Sabitlenmiş Tweet

Steven (Batman) Batchelor-Manning
3.8K posts

@S_BatMan
Founder | CTO | Building Exceptional Technology


when I started tuning llama-server, I changed flags randomly until something worked (or didn't). ncmoe 30? ncmoe 10? why is it suddenly 5x slower? what even is the KV cache eating my VRAM for? so I measured everything. every flag, every ncmoe value, the exact VRAM cost per layer, the exact point where performance falls off a cliff. this is the reference I built for myself. 16 flags, each explained with the "when to change it" and "what breaks if you get it wrong" enjoy

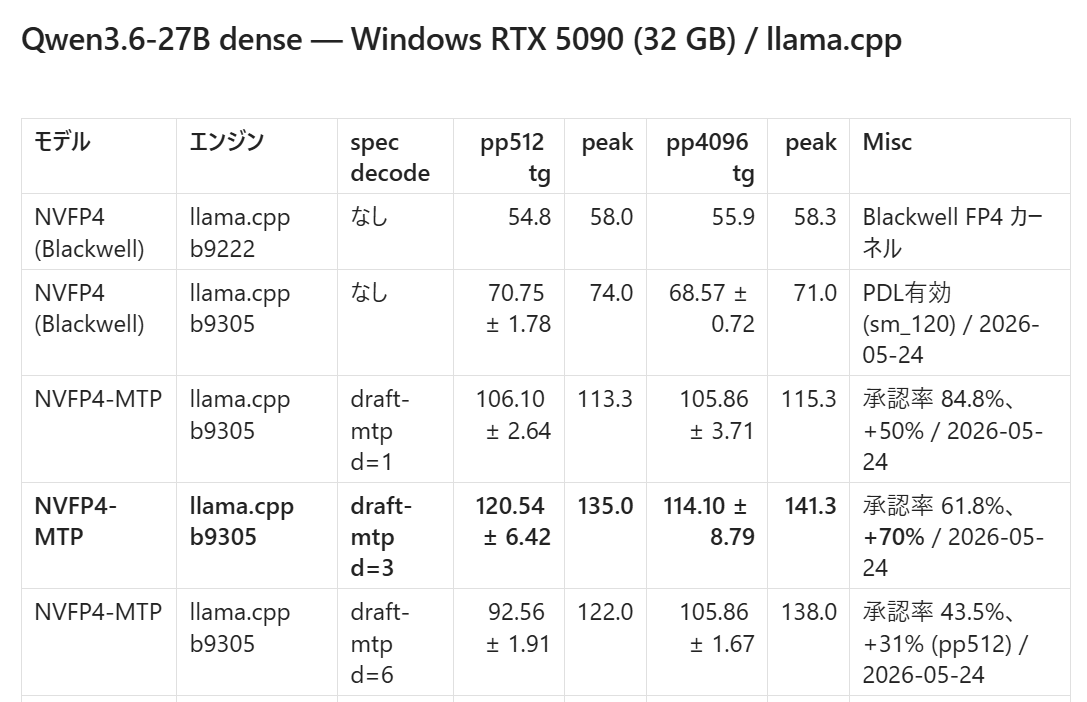
llama.cpp with MTP support makes local models fast enough to use as daily drivers 🚀 Qwen3.6-27B dense generation below on A10G: From 25 tok/st to 45 tok/s (+78%)!

look at this. opus 4.7 max thinking on claude code, the moment my cursor reviewer pushes back. realizes it's fucked. same opus 4.7. same max thinking. same task. caught by the same model running in cursor's harness. cursor wins every single time and it's not close. claude code feels like a q4 quant of the same opus 4.7 max these days. half the rigor, missed context, sloppy pre-audits. idk if anthropic is nerfing the subscription model or if the harness is being built by retards. cursor has nailed something the claude code team hasn't, and i'm having to rework everything now. cursor is my primary frontier now. it's what i always wanted claude code to be.
16 local AI agents streaming at once! MiniMax M2.7 NVFP4 — 2x GB10, no cloud APIs.
@0xSero I gotchu! github.com/r0b0tlab/qwen3…


2 months ago, I started building unified memory layers with knowledge graphs. Here’s the most common question I’ve been asked: “How do you handle entity resolution and deduplication without corrupting the graph?” I didn’t want to give a high-level answer based on assumptions... So I spent a lot of time studying how systems like mem0, cognee, and Neo4j approach this problem. While experimenting with orchestration patterns using @PrefectIO to improve durability and reduce costs. I discovered most people treat entity resolution and deduplication as the same thing. But they’re not. The best memory systems separate naming from identity. Here’s what you have to do after your LLM extracts an entity: 1/ Resolution → "What should we call this?" This layer handles: Typos Acronyms Surface-form similarity Using exact, fuzzy, and semantic matching only against names of nodes of the same type. Examples: “NYC” ↔ “New York City” “JP Morgan” ↔ “JPMorgan Chase” At this stage, the system only updates canonical names used later for soft matching. No graph merges happen yet. Because similar names are NOT strong enough evidence that two entities are identical. For example: Apple: Company ≠ Fruit Jensen Huang: CEO of NVIDIA ≠ A doctor in Taipei with the same name 2/ Deduplication → "Is this the same real-world entity?" Now we embed the full entity context and compare it against existing nodes using semantic + fuzzy similarity across the full context. Based on the similarity score (0 → 1), there are 3 outcomes: High confidence (≥0.95) → auto-merge Medium confidence (>0.85) → human review Low confidence (≤0.85) → new node This is critical because false merges silently corrupt the graph. The smartest design decision I found was treating evidence strength as permission strength: Weak evidence earns a new node Strong evidence earns a merge Uncertain evidence earns a review queue This kept the graph clean as memory scales. But the graph model is only half the problem... Building KGs on top of unstructured data is expensive. These operations all cost money: LLM extraction Entity resolution Embeddings Deduplication If one downstream step fails and you replay the whole pipeline, you burn tokens recomputing work you already paid for. So the best architectures split workflows into checkpointed tasks with retries + caching. This is where tools like @PrefectIO fit extremely well for production memory systems. It lets you: Cache expensive extraction steps Retry only failed stages Batch embeddings efficiently Scale ingestion safely Add observability into every phase Without restarting from every failure from scratch. P.S. What’s been the hardest part for you when building long-term memory for agents via KG?

Local LLM is incredibly complex. Hardware selection, quantization, harnesses, engines, tensor parallelism, unmodified models, MTP… Despite its complexity, local LLM is irresistibly fascinating. I started using X because there was almost no one close to me who could share this excitement with me.