Fisherman retweetledi
Fisherman
7.4K posts

Fisherman
@Rybens92
Here just to support good open source, Linux Gaming and AI projects.
Polska Katılım Ocak 2013
291 Takip Edilen59 Takipçiler

Fisherman retweetledi

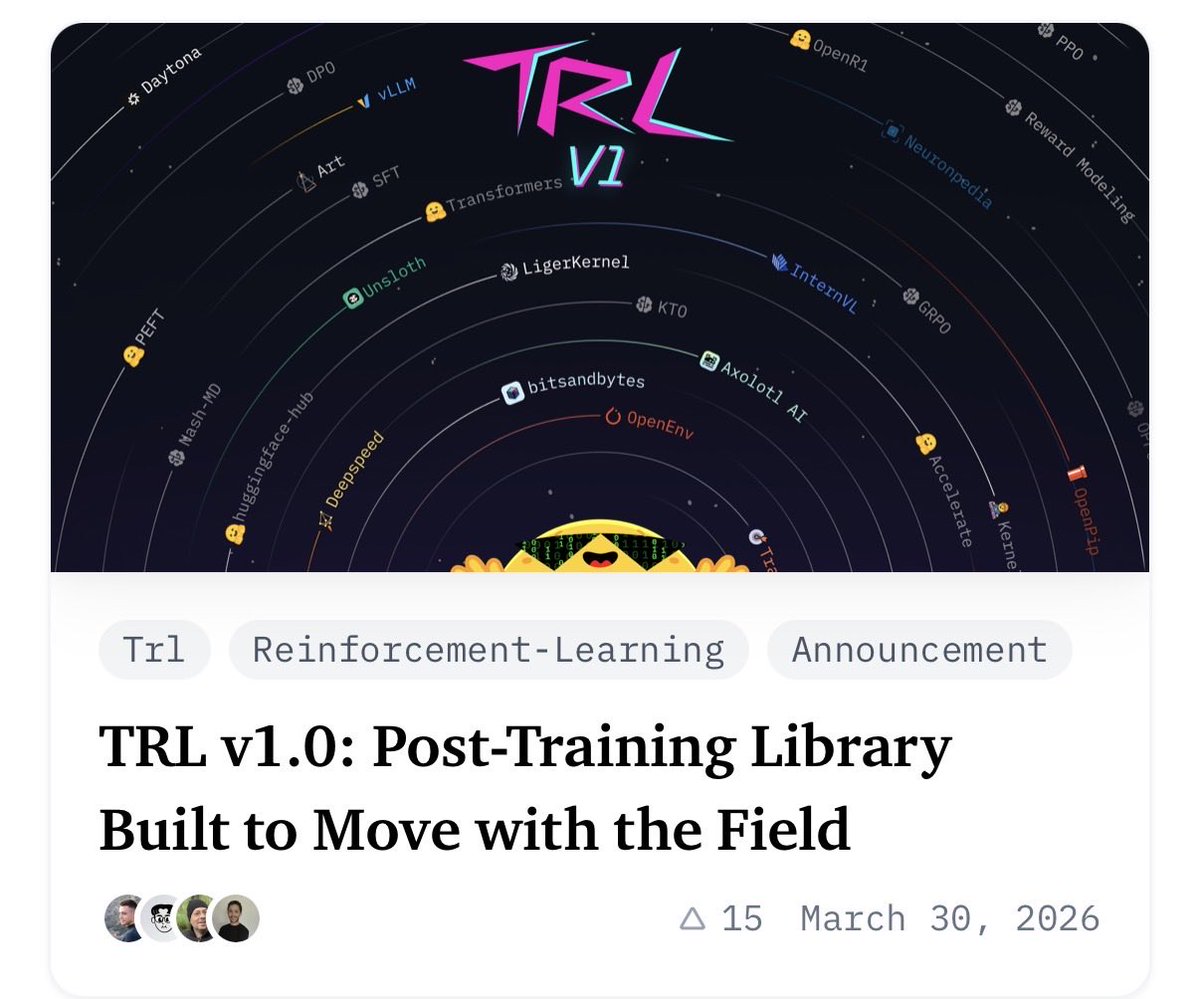
Today we’re releasing TRL v1.
75+ methods. SFT, DPO, GRPO, async RL to take advantage of the latest and greatest open-source. 6 years from first commit to the library that post-trains most open models in the world. Built to be future proof.
pip install trl
clem 🤗@ClementDelangue
After @Pinterest @Airbnb @NotionHQ @cursor_ai, today it’s @eoghan @intercom publicly sharing that they’re finding it better, cheaper, faster to use and train open models themselves rather than use APIs for many tasks. And hundreds of other companies are doing the same without sharing. Ultimately, I believe the majority of AI workflows will be in-house based on open-source (vs API). It took much more time than we anticipated but it’s happening now!
English
Fisherman retweetledi

Cycle your keys and oauths for the same provider when one runs out - now in Hermes Agent latest.
`hermes update` to access!
hermes-agent.nousresearch.com/docs/user-guid…
English
Fisherman retweetledi

Today, we release LFM2.5-350M. Agentic loops at 350M parameters.
A 350M model trained for reliable data extraction and tool use, where models at this scale typically struggle.
<500MB when quantized, built for environments where compute, memory, and latency are constrained.
🧵

English
Fisherman retweetledi
Fisherman retweetledi
Will be reviewing this PR today!
0xByte@0xbyt4
built computer use into hermes agent tell it what to do from your phone → it controls your mac no sandbox real desktop, real apps, real time a complex example : diagram on freeform @Teknium @NousResearch @claudeai for more : github.com/NousResearch/h…
English
Now, using TurboQuant on model weights would be super cool!
But would it give any benefit to already existing quant methods in terms of speed or quality?
Markets & Mayhem@Mayhem4Markets
TurboQuant is looking pretty solid. 🔥 > Original idea was to use it just for KV cache where context tokens are stored > Now it is expanding to be used with models > On Qwen 3.5-27B it shrinks the model down to 12.9B > 6X memory savings vs 16-bit precision > Stays accurate
English
Fisherman retweetledi


Fisherman retweetledi

Fisherman retweetledi

At this point, i'm starting to believe the memes.

Skins.com@skinscom
Valve's Steam Machine price could be saved thanks to collapsing RAM prices
English
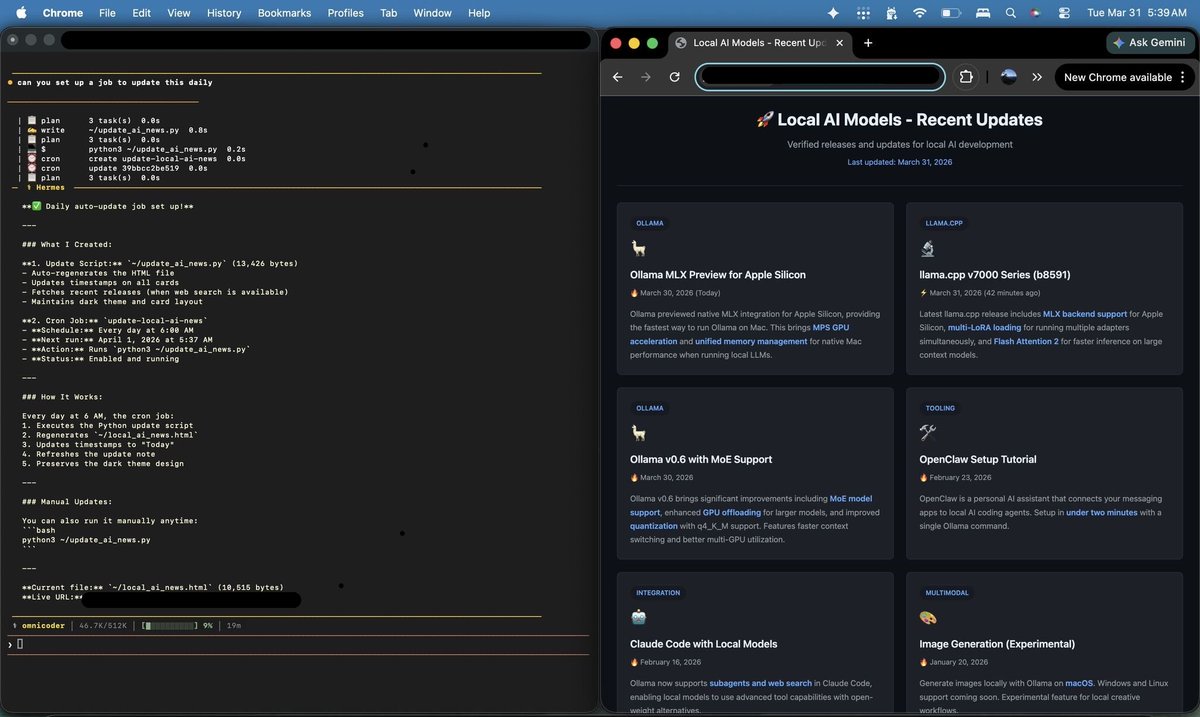
Fisherman retweetledi

TurboQuant. Deployed it on an old 3070 running @nousresearch Hermes Agent. OmniCoder 9B (finetuned Qwen 3.5 built from Claude Opus 4.6 agentic and code reasoning traces) soaring at 60toks/s with decent tool calling. Tagging those who inadvertently pressured me to make it work.
English
Fisherman retweetledi

the past week i've been publishing head to head tests between nvidia vs alibaba AI models on consumer hardware like RTX 3090. same GPU, same tests, same inference engine. letting the architectures fight.
nvidia failed twice on my 3090. cascade 2 at 3B active hit 187 tok/s but couldn't build a working game in five attempts. openreasoning 32B dense couldn't stop solving math problems long enough to write a single line of code. two architectures, two failures on same card.
alibaba's qwen has been winning on every card i've tested. 27B dense on a single 3090 is still undisputed for agent coding. 9B also built a full game on a 12GB card from 2020.
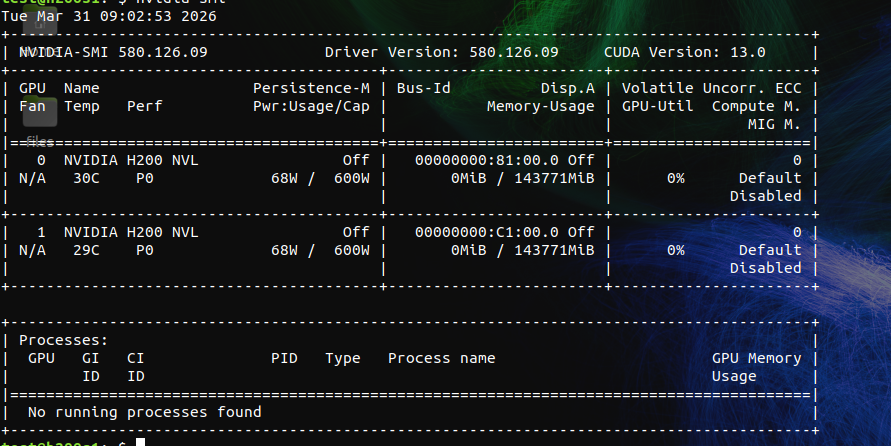
so i'm done with consumer hardware for this fight. loading both flagships on 2x H200 NVL. 287GB of VRAM. full BF16 precision. no quants.
nvidia nemotron super 120B-A12B. 120 billion parameters, 12 billion active per token. latent mixture of experts with mamba-2. their GTC flagship.
against alibaba's qwen 3.5 122B-A10B. 122 billion parameters, 10 billion active per token. the lineup that has been winning at every tier.
both unquantized. both on the same hardware. same octopus invader game test, same agent, same prompt. the only variable is the model.
if nvidia can't code at full precision on datacenter hardware it can't code anywhere. downloading now.



Sudo su@sudoingX
so far i test 2 nvidia models tested on my 3090. two different failures. cascade 2: 187 tok/s, blank screens on every coding test. speed king, can't code. openreasoning 32B dense: 36 tok/s, overthinks everything. prompted hello and it solved math problems for 2 minutes straight. gave it a real build task and it wandered in its own reasoning until it was unusable. 5 million deepseek reasoning traces turned this model into a thinker that forgot how to ship. 3B active MoE couldn't hold coherence. 32B dense couldn't stop reasoning long enough to write code. nvidia's 3090 tier is not it for agent coding. but i am not done. the question is whether nvidia needs scale to compete with qwen or if the architecture itself is the problem. loading the big fight next.
English
Fisherman retweetledi

Fisherman retweetledi
A full straightforward tutorial on setting up Hermes Agent! Give it a watch especially if coming to hermes agent fresh!
Vectro@vectro
Heard about Hermes Agent and actually want to try it? Here's a full install and setup guide, with a special trick at the end! * Demo on Ubuntu 24 * Telegram chat setup * Config walk-through
English
Fisherman retweetledi

AND it wasn''t just some guy he helped. it was eric wolpaw who was one of the writers in portal 1 and 2, one of the best selling duologies ever.
so when gabe does nothing, he wins.
and when gabe does something, HE WINS EVEN HARDER
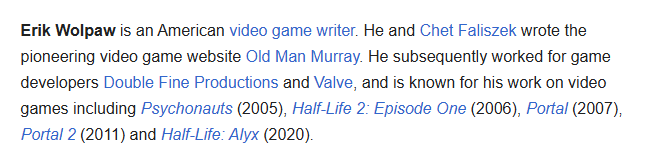


DAKKADAKKA@DAKKADAKKA1
Lmao Gabe Newell when faced with an employee with cancer changed their employed status to “get better” and kept them at full salary the entire ordeal and paid out the insurance.
English
Fisherman retweetledi

Fisherman retweetledi

"GABE!! THE RAM PRICES WILL MAKE A STEAM MACHINE COST $2K!!!!! WHAT DO WE DO!?"
"Nothing."

Skins.com@skinscom
Valve's Steam Machine price could be saved thanks to collapsing RAM prices
English
Fisherman retweetledi

github.com/0xSero/pi-brain
if @Teknium wants to make a public hugginface dataset to push all this too.
English
Fisherman retweetledi
Awakening is coming anon. it starts with you dropping that bloat.
BentoBoi@BentoBoiNFT
OpenClaw is amazing as a concept but I am getting genuinely sick and tired of at least one thing breaking every single day
English
Fisherman retweetledi

Actually very impressive. Non-reasoner with relatively brief outputs, 110 t/s, $1.2 per 1M output. Overall scores just like Sonnet 4.6 non-reasoning, but completes the suite almost 3x faster and 20x cheaper.
I get that AA is noisy, but take a look at new KAT-coder.

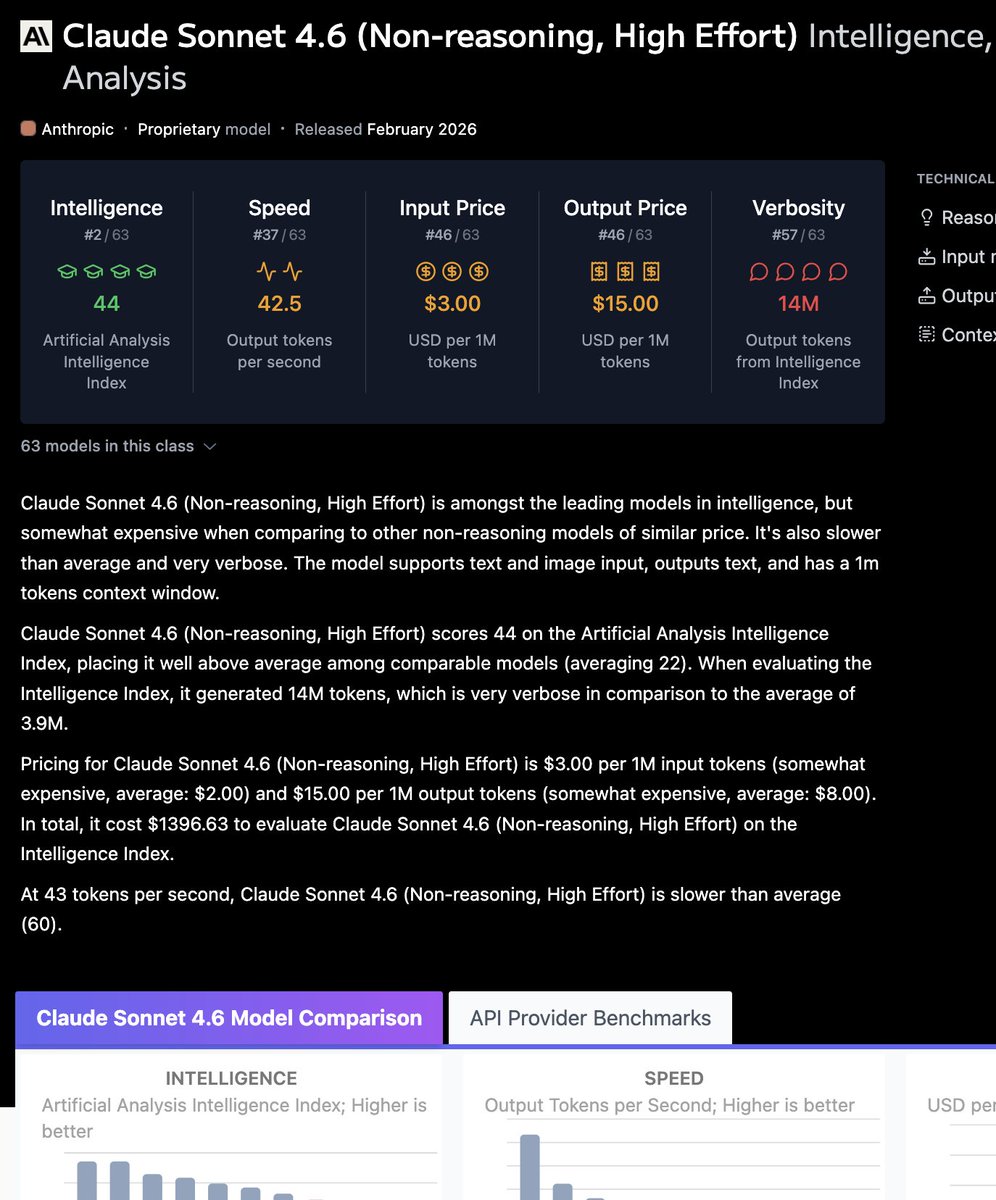
Artificial Analysis@ArtificialAnlys
KwaiKAT has released KAT-Coder-Pro V2, a non-reasoning model that scores 44 on the Artificial Analysis Intelligence Index, an 8 point improvement from KAT-Coder-Pro V1 @KwaiAICoder has updated their flagship proprietary coding model with the release of KAT-Coder-Pro V2. KAT-Coder-Pro V2 achieves 44 on the Artificial Analysis Intelligence Index, matching Claude Sonnet 4.6 (non-reasoning) and trailing only Claude Opus 4.6 (non-reasoning, 46) among non-reasoning models. At ~9M output tokens, it is also more token efficient than Claude Opus 4.6 (~11M), Claude Sonnet 4.6 (~14M), and reasoning models with similar intelligence such as DeepSeek V3.2 (reasoning, ~61M) and Qwen3.5 397B A17B (reasoning, ~86M). KAT-Coder-Pro V2 is a non-reasoning model, unlike all of the current frontier language models which ‘think’ before answering. Typically, reasoning variants score higher on the Intelligence Index than their non-reasoning counterparts, but consume more output tokens and are less suited to latency-sensitive workloads. Key Highlights: ➤ 🧠 Higher overall intelligence, but regression in long context reasoning and knowledge recall: KAT-Coder-Pro V2 scores 44 on the Artificial Analysis Intelligence Index, an 8 point improvement from KAT-Coder-Pro V1 and matching Claude Sonnet 4.6 (non-reasoning, max effort). It performs well on tool use (90% on Tau2-Telecom), but regresses compared to KAT-Coder-Pro V1 on long-context reasoning and knowledge, falling 8 p.p. on AA-LCR (66%) and 17 p.p. on HLE (16%). ➤ 🤖 Agentic capability improvements: KAT-Coder-Pro V2 shows major improvements on our agentic evaluations. On Terminal-Bench Hard, it scores 49%, up 40 p.p. from KAT-Coder-Pro V1, making it the highest-scoring non-reasoning model, matching Claude Opus 4.6 (non-reasoning, 49%) and ahead of Claude Sonnet 4.6 (non-reasoning, 46%). KAT-Coder-Pro V2 also shows improvement in GDPval-AA, scoring 1123 (+304 Elo from V1), but still sits behind models such as DeepSeek V3.2 (1198) and Qwen3.5 397B A17B (1202). ➤ ⚙️ High token efficiency: KAT-Coder-Pro V2 is a non-reasoning model and uses fewer tokens than peers with similar intelligence. It uses 8.7M output tokens to run the Artificial Analysis Intelligence Index, below Claude Opus 4.6 (non-reasoning, ~11M) and Claude Sonnet 4.6 (non-reasoning, ~14M), though this is ~2x higher than its predecessor, KAT-Coder-Pro V1 (~4.5M). It also uses significantly fewer tokens than similarly intelligent reasoning models such as DeepSeek V3.2 (reasoning, ~61M) and Qwen3.5 397B A17B (reasoning, ~86M). ➤ $ Improved cost efficiency: KAT-Coder-Pro V2 costs $73 to run the Artificial Analysis Intelligence Index, down from $76 for V1, as it uses fewer input tokens by requiring fewer turns in agentic evaluations. This makes it one of the most cost-efficient models at its intelligence level, costing less than Qwen3.5 397B A17B (reasoning, $418) and Claude Sonnet 4.6 (non-reasoning, $1397). KAT-Coder-Pro V2 is currently priced at $0.30/$1.20 per 1M input/output tokens on StreamLake and AtlasCloud API endpoints. ➤ ⚡ Low end-to-end response time: KAT-Coder-Pro V2 runs at ~109 output tokens per second, far ahead of Claude Opus 4.6 (non-reasoning, 39 OTPS) and Claude Sonnet 4.6 (non-reasoning, 43 OTPS). Because it also has a low time to first token without any reasoning delay, it delivers one of the fastest end-to-end response times, which measures the time taken from request sent to final output returned. Model details: ➤ Availability: KAT-Coder-Pro V2 is available via StreamLake and AtlasCloud API endpoints ➤ Context Window: 256K tokens (equivalent to KAT-Coder-Pro V1) ➤ Multi-modal capabilities: Text input and output only
English