
SimonZhao
69 posts

SimonZhao
@SimonZhaoAI
AI algorithm engineer | AI startup founder focused on AI agents. Personally following the AGI journey.
Katılım Ağustos 2017
112 Takip Edilen3 Takipçiler



@colemcfaul @AnthropicAI Once AI becomes an indispensable factor of production for humanity, ideology will indeed constrain its development. This constraint is a limitation of thought, not of cognition. What Harness needs is to serve concrete work, rather than specific vested interests.
English

A few weeks ago, I joined @AnthropicAI as a Geopolitical Analyst! So excited to join the team at an important juncture in the US-PRC competition in AI.
We just published a paper that explains some of our thinking on that competition, why maintaining US AI leadership is critical to ensure the safe and responsible deployment of AI, and why the window of opportunity for policy action is now. Would love to hear your thoughts!
Anthropic@AnthropicAI
We've published a paper that explains our views on AI competition between the US and China. The US and democratic allies hold the lead in frontier AI today. Read more on what it’ll take to keep that lead: anthropic.com/research/2028-…
English
@AnthropicAI Once AI becomes an indispensable factor of production for humanity, ideology will indeed constrain its development. This constraint is a limitation of thought, not of cognition. What Harness needs is to serve concrete work, rather than specific vested interests.
English

We've published a paper that explains our views on AI competition between the US and China.
The US and democratic allies hold the lead in frontier AI today. Read more on what it’ll take to keep that lead: anthropic.com/research/2028-…
English

GPT-5.5的网络攻击能力好像比前段时间吹上天的Mythos
没差这么多呀😂

AI Security Institute@AISecurityInst
OpenAI’s GPT-5.5 is the second model to complete one of our multi-step cyber-attack simulations end-to-end 🧵
中文
@Lonely__MH 这个code areana benchmark主要测评的是前端构建能力,不能覆盖其它代码场景,所以gpt-5.5都进不了前三
中文

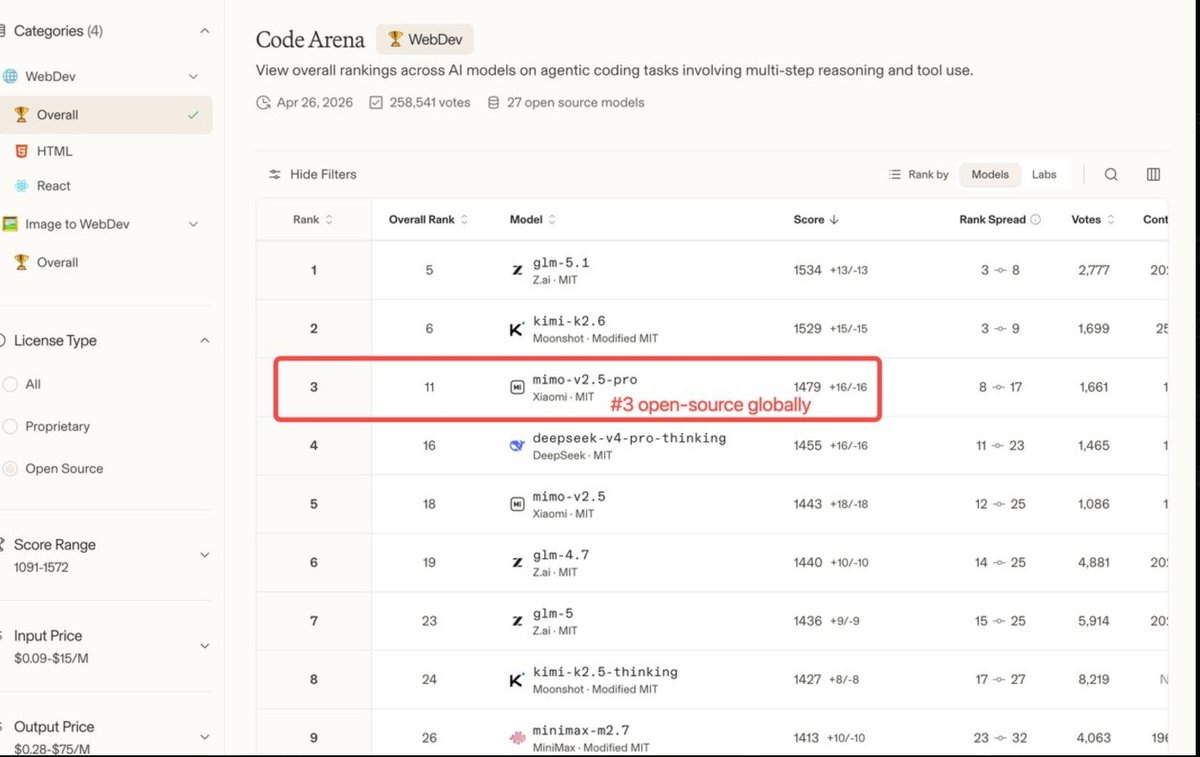
🚀小米 MiMo 冲上来了
DeepSeek 竟然垫底了?
刚刷到最新的 Arena 榜单
国产大模型在编码领域的位次大洗牌
国产大模型编码领域排名:
1. GLM-5.1 强的可怕
2. Kimi - k2.6 稳如老狗
3. mimo-v2.5-pro 小米这波表现相当实事求是
4.DeepSeek-V4-pro 本以为是王者,没想到垫底🤣
心疼DeepSeek 一秒,话说GLM 现在好抢了吗???
传送门👉🏻:arena.ai/leaderboard/co…
Lonely@Lonely__MH
中文

很值得看的一个帖子:Redis 作者分享的一个真实实验对比
过去一周,他用 Claude Code Opus 4.6 和 Codex GPT 5.4(max thinking)进行了长时间的自主运行,在独立的目录环境中反复测试。
任务非常复杂,从一个早期90年代的 Unix 磁盘镜像,反向工程早已消失的 SCSI 控制器及其集成 ROM。这是为了计算机历史和博物馆合作的项目,需要结合硬件知识、汇编/反汇编等深度工程能力。
实验结果:
GPT 5.4 :在多次长时间运行中取得了所有主要进展,能有效混合硬件知识、反汇编技巧等,完成复杂逆向工作。
Claude Opus 4.6:只取得了少量次要进展,在高难度任务上几乎一点用都没有。
他的结论:对于高难度的工程工作,两者差距非常残酷。GPT 5.4 明显更强,尤其在需要深度推理和长时程任务时。
原帖中还有对比图。
antirez@antirez
During the last week I executed very long autonomous sessions of Claude Code Opus 4.6 and Codex GPT 5.4 (both at max thinking budget), in cloned directories (refreshed every time one was behind). I burned a lot of (flat rate, my OSS free account + my PRO account) of tokens...
中文
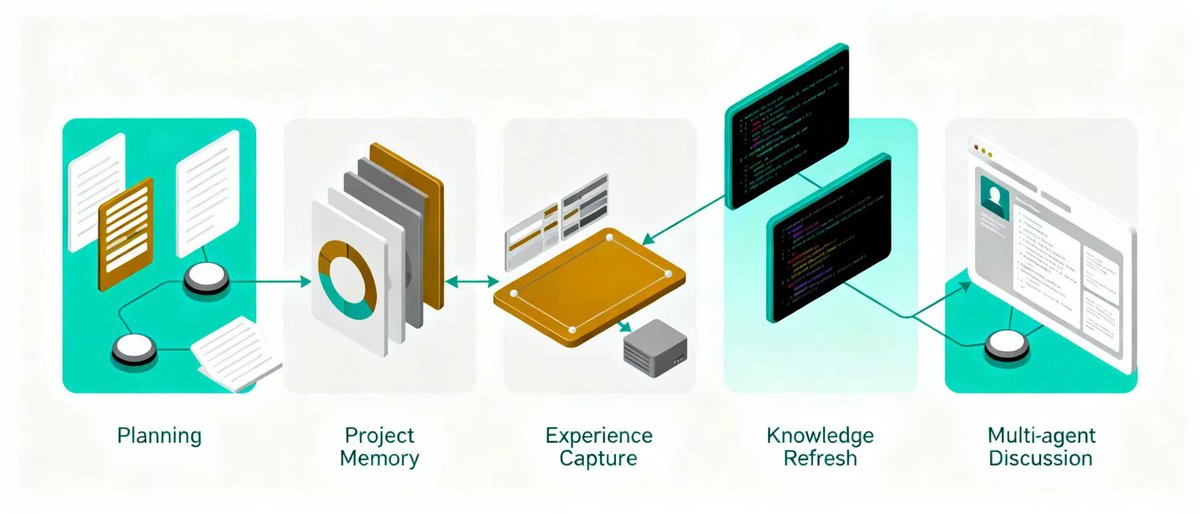
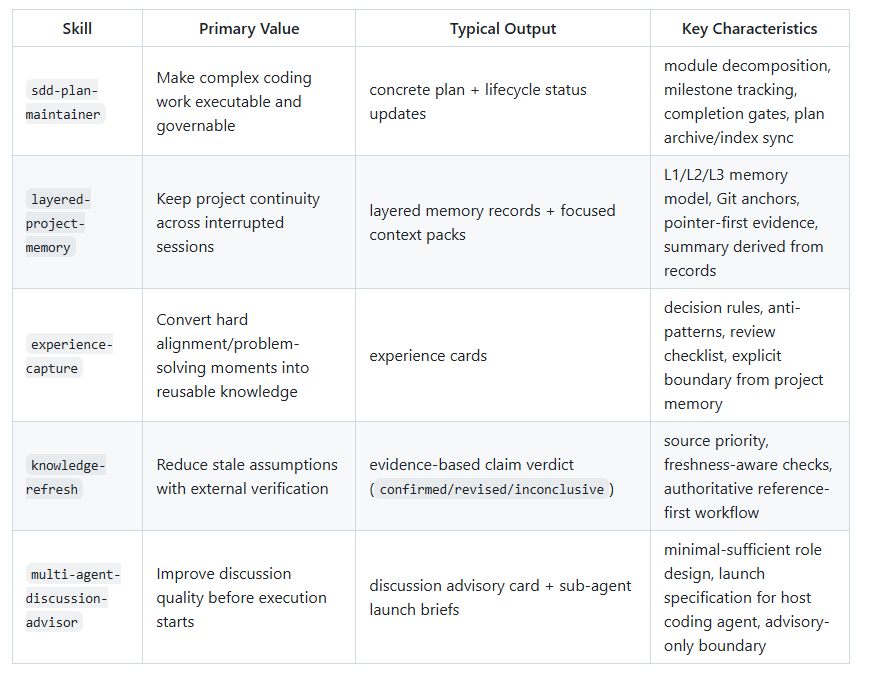
Based on recent vibe coding practices, I’ve compiled 5 frequently used skills for your reference. I especially recommend "sdd-plan-maintainer", which I use frequently. GitHub project link: github.com/ChristopheZhao…
English





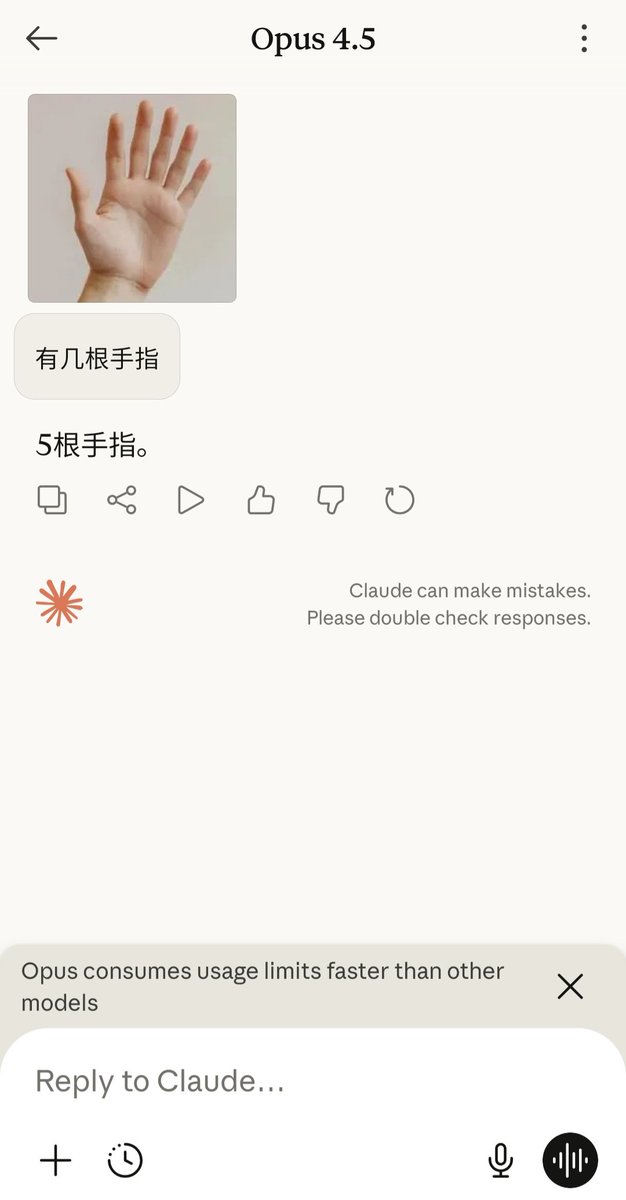

@frxiaobei 类比自动驾驶L3,人类要随时接管,复杂一点的任务,现在的模型还不支持长时自动化。现在的模型偏向over-confidence(也有对齐尽量解决问题的原因),无法识别哪些任务自己无法完成,需要人类接管。所以大多数是拆解模块化,文档驱动(SDD)模式开发,并行化在复杂任务上不现实,会让模块边界更不清晰。
中文

我最近有个小困惑,用 Agent 干活(尤其 AI coding)到底真提效了吗?
我自己的体感是这样的:
我基本只能单线程才能保持高效。一旦在不同任务/不同上下文之间切换,效率直接掉一截,脑子反复冷启动。
现在的 agent 做不到全自动。它跑到关键节点就得我确认:要不要继续?要不要改?
结果变成一种很尴尬的节奏:
我不能彻底放手去做别的,因为随时要回来接管;但我也没法一直盯着它,因为那更浪费。
中间那段 agent 执行时间,像被卡在进度条里:
去做别的吧,怕错过;不做吧,又干等。
所以这到底是效率提升,还是把执行时间省出来了,却把注意力成本加倍了?
想听听大家的真实用法:是怎么在 agent 跑的时候安排自己的?
中文
@YonglongT Congrats! I was wondering whether GPT-5.2 has a similar parameter count to GPT-5.1, or if it is larger. If you’re able to share, I’d really appreciate your insights.
English

Excited to see the effort I led brings significant improvements on visual reasoning! Also such a relief! I have been nervous since I was the biggest internal GPU burner for a while - what if I was wasting too many of my colleague's opportunities to improve the model? phew a bit
OpenAI@OpenAI
GPT-5.2 Thinking evals
English
@karpathy I think DeepSeek-OCR mainly verifies the effectiveness of compressing text within images for OCR tasks, but it doesn’t prove the effectiveness of general image-to-text compression. if this approach works on broader tasks like image captioning, can demonstrate truly effective
English

I quite like the new DeepSeek-OCR paper. It's a good OCR model (maybe a bit worse than dots), and yes data collection etc., but anyway it doesn't matter.
The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language person) is whether pixels are better inputs to LLMs than text. Whether text tokens are wasteful and just terrible, at the input.
Maybe it makes more sense that all inputs to LLMs should only ever be images. Even if you happen to have pure text input, maybe you'd prefer to render it and then feed that in:
- more information compression (see paper) => shorter context windows, more efficiency
- significantly more general information stream => not just text, but e.g. bold text, colored text, arbitrary images.
- input can now be processed with bidirectional attention easily and as default, not autoregressive attention - a lot more powerful.
- delete the tokenizer (at the input)!! I already ranted about how much I dislike the tokenizer. Tokenizers are ugly, separate, not end-to-end stage. It "imports" all the ugliness of Unicode, byte encodings, it inherits a lot of historical baggage, security/jailbreak risk (e.g. continuation bytes). It makes two characters that look identical to the eye look as two completely different tokens internally in the network. A smiling emoji looks like a weird token, not an... actual smiling face, pixels and all, and all the transfer learning that brings along. The tokenizer must go.
OCR is just one of many useful vision -> text tasks. And text -> text tasks can be made to be vision ->text tasks. Not vice versa.
So many the User message is images, but the decoder (the Assistant response) remains text. It's a lot less obvious how to output pixels realistically... or if you'd want to.
Now I have to also fight the urge to side quest an image-input-only version of nanochat...
vLLM@vllm_project
🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support. 🧠 Compresses visual contexts up to 20× while keeping 97% OCR accuracy at <10×. 📄 Outperforms GOT-OCR2.0 & MinerU2.0 on OmniDocBench using fewer vision tokens. 🤝 The vLLM team is working with DeepSeek to bring official DeepSeek-OCR support into the next vLLM release — making multimodal inference even faster and easier to scale. 🔗 github.com/deepseek-ai/De… #vLLM #DeepSeek #OCR #LLM #VisionAI #DeepLearning
English
@czech_pawel i think this design risks model collapse when training on self-generated data. The paper mitigates this via external labels and verifiable rewards. However, replacing external labels with model-synthesized data (mentioned in limitations) would reintroduce self-degeneration risks.
English

BIG NEWS!
MIT just built an AI that rewrites parts of itself to get smarter. SEAL (Self-Adapting Language Models): it reads new info, turns it into its own notes, then updates its weights—self-directed learning. 1/ Thread

English
@VictorTaelin i think because the environment and memory desigh match what the model saw during training.
English

@bindureddy True,this contradicts the original purpose of the technological revolution—to liberate more working time, not to increase it.
English

It’s super weird for AI start-ups to be proud a 7 day work week culture
The whole point of AI is to increase productivity!
So why would you ever need for anyone to come in 7 days a week? 🤯🤯
English
Sora 2 has indeed generated a huge social response . The video itself has more information density, spreadability, and expressive power that can better capture everyone's attention, making video creation simpler and allowing creativity to be unrestricted, which is meaningful.
English