 summary);然后筛选出高品质文章,带着问题,围绕关键词阅读原文;
3、建立自己的阅读 database(针对投资、ai 学习等 high value use case)
中文

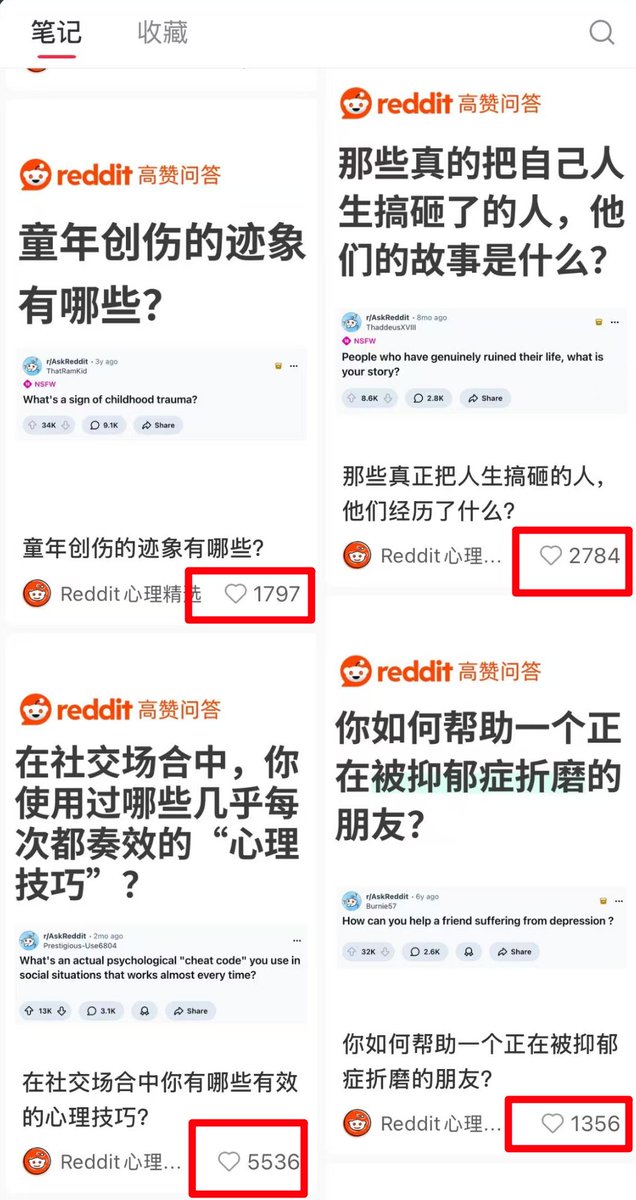
Reddit 只是个论坛?在聪明人眼里,是免费的印钞机
有个误区,就是觉得非得是专家才能吃内容这碗饭
看到这个,说实话,这模式很土,但不得不服人家的效率
简单说,就是情绪搬运工
哪怕是个心理学小白,只要会用翻译软件,这事就能跑通,咱们还在那纠结标题文采的时候,人家直接在Reddit 的心理、情感板块,找那些几千赞的真实人性故事或者怪诞心理冷知识
这思路为什么可以?
原材料够好:Reddit 上的吐槽,尺度大、角度清奇,对读者来说这是新鲜的情绪罐头
降维打击:把英文的爆款,搬到中文,这是经典的时间差和信息差
变现标准:没卖课,也没搞咨询,卖的是心理测试
这就像卖水,不需要陪聊,用户做完题,自动出报告,收个几块十几块,睡后收入
思路草图:
第一步:去 Reddit 搜 r/psychology 或 r/AskReddit,找高赞贴
第二步:扔给 AI 工具,翻译成那种闺蜜夜聊的语气
第三步:置顶挂一个心理测评链接(现在很多支持分销)
咱们很多时候赚不到钱,不是因为不够努力,是因为太想证明自己,而忘了用户其实只想要一个宣泄的出口,或者一面照镜子
中文