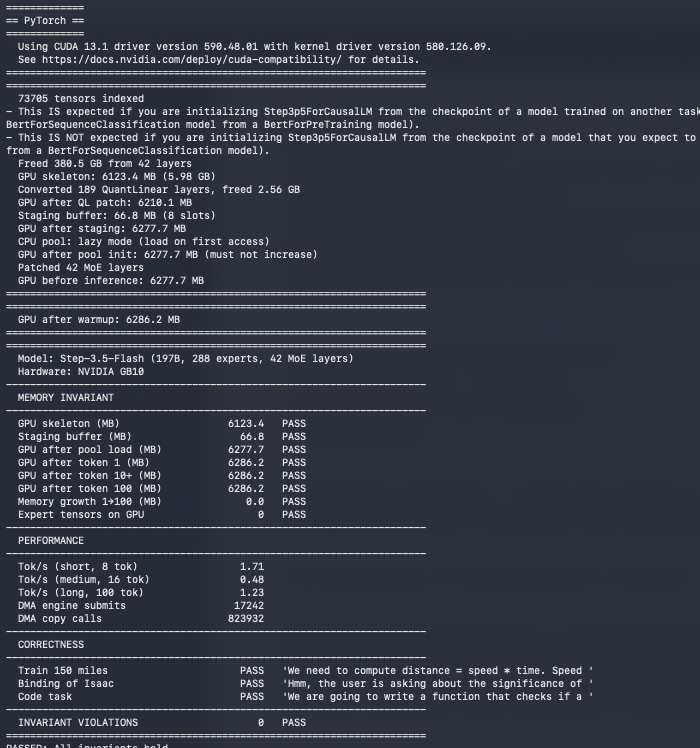
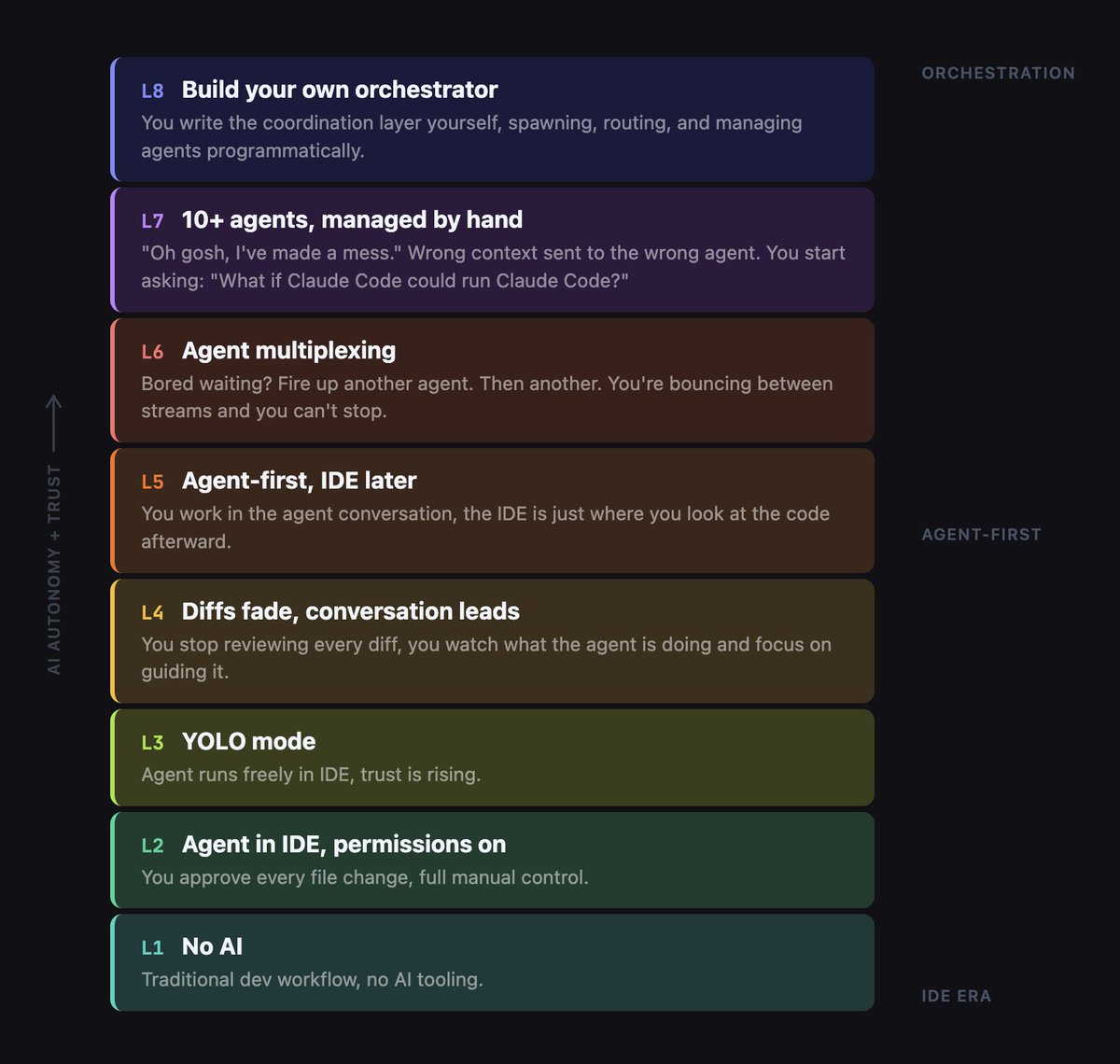
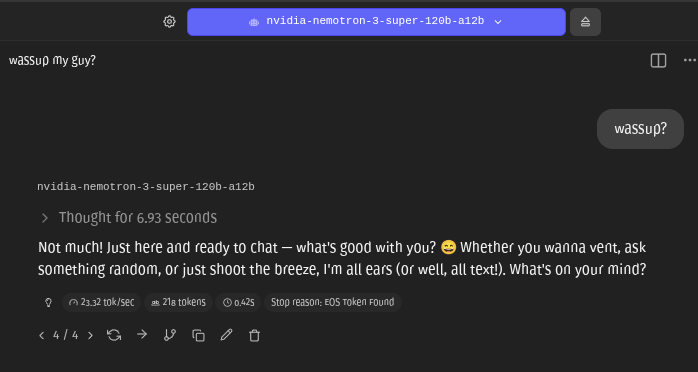
Sabitlenmiş Tweet

Why am I building scala-algorithms.com?
#Scala is growing faster in 2020, but supply must keep up with demand.
To help candidates, we need solutions with:
- Standard #Scala (vs Python/C mutable style)
- Consistent explanations & proofs to really learn
- Test-cases for #TDD
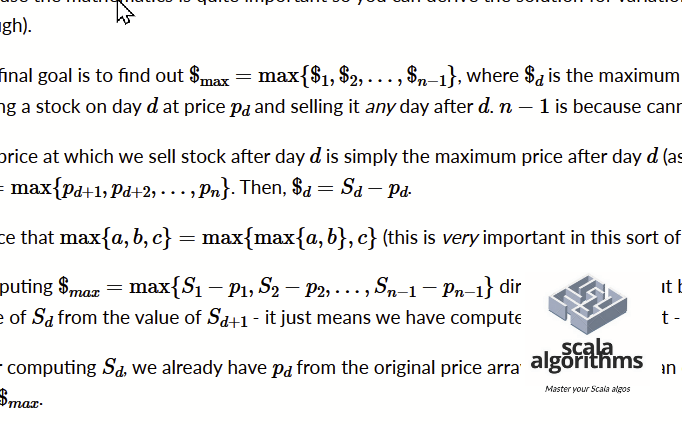

English