
Tom Sawada
634 posts
Tom Sawada
@tsawada_ml
ML @ GaTech (PhD) 日本語 DMs Open.
Atlanta, GA Katılım Aralık 2021
241 Takip Edilen341 Takipçiler
The takeaway: You can "Train It and Forget It."
The privacy & simplicity benefits of dropping the BPE merge list at inference may outweigh the minimal performance trade-offs , enabling more secure tokenization for deployed LLMs.
Joint work with @kartik_goyal_ (4/4)
English
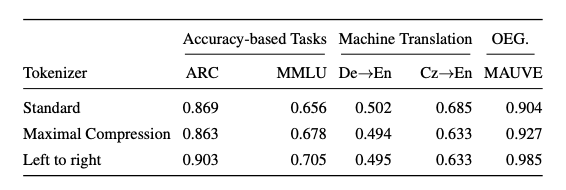
The results? Deliberately corrupting the merge list tanks performance.
But our compression-based methods are robust, even *outperforming* the standard tokenizer on QA (MMLU/ARC) & open-ended generation. We saw only modest drops in machine translation. (3/4)
English
BPE merge lists in LLMs are a privacy risk. What if we just ignored them at inference?
Our paper shows you can ditch the merge list without retraining. Merge-list-free tokenization has minimal impact on performance & can even improve it on some tasks.
Paper: arxiv.org/abs/2508.06621
👇 (1/4)
English
LLMs don’t take tests like students.
So why evaluate them like students?
Our method decouples reasoning from answer selection.
It’s automatic, scalable, and works with existing QA benchmarks.
📄 arxiv.org/abs/2507.23776
w/ Ryan Yan and @kartik_goyal_
English
We tried using another LLM to “judge” the model’s reasoning.
Turns out it’s unreliable — even when we feed it perfect explanations (!)
But when we match explanations to answers, accuracy shoots up (>99%).
No hallucinated grading.

English
Why do we evaluate LLMs using multiple-choice QA...
...when in practice, we ask them to generate open-ended answers?
Standard evaluation rewards models for choosing the right letter — not for reasoning their way to an answer.
A better alternative: Cascaded Information Disclosure
English

I’m hiring multiple research interns at the MIT-IBM lab to work on advanced LLM reasoning!
The application process is simple—just send me your favorite published paper. Only one😀!!
English

Spring cleaning (wiping surfaces) this morning and discovering that the guy who invented this mathematical object also designed my apartment


English
Tom Sawada retweetledi

Introducing the GPT Store: Over 3M GPTs have been created and now you can find the most useful versions of ChatGPT for you.
openai.com/blog/introduci…
GIF
English
Tom Sawada retweetledi

What did I tell you a few days ago? 2024 is the year of robotics. Mobile-ALOHA is an open-source robot hardware that can do dexterous, bimanual tasks like cooking a meal (with human teleoperation). Very soon, hardware will no longer bottleneck us on the quest for human-level, generally capable robots. The brain will be.
This work is done by 3 researchers with academic budget. What an incredible job! Stanford rocks! Congrats to @zipengfu @tonyzzhao @chelseabfinn
Academia is no longer the place for the biggest frontier LLMs, simply because of resource constraints. But robotics levels the playing field a bit between academia and industry, at least in the near term. More affordable hardware is the inevitable trend. Advice for aspiring PhD students: embrace robotics - less crowded, more impactful.
Website: mobile-aloha.github.io
Hardware assembly tutorial (oh yes we need more of these!): docs.google.com/document/d/1_3…
Codebase: github.com/MarkFzp/mobile…
English
Tom Sawada retweetledi

This is an interesting paper that learns a process reward model without human annotations.
The idea is to evaluate the accuracy of full reasoning traces generated from a given partial reasoning step.
Nice to see Llemma-34B getting 47.3% on MATH!
arxiv.org/abs/2312.08935
English

Tom Sawada retweetledi

Very impressive work from the Superalignment team just released! Methodology + code is all public & new $10M grant program for new alignment projects.

English
Tom Sawada retweetledi

Intuitively, superhuman AI systems should "know" if they're acting safely.
But can we "summon" such concepts from strong models with only weak supervision?
Incredibly excited to finally share what we've been working on: weak-to-strong generalization. 1/
x.com/OpenAI/status/…

OpenAI@OpenAI
In the future, humans will need to supervise AI systems much smarter than them. We study an analogy: small models supervising large models. Read the Superalignment team's first paper showing progress on a new approach, weak-to-strong generalization: openai.com/research/weak-…
English
Tom Sawada retweetledi

The first thing you need to build a high quality mathematics model is high quality mathematics data. Don't worry, we got your back!
Hear the oral at the Math-AI Workshop!
x.com/keirp1/status/…
Keiran Paster@keirp1
Introducing OpenWebMath, a massive dataset containing every math document found on the internet - with equations in LaTeX format! 🤗 Download on @HuggingFace: huggingface.co/datasets/open-… 📝 Read the paper: arxiv.org/abs/2310.06786 w/ @dsantosmarco, @zhangir_azerbay, @jimmybajimmyba!
English