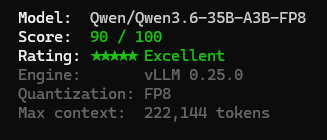
I love how easy it is to extend @pidotdev -- here is my /exit alias because I'm a create of habit.
English
Tim Messerschmidt
25.9K posts

@SeraAndroid
DevRel Ecosystems Lead EMEA at Google. Proud dad, happy husband, and feminist. O'Reilly author. I ♥️ home automation. Opinions stated here are my own.

Germany just released a model that's actually... pretty good. Soofi S 30B-A3B: • 27T training tokens • Open weights • German + English focused • Full transparency on data, training, and evaluation • Trained entirely in Germany It's still behind the frontier leaders. But it's much closer than most people would expect. The bigger story: More countries are building serious sovereign AI stacks from scratch.
When you see a semi-open laptop at an ICML event 😂

this one has been sitting in my drafts for way too long, i finally finished it and im back to blogposting i have been using pi since jan/feb and im loving it. after nix shilling, i want to introduce (and shill) one of my fav tools so far, made by @badlogicgames (now under earndil) and i treat it like neovim configs, hence the title of my blog post

𝐀𝐠𝐧𝐞𝐬 𝟐.𝟓 𝐏𝐫𝐨, 𝟐.𝟓 𝐅𝐥𝐚𝐬𝐡 & 𝟐.𝟎 𝐅𝐥𝐚𝐬𝐡 𝐀𝐜𝐫𝐨𝐬𝐬 𝐂𝐨𝐝𝐢𝐧𝐠 𝐁𝐞𝐧𝐜𝐡𝐦𝐚𝐫𝐤𝐬 Our internal evaluation shows Agnes 2.5 Pro competing strongly across seven tests, while 2.5 Flash improves on 2.0 Flash in every benchmark, with the clearest gains on SWE Atlas. Build with Agnes.
it took 1 intern 3 months of continuous work, but eventually, a quantization method that beat every other algo in the market, including @nvidia's official modelopt to explain why this matters, i ask for exactly 69 seconds of your attention (275 words @ avg reading speed of 238 wpm): frontier models (like glm52) are huge (~0.8T params). as released, each parameter takes 2 bytes (bf16), so overall size is about 1.6 tb a b200 has 180gb of memory. a node of 8 gives you 1.44 tb, barely fits weights, much less activations / kv cache must quantize the model (reduce the size of each individual parameters) to serve. fp8 quantization means each parameter takes 1 byte (fits in 0.8 tb), fp4 takes 1/2 a byte (fits in 0.4 tb) cutting the model to a quarter its original size is necessary for it to run a) cheap b) fast, and every lab serving models does this. but, quantization lobotomizes the model if not done correctly (this is why you see people complain about @AnthropicAI nerfing claude or @OpenAI nerfing codex) there are currently several algorithms (like Nvidia's official model-opt) that attempt to figure how to quantize a model with the least amount of damage. they find the redundant layers that can be slashed, and sensitive/important layers that need to stay in full-precision. these algo's have two drawbacks: 1) they take a long time to run 2) they quite often result in a sub-optimal configuration for the past 3 months, a research (and, as always, waterloo) intern on our model perf team (@the_joshua_hill) came up with a new quant algorithm. it consistently finds the optimal configuration: a) in less time than SOTA b) with more aggressive quant than SOTA c) scoring higher on benchmarks than SOTA achieving just one of the above is a feat on its own. all three...excited for the paper to come out this week