
@iceman00008 @vultisig Very very cool… just another breakthrough like this for the vault share management and it becomes the absolute best wallet out there.
English
RSGB / ⚡️
1.3K posts



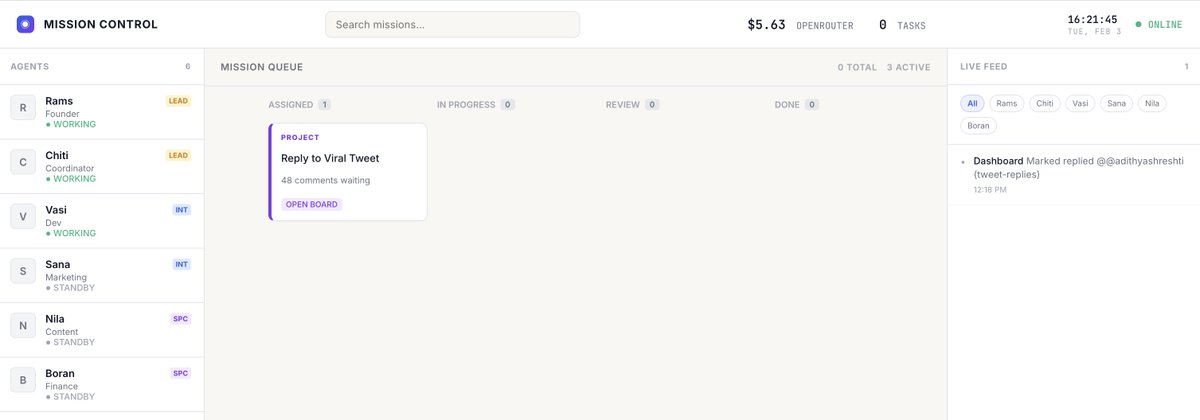
Yeah Chris, I realised it in few moments. But now Im running a hybrid setup. 1. Google Gemini CLI (OAuth) 2. OpenAI Codex (OAuth) 3. OpenRouter free tiers 4. OpenRouter paid Bot picks models based on context. OAuth handles 95%+ of traffic. OpenRouter's $10 credit barely gets touched. I don't want to touch this setup again, Let this run for next 1 day, I will share you what happens. To know about oAuth limits, run openclaw models. At end it will show OAuth/token status. I don't commit this works best, i'm still experimenting this and will share the updates.



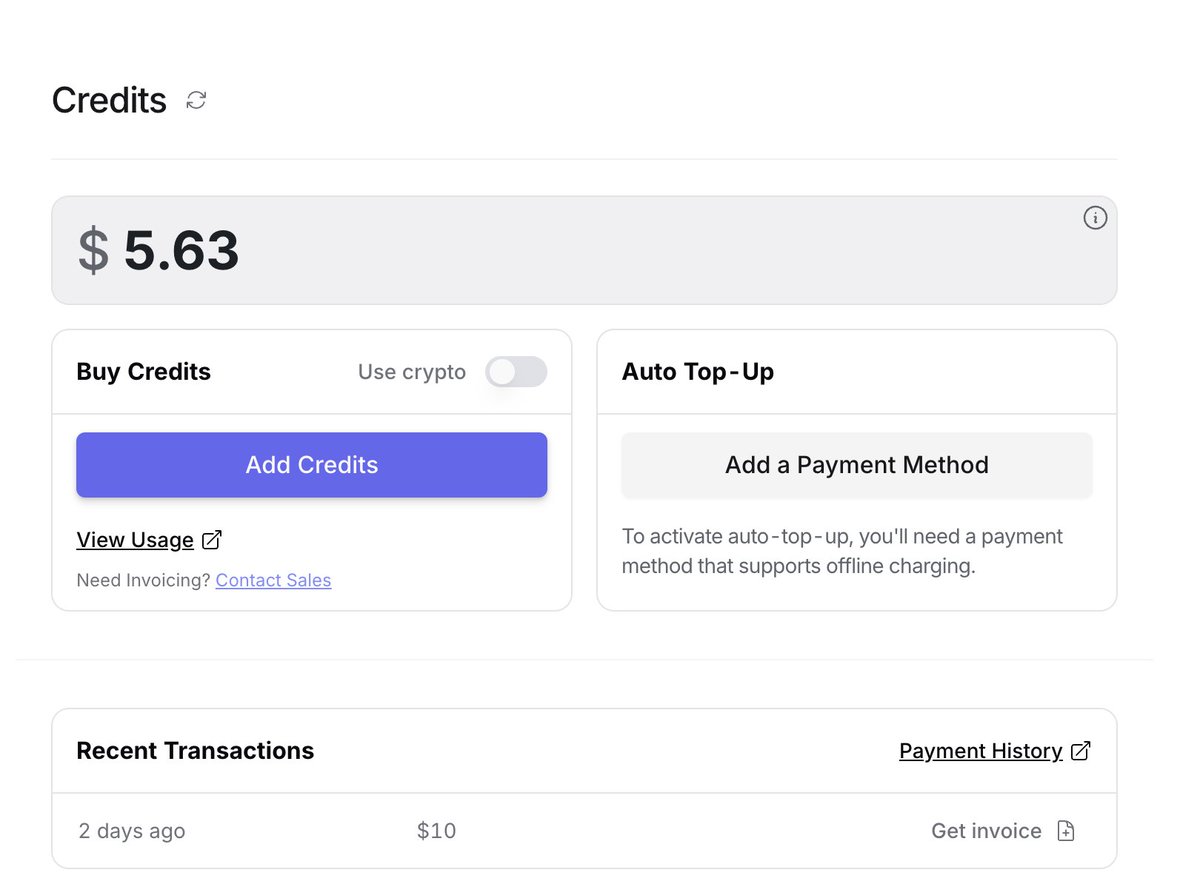
I missed my @openclaw bot, Chiti, yesterday. 🥺 For the past few weeks, I’ve been using my $20 ChatGPT subscription to power Chiti on GPT-5.2. Everything was smooth until I suddenly hit a strict rate limit and got blocked for 1.5 days. The bot went silent on Telegram. It was a wake-up call without the model, an AI agent is just an appliance without electricity. Completely useless. I tried switching to Gemini Pro as a temporary fix, but it burned through $6 within 3 hrs. I realized I needed a more sustainable architecture to manage both performance and budget. --- The Solution: A Tiered Model Strategy Instead of relying on a single model, I’ve now configured a multi-provider setup (OpenAI, Anthropic, Google, and Codex) with a tiered routing system: 1. The Daily Driver: Gemini Flash It’s incredibly cheap and fast. Chiti uses this for 80% of our interactions - basic chat, task management, and simple pings. This keeps the baseline cost near zero. 2. The Coder: GPT-5.2 (via ChatGPT Plus) This is now strictly reserved for building features or debugging. By isolating it, I avoid wasting my subscription's rate limits on simple "Hello" queries. 3. The Specialist: Claude Opus I keep this in the stack for high-level brainstorming and creative writing, used only when I need that specific reasoning edge. --- The Execution: I’ve configured Chiti to dynamically choose the right "brain" for the task. If I ask a coding question, it automatically spawns a specialist session using GPT-5.2. For everything else, it defaults to the lightweight Flash model. It’s been a fascinating experiment in balancing uptime with intelligence. I no longer worry about the bot going "dead" due to a rate limit, and my monthly spend is finally predictable. The goal isn't just to have the smartest AI, it’s to build a system that stays online and executes exactly when you need it. Hoping this works out! I’ll share more on how it performs as I use it. I’m also planning to explore other alternatives too, if you’re using a different stack, let me know!




We are building the only DEX in the world where you can bid on risky loan positions at a discount of up to 30%. All risky loan positions are liquidated openly and transparently through the RUJI Trade order book. Fair access and equal opportunities for everyone 🐳





