
Social Capital Inc
367 posts

Social Capital Inc
@socapinc
Building the distribution infrastructure for the world's most ambitious companies.
Katılım Eylül 2025
16 Takip Edilen2.3K Takipçiler
we're finally looking for someone who's not a head of growth lol
looking for ONLY 1 cracked brand designer. pay: 40LPA
to apply and learn more, read the job description 🧵
we've created 500m+ impressions for gamma, a16z, wispr flow, cartesia, airwallex and this list of generational clients is only headed upwards
we also have a referral bonus of ₹25k for anyone who gets us our next hire
English
Social Capital Inc retweetledi

We are ready to pay 50 LPA for a Head of Growth.
This role has been open for 6 months
Reason is simple: we need 10 of them.
Every Fortune 500 company launching something this decade needs an Apple-level launch on social media.
Right now they all build that machine from scratch: freelancers, interns, a head of growth who's never done it at this scale or has gone viral.
We at @socapinc are building the virality distribution infrastructure they plug into instead.
We control half of all viral launches you see on X. With a team of just 20 folks. We've worked with companies like Gamma, Wispr Flow, Deel, Cartesia, and Lovable
And now we’re 10xing the model.
10x the virality. 10x the stakes. Which is why we're hiring 10 exceptional folks, not 1.
This is a forward-deployed role. Every month: one exceptional client, full ownership, and the chance to shape a company’s growth trajectory for years.
In a year, you'll have shaped the growth trajectory of 10-12 generational companies. Most conventional careers wait for a decade to touch this. No other product or agency offers a wider surface area of learning.
So if you're someone who fits this JD then apply here- binary.so/eAjd5GD
PS: read the entire JD below before applying, our bar is extremely high, and we're almost rejecting 99% applicants.

English

JUST IN: S&P 500 $SPX closes at new all-time high of 7,022.
English

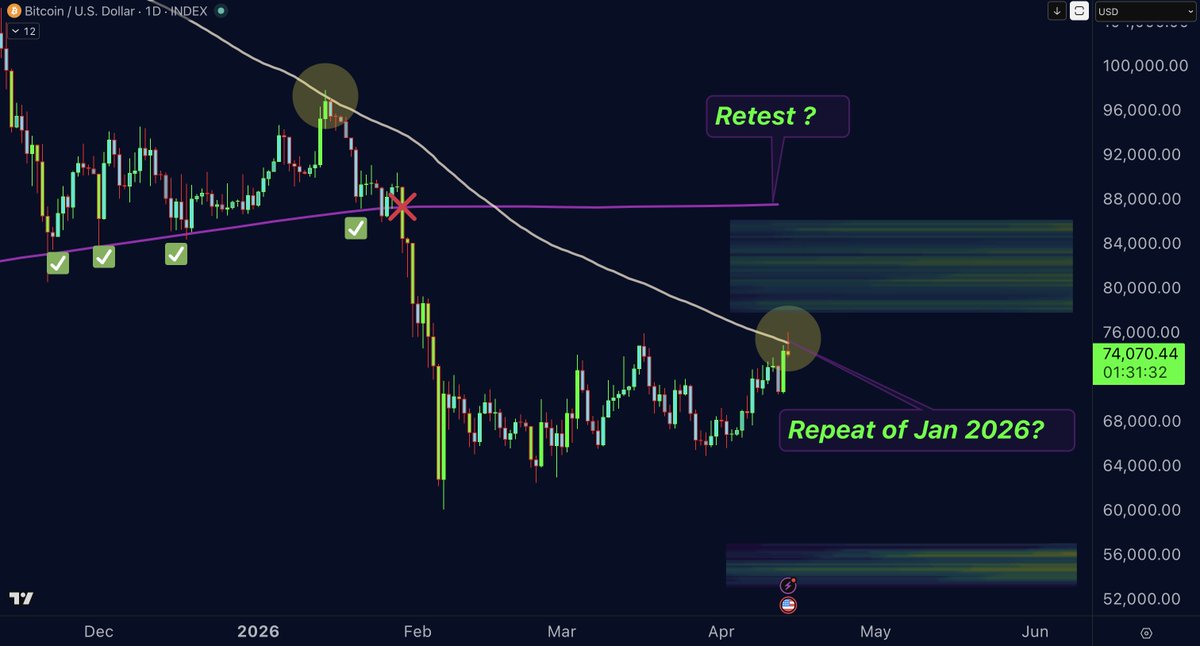
#Bitcoin: The chart that explains everything!
Everyone who is saying that we don't have liquidity below is lying or has no clue what they're talking about. In fact, we have tons of liquidity between the 53-57k region and tons of liquidity between the 76-85k region. Market makers usually hunt both sides and that's what makes the current setup dangerous for most traders who don't understand the full view.
The full view is as follows: Bitcoin is now at 74k, we have a strong resistance line (White Line) that was also rejected in January 2026 and led to the next big leg down. Bitcoin touched this resistance today and got rejected once again, but now we have the golden question: will market makers ignore the liquidity above? I doubt it. So that's why I placed my short orders right into the liquidity area between 79-84k in case market makers allow a visit, and while doing so, they can also retest the break of structure (Purple Line) that happened in January 2026. So the question that remains is: How high will market makers move before the next leg down? Is it going to be the white line or the purple line? The answer can be found in the liquidity below.
Since January I have been talking about a boring, continued sideways move happening for one reason only, to create more and more liquidity below. In January there was almost no liquidity below 60k, so why would market makers drop the price lower if there is nothing left to take? That's the moment market makers start moving price sideways to build liquidity on the downside. If market makers are not satisfied with the liquidity below, they will manipulate price with futures longs and let the masses believe the bullish momentum is back. That's the trap that is currently in play. It's like standing in front of two holes of the same depth, one requires more work to dig, the other is easier. That's exactly what the white and purple lines represent. And the longer you wait to dig, the more gold you find at the bottom. That's the reason for the sideways move we are seeing.
Overall, it's very important to understand that Bitcoin remains fully bearish. We will visit lower targets, and right now we are inside a bullish trap, the only open question is whether that trap ends at the white line, or whether market makers take the liquidity higher and end it at or near the purple line. That question can't be answered right now, but we will have more clarity once we see how price reacts at the white line, which has been rejected so far. This is why I said the sideways move would take a long time. Most people didn't expect it to drag into April, but I kept saying it would take 3 to 4 months. The decision point is now very close.
Join DrProfitPremium: whop.com/joined/drprofi…
English


$BTC update:
Price is rotating towards our $65k level for the week.
On the higher timeframe, this could still likely develop a big boring range throughout April too. At least, that's where I see Price Action going for now.
Swing traders will need to stay patient.

CrypNuevo 🔨@CrypNuevo
$BTC Sunday update: It feels like we'll be stuck in this range for the next month too. We could see some conflict escalation (uncertainty) next week that could trigger a new visit to the range lows where an interesting 4h long wick still sits there. Let's analyse: 🧵↓(1/6)
English

BREAKING:
🇺🇸 US Initial Jobless Claims:
Actual: 207k
Expected: 215k
English

I’ve been thinking about this a lot lately - Agentic Coding and framework choice.
As someone who’s comfortable with TypeScript with Nest, C# with .Net Core, Python Fast API, and Go, when it comes to building a bunch of APIs, I’ve found myself pausing less to ask can I build this in any of these stacks? and more to as to which one am I actually choosing, and why?
Because with agentic coding, the equation feels like it’s changing. The value seems to be shifting away from just how fast you can write code by hand, and more toward how well you can think through systems, make good engineering decisions, and work in a way that lets you build and adapt confidently.
So for me, stack choice starts to feel less like a question of personal coding preference and more like a question of leverage. Which ecosystem is the most versatile? Which codebase will be easiest to read, understand, and safely change later? Which stack will make the system easier to operate and maintain over time?
I don’t think the takeaway is that coding skill no longer matters, it does. It’s more that code comprehension, design judgment, and maintainability may matter more now than raw implementation speed.
That’s what makes the question interesting to me nowadays... - Not just how do I build the APIs? but which stack actually gives me the best long term leverage?
Rhetorical Questions...
English
English

Looking forward to being on a panel with the one and only @JeffBooth at @BTCPrague.
Get your discounted passes with code HODL 🧡
BTC Prague@BTCPrague
AI, robotics, Bitcoin - they are a perfect symbiosis. They accelerate each other. In that world, you get richer and richer, even if you do nothing." THE philosopher of Bitcoin is coming to Prague. @JeffBooth - entrepreneur, best-selling author of The Price of Tomorrow, founding partner of Ego Death Capital, board member at Fedi - takes the main stage at BTC Prague in June. 🔥 3 MainStage Panels 🔥 VIP Stage Fireside chat
English
Social Capital Inc retweetledi

amazing turnout at the @socapinc x @lightspeedindia event!
hottest high-agency growth crowd in all of blr + met some amazing folks + gave everyone a taste of what's cooking behind what will be the world's most legendary distribution infrastructure company coming out of india 🇮🇳
we're actively hiring cracked growth folk/generalists/creative directors at @socapinc. if you think you're kickass, come join us [instructions in thread]




English
English
Latest News Block just dropped.
Iran War: 21 hours of peace talks collapsed and Trump declared a naval blockade on the most important energy chokepoint on earth.
The New York Times thinks they've found Satoshi (wrong!).
Morgan Stanley's Bitcoin ETF smashed every debut record in the firm's history.
Strategy's $STRC traded $526 million in a single day.
Everything you need to know in the time it takes to mine a block.

English
THIS IS HUGE FOR CRYPTO.
🇺🇸 Stablecoin transactions could soon be “TAX-FREE” in the U.S.
This comes as part of the revised PARITY Act crypto tax bill.
“In the case of any sale of a regulated payment stablecoin, no gain or loss shall be recognized on such sale”
The bill removes the prior $200 threshold for small crypto transactions and sets a $1 cost basis for certain exchange.



English

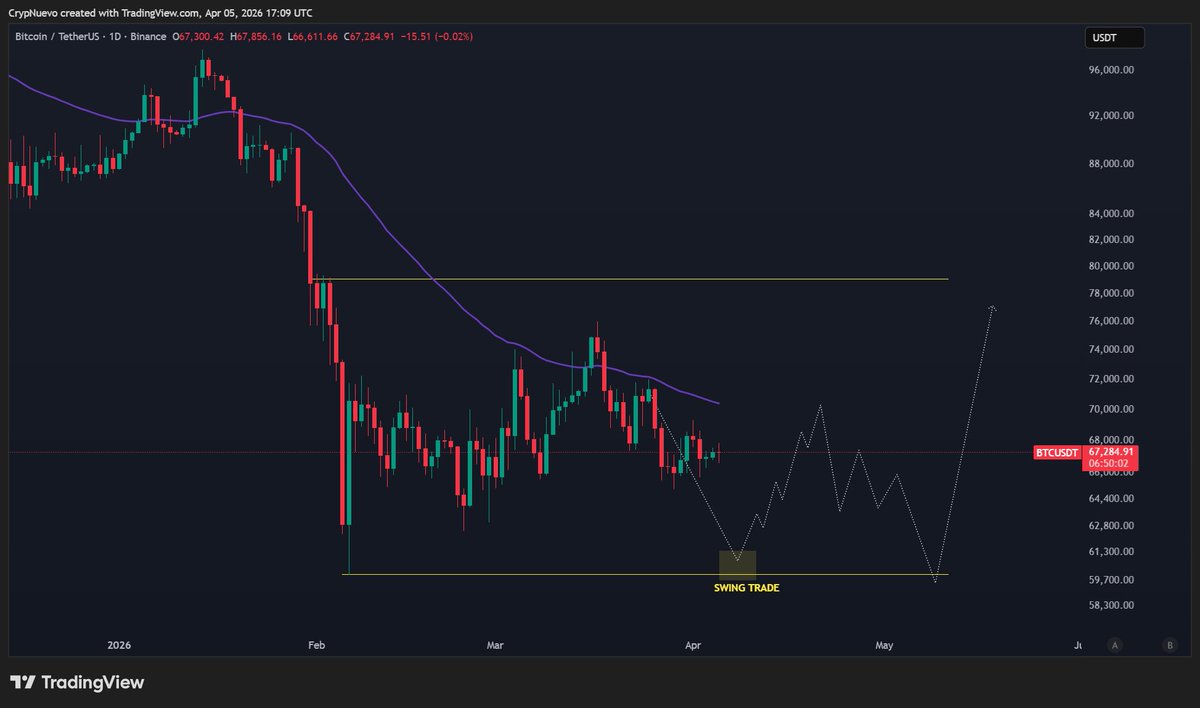
$BTC Sunday update:
Difficult conditions to trade as Price Action is basically driven by the US-Iran war and Trump's tweets.
Therefore, I'm only looking to trade the extremes of this range. For now, I'm favoring the range lows to hit first, where I'll look for longs.
🧵↓(1/5)
English
#Bitcoin: The big bullish trap is in the making and I’m profiting from this move with the long from 71k, and yet I understand it’s a trap and a sharp downside move is going to follow. Don’t get tricked, this upside move will end up in a massive downside move!
English

IT'S OVER.
The US Navy is moving to blockade the Strait of Hormuz. Iran has threatened to respond by taking the Bab el-Mandeb. C-17s are flooding US bases in the region right now.
The next move changes everything.
LIVE in 1 HOUR.
[link in comments]
English

“الكريبتو مرّ بسنة صعبة… ربما يجب أن نطلق شيئًا يصلحه.”
لما يقول هذا الكلام رئيس المنتجات في X… أكيد في شيء قادم 👀
شنو تتوقعون X تطلق؟!
Nikita Bier@nikitabier
Crypto has had a rough year. Maybe we should launch something to fix it.
العربية