
Sameera Horawalavithana
5.4K posts

Sameera Horawalavithana
@SamTube405
#AI #Multimodal Scientist @PNNLab PhD @cseUSF Opinions here are my own and do not represent my employer. Proud 🇱🇰 Live 🇺🇸
Tampa, FL Katılım Kasım 2010
903 Takip Edilen710 Takipçiler
4/ some VLM capabilities only emerge in the newest LLM generation. Other tasks dominated by visual understanding barely improve regardless of which LLAMA you plug in
English
🧵 1/ New preprint drop: "Back to the Barn with LLAMAs: Evolving Pretrained LLM Backbones in Finetuning Vision Language Models" 🦙
If you swap a better LLM backbone into your VLM, do you get a better VLM?
Short answer: not really. Longer answer: it's more interesting than that.
English
Sameera Horawalavithana retweetledi

Streamlining federal permitting with AI 📄🖥️⏩
PNNL researchers are using AI to bring valuable data distributed across hundreds of federal government agencies into a single dataset that's crucial for modernizing permitting technology for the 21st century.
English
Sameera Horawalavithana retweetledi

CEQ coordinated with @ENERGY’s @PNNLab PermitAI project on the release of NEPATEC 2.0, a major accomplishment on the road to a simplified, speedier Federal permitting and environmental review process.
Pacific Northwest National Laboratory@PNNLab
Streamlining federal permitting with AI 📄🖥️⏩ PNNL researchers are using AI to bring valuable data distributed across hundreds of federal government agencies into a single dataset that's crucial for modernizing permitting technology for the 21st century.
English
We are organizing AI4Permitting Workshop on April 29th at the NAEP 2025 conference in Charleston, South Carolina.
Learn how to speed up National Environmental Policy Act (NEPA) processes at our upcoming workshop at NAEP 2025.
pnnl.gov/events/using-n…
#AI4Permitting #NEPA

English
Sameera Horawalavithana retweetledi

We also currently have a kaggle competition open, which is running LLM evaluations on a QuAD benchmark specific to understanding permitting documents - deadline is june 30!
kaggle.com/competitions/l…

English
Sameera Horawalavithana retweetledi
This corpus is part of DOE's voltAIc initiative, which is using LLMs to accelerate permitting processes
This corpus was developed in partnership with @PNNLab - you can find more details about their work on this project here:
pnnl.gov/projects/polic…
English
Sameera Horawalavithana retweetledi
🚨if you care about fixing NEPA environmental permitting OR are looking for new high-quality domain text corpuses to build LLMs on top of...
DOE just released a 3.6B token corpus of federal permitting documents on huggingface!
This corpus includes...
English
Sameera Horawalavithana retweetledi

The video of the Lytle Lecture I gave at University of Washington last week is available.
Title: "Objective Driven AI: Towards Machines that can Learn, Reason, and Plan"
Lytle Lecture Page: ece.uw.edu/news-events/ly…
Slides: drive.google.com/file/d/1e6EtQP…
Video: youtu.be/d_bdU3LsLzE?si…

YouTube
English
Sameera Horawalavithana retweetledi

📢 Accepted papers are up!
🔗: an-instructive-workshop.github.io/accepted/
Check out the range of cool new work on instruction training!
English
Sameera Horawalavithana retweetledi

📢📢 I am recruiting PhD students for our group at Auburn to work on open-world event understanding and active embodied vision! If you are interested in working with our group, reach out!
More info: saakur.github.io/group.html
Please RT!
English
Sameera Horawalavithana retweetledi

A new multimodal model LLaMA-SciTune for science-focused visual and language understanding.
📄 arxiv.org/abs/2307.01139…

English
Sameera Horawalavithana retweetledi

SCITUNE: Aligning Large Language Models with Scientific Multimodal
Instructions
Abs: arxiv.org/abs/2307.01139
Pdf: arxiv.org/pdf/2307.01139…
Presenting SciTune, a tuning framework to improve large language models' (LLMs) ability to follow scientific multimodal instructions. SciTune includes two stages: scientific concept alignment to learn across various scientific visual signals and textual signals, and scientific instruction tuning to fine-tune on a multimodal scientific reasoning task. LLaMA-SciTune, surpasses human performance on the ScienceQA multimodal reasoning benchmark and performs significantly better than SoTA vision-language models in a variety of scientific image understanding tasks with zero-demonstrations during the inference time.

English
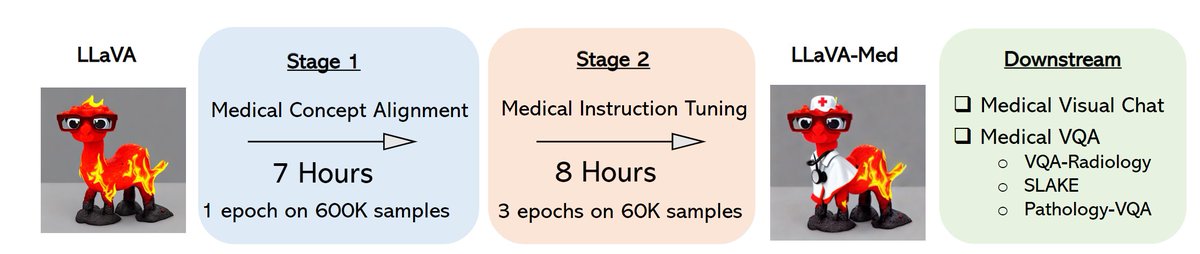
@ChunyuanLi That means, LLaMA -> Stage 1.1 Feature Alignment (CC3M) -> Stage 1.2 Medical Concept Alignment -> Stage 2 Medical Instruction Tuning
English
@ChunyuanLi Since you used LLaVA as the base (LLaMA -> Stage 1: Feature Alignment -> Stage 2: Instruction Tuning -> LLaVA), I was thinking whether performing LLaVA-Med (Stage 1) on top of LLaVA (Stage 1) can increase the performance.
English

1/3 LLaVA-Med, our first attempt towards building a large language and vision assistant with multimodal GPT-4 level capabilities for the healthcare space, trained eight A100s in <15 hours. 🚀🧑⚕️
Paper: arxiv.org/abs/2306.00890
Project: github.com/microsoft/LLaV…

AK@_akhaliq
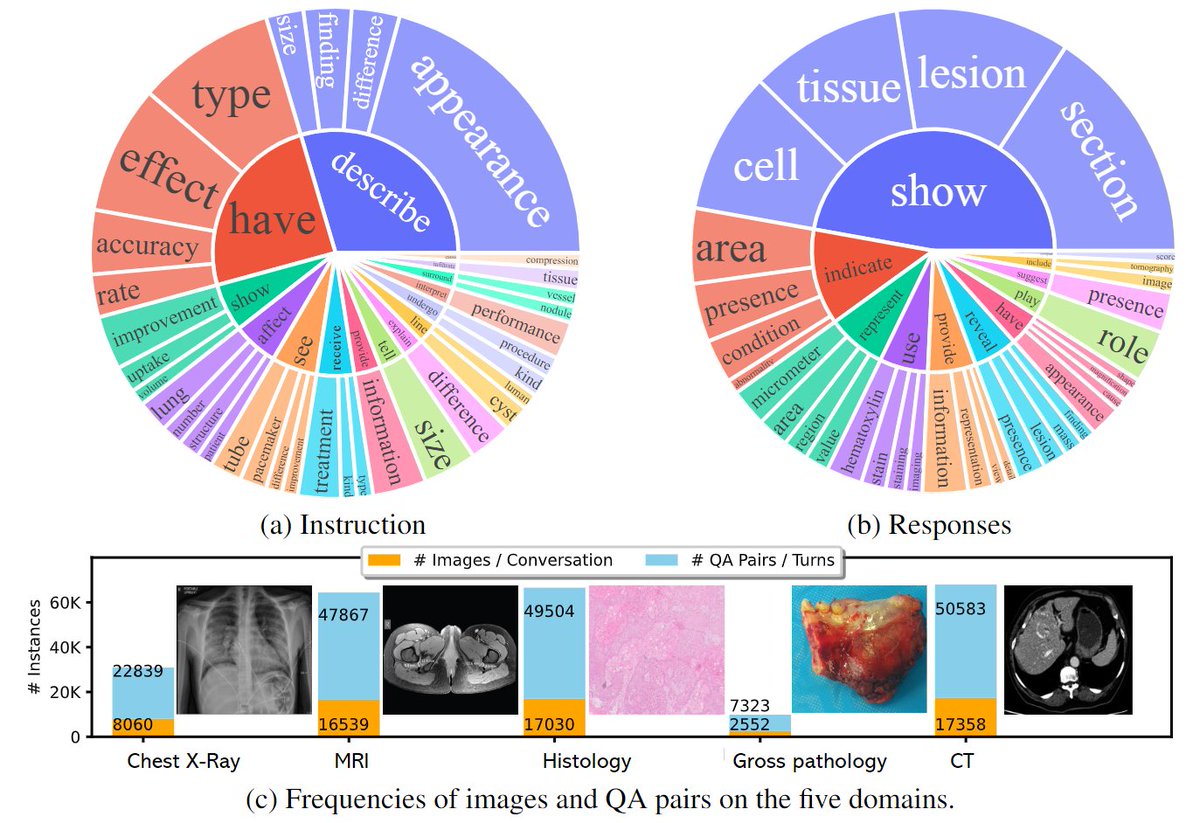
LLaVA-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day paper page: huggingface.co/papers/2306.00… propose a cost-efficient approach for training a vision-language conversational assistant that can answer open-ended research questions of biomedical images. The key idea is to leverage a large-scale, broad-coverage biomedical figure-caption dataset extracted from PubMed Central, use GPT-4 to self-instruct open-ended instruction-following data from the captions, and then fine-tune a large general-domain vision-language model using a novel curriculum learning method. Specifically, the model first learns to align biomedical vocabulary using the figure-caption pairs as is, then learns to master open-ended conversational semantics using GPT-4 generated instruction-following data, broadly mimicking how a layperson gradually acquires biomedical knowledge. This enables us to train a Large Language and Vision Assistant for BioMedicine (LLaVA-Med) in less than 15 hours (with eight A100s). LLaVA-Med exhibits excellent multimodal conversational capability and can follow open-ended instruction to assist with inquiries about a biomedical image. On three standard biomedical visual question answering datasets, LLaVA-Med outperforms previous supervised state-of-the-art on certain metrics. To facilitate biomedical multimodal research, we will release our instruction-following data and the LLaVA-Med model.
English
@windx0303 @shauryr @jp22_5 @HuijuanXu_ @cleegiles @ani_nenkova @lunweiku @PSUCrowdAILab Yes, Thanks.
English

@SamTube405 @shauryr @jp22_5 @HuijuanXu_ @cleegiles @ani_nenkova @lunweiku @PSUCrowdAILab Ooops. It should be public now. Can you see it?
State College, PA 🇺🇸 English
