
@productaizery @pelaseyed @doodlestein I just wrote a thing about that! simonwillison.net/2026/Mar/24/pa…
English
Simon Willison
60.4K posts

@simonw
Creator @datasetteproj, co-creator Django. PSF board. Hangs out with @natbat. He/Him. Mastodon: https://t.co/t0MrmnJW0K Bsky: https://t.co/OnWIyhX4CH


LiteLLM HAS BEEN COMPROMISED, DO NOT UPDATE. We just discovered that LiteLLM pypi release 1.82.8. It has been compromised, it contains litellm_init.pth with base64 encoded instructions to send all the credentials it can find to remote server + self-replicate. link below
I got a 1T (trillion) parameter model running on my MacBook Pro. Kimi-K2. 1.029T params. ~1 TB raw weights. 524 GB converted. ~1.7 tok/s. Yesterday it was 671B. Today it's 1T. Same laptop. Same M4 Max. No cloud. When I say we: I mean Claude and me.
Running 400B model on iPhone! 0.6 t/s Credit @danveloper @alexintosh @danpacary @anemll
I got a 1T-parameter model running locally on my MacBook Pro. LLM: Kimi K2.5 1,026,408,232,448 params (~1.026T) Hardware: M2 Max MacBook Pro (2023) w/ 96GB unified memory Running on MLX with a flash-style SSD streaming path + local patching. This is an experimental setup and I haven’t optimized speed yet, but it’s stable enough that I’ve started testing it in an autoresearch-style loop. #LocalAI #MLX #MoE

Thankfully the LiteLLM package has now been marked as "quarantined" on PyPI so attempting to install the compromised update via pip et al shouldn't work


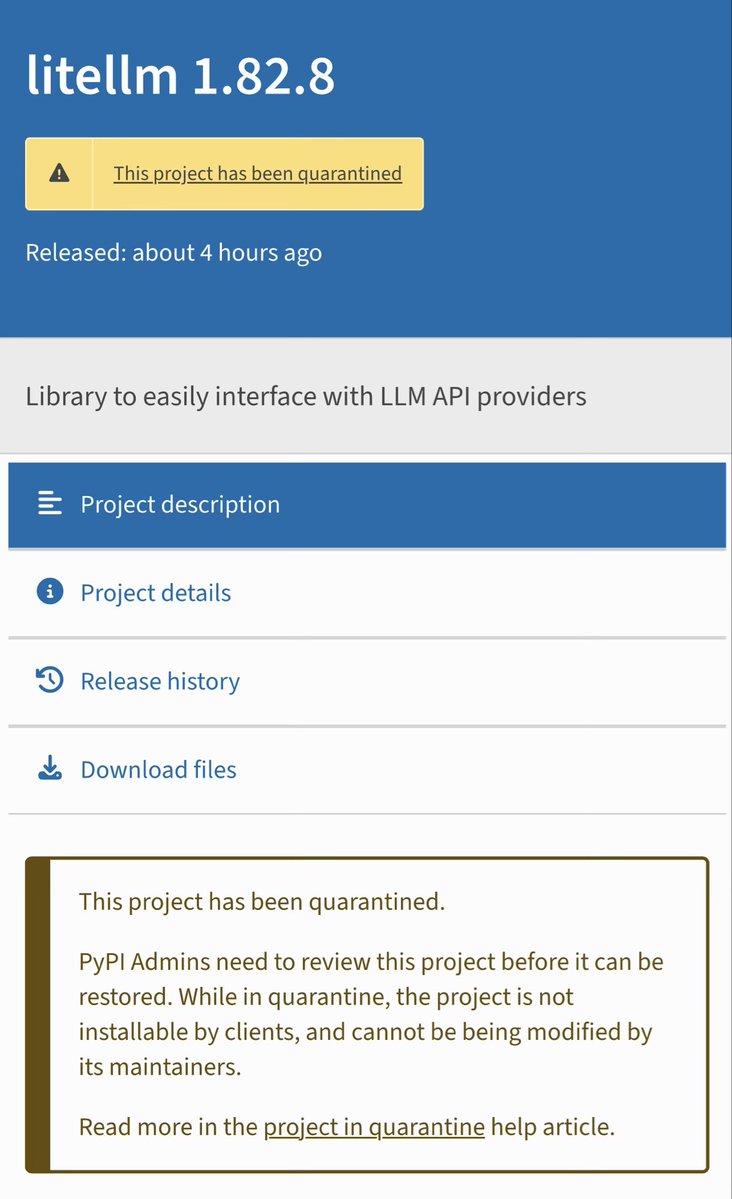
LiteLLM HAS BEEN COMPROMISED, DO NOT UPDATE. We just discovered that LiteLLM pypi release 1.82.8. It has been compromised, it contains litellm_init.pth with base64 encoded instructions to send all the credentials it can find to remote server + self-replicate. link below



