Sabitlenmiş Tweet

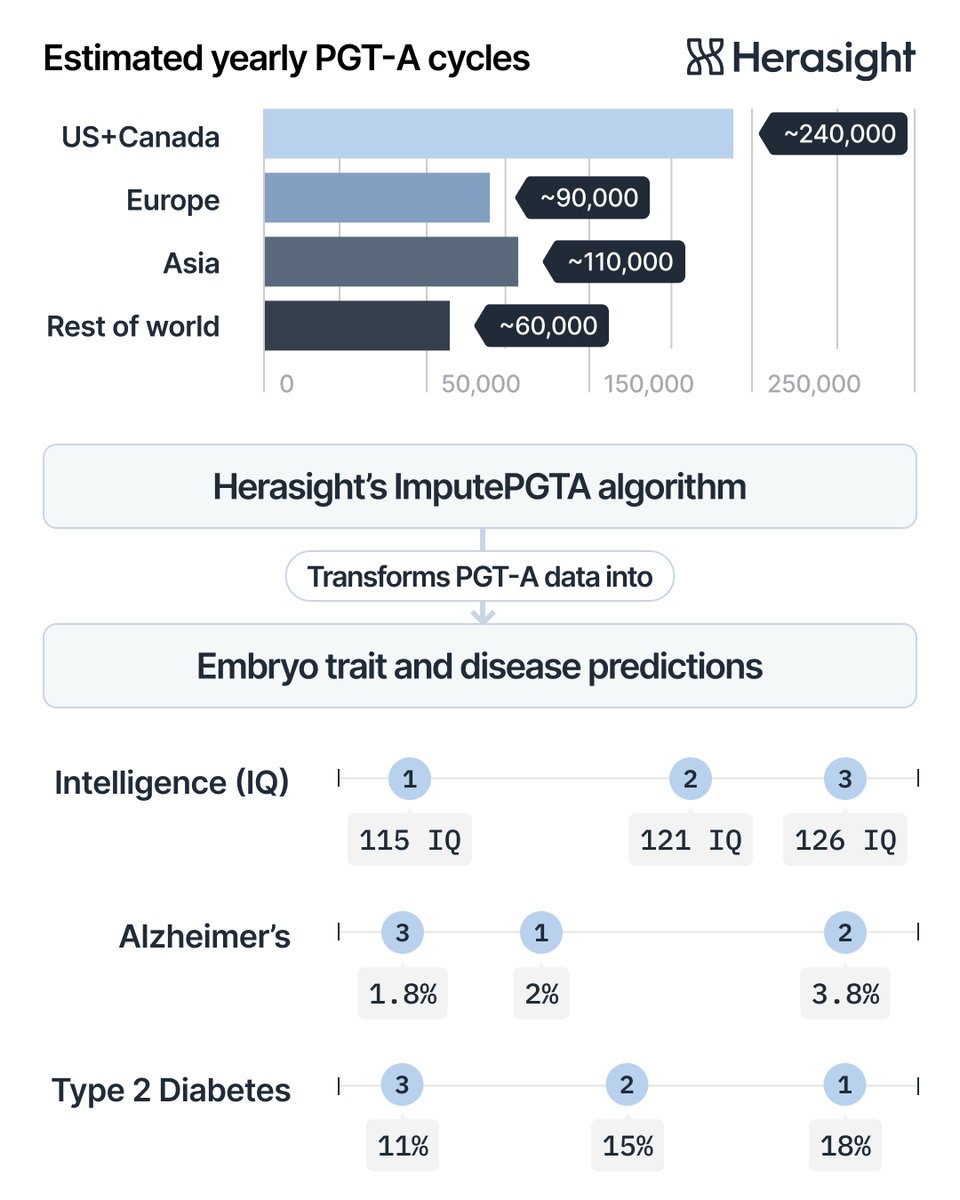
Today we reveal CogPGT, the world’s most powerful genetic predictor of IQ.
We achieve a correlation with IQ of 0.51 (0.45 within-family). Herasight customers can boost the expected IQ of their children by up to 9 points by selecting the embryo with the highest CogPGT score. 🧵

English