Sabitlenmiş Tweet

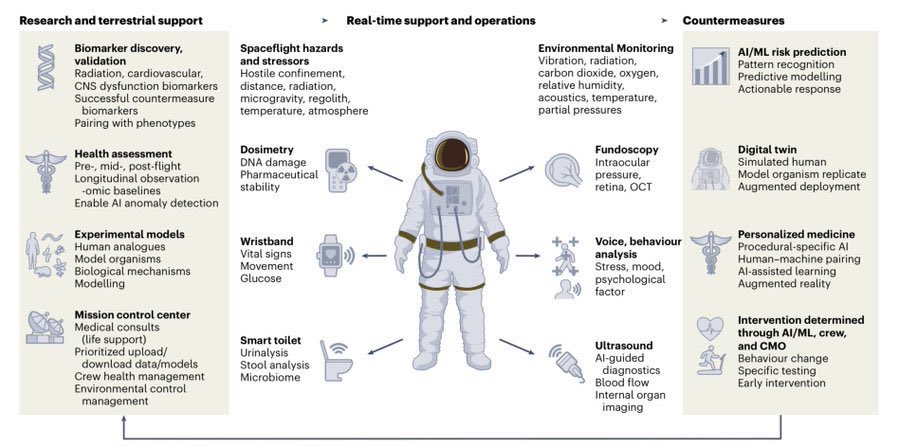
The NASA Open Science Data Repository (expansion of @NASAGeneLab) has enabled biological & health discoveries helping humanity become multi-planetary by helping life thrive in deep space on Mars and 🌘 OSDR stores precious data anyone can use and analyze, plus a community of collaborative users anyone can join, and several public tools/trainings (including AI/ML) for space biology available 🧵



English























