
Stefano Esposito
55 posts

Stefano Esposito
@StefanoEsp
phd student @ uni tübingen 3D computer vision
Tuebingen, Germany Katılım Ocak 2026
125 Takip Edilen30 Takipçiler


@DallenFrutchey @justinryanio How did they find 10.000 faces?
English

Apple just dropped a research paper called HeadsUp days before WWDC.
Trained on 10,000+ real faces to reconstruct a fully animatable 3D Gaussian Splat that you can rotate and light.
Excited to see Personas in visionOS 27.
English
Stefano Esposito retweetledi

It is getting genuinely difficult to keep track of all of the names of AI products being unveiled. In the last hour, Google's unveiled Google Pics (which is not Google Photos), and updates to Google Flow, Nano Banana, Veo (all media generation), Google Antigravity, Gemini Spark, Gemini Omni, Gemini 3.5 Flash
English
Stefano Esposito retweetledi

📢📢📢 Velox 🚀: Learning Representations of 4D Geometry and Appearance
In our #CVPR2026 paper, we introduce a method for learning a native 4D representation, useful for many downstream tasks, such as video-to-4D, 3D tracking, cloth simulation, and others!
🌐: apple.github.io/ml-velox
📝: arxiv.org/abs/2605.04527
English
Stefano Esposito retweetledi

AI allows the team to focus on things that really matters. Who cares about the exact placement of each rock in the ground for example. AI can be used for creating props, so that human artists have more time to create hero assets and polish them.
100% AI clone of GTA6 of course makes no sense at all. People with no passion in games will not make a good game with AI tooling. You need a lot of playing and iteration to make anything good. Original wins over clones for this reason. More passion was put into it.
I don't believe people will ever make money single shotting games. There's always somebody else who will be willing to two-shot, etc. More passion and more polish wins. If you aren't willing to spend more than one prompt creating a game, I bet you aren't willing to spend any more time marketing it or building the community.
Devin Nunes' Cattle Dog 🇺🇦 🇪🇺🇺🇸🇨🇦@Kaos_Vs_Control
“Creativity” from a tech CEO (*Note: Great points but horrific music).
English
@Meta @RealityLabs @haofeixu @GerardPonsMoll1 🔗 naamapearl.github.io/learn2splat/
📄 arxiv.org/abs/2605.15760
💻 Code and checkpoints coming soon!
English
📢 New paper out!
We introduce Learn2Splat — a meta-learned optimizer for 3D Gaussian Splatting.
⚡ Faster early convergence than Adam
🔁 Stable over long training horizons (no LR schedules!)
🌍 Zero-shot generalization across scenes & resolutions
1/6 🧵
English
Stefano Esposito retweetledi

🧟♂️ Introducing FrankenMotion: Part-level motion generation with unified Spatial-Temporal Control!
From fine-grained bodypart descriptions to high-level action goals, we enable you to compose distinct elements into coherent motions.
🔗 Project Page: coral79.github.io/frankenmotion/
English
Stefano Esposito retweetledi

Do we really need massive curated 3D scene data for interactive world generation?
#SAM3D, #WorldGen say yes.
We say no.
I-Scene learns better spatial knowlesge using only 25K randomly composed instances.
🔑 Key insight:
We reprogram the instance generator to infer support, proximity, and symmetry from purely geometric cues for generating interactive scenes.
🧠 Scene-context attention
👁️ View-centric space
🧱 Random composition beats expensive curation
🌐 luling06.github.io/I-Scene-projec…
💻 github.com/LuLing06/I-Sce…
🧵 Details below [1/6]
English
Stefano Esposito retweetledi

🚀🚀 Introducing Pixal3D (SIGGRAPH’26) — a new pixel-aligned image-to-3D generation paradigm for high-fidelity 3D asset creation.
Today’s Image-to-3D has become pretty good at producing plausible 3D assets. But plausibility is not enough. Fidelity is a hidden bottleneck.
❓A generated model may look “about right,” yet still fail to truly align with the input pixels. Can we make 3D generation as faithful as reconstruction, while still allowing it to complete the unseen?
Pixal3D is our answer.
💡We believe the core bottleneck behind fidelity is 2D–3D correspondence. Most 3D-native generators synthesize shapes in canonical space and inject image cues through cross-attention, forcing the model to implicitly search for which pixels correspond to which 3D regions.
🍀Pixal3D takes a different route. Instead of generating in canonical space, Pixal3D generates directly in pixel-aligned camera space — what you see is what you get. The generated 3D asset is aligned with the input view from the start.
☕️Meanwhile, Pixal3D introduces back-projection-based image condition scheme - explicitly back-projects multi-scale pixel features into 3D voxels, thus resolving the 2D-3D association problem. The input image is no longer just a prompt - it becomes a geometric anchor.
🚩Pixal3D shows that pixel-aligned 3D generation is not only feasible and scalable, but also significantly improves fidelity, pushing 3D-native generation closer to reconstruction-level faithfulness. It also naturally extends to multi-view and scene-level 3D generation.
✅Faithful to the input view. ✅Generative for the unseen.
Closer to reconstruction-level fidelity, with the creativity of 3D generation. Pixal3D also represents an effort towards the unification of 3D generation and reconstruction.
📢Paper, code, and demo are fully released — try it out and let us know your feedback!
🌐Project page: ldyang694.github.io/projects/pixal…
🤗Huggingface Demo:
huggingface.co/spaces/Tencent…
💻Code:
github.com/TencentARC/Pix…
📄Paper:
arxiv.org/abs/2605.10922
English
Stefano Esposito retweetledi

Stefano Esposito retweetledi

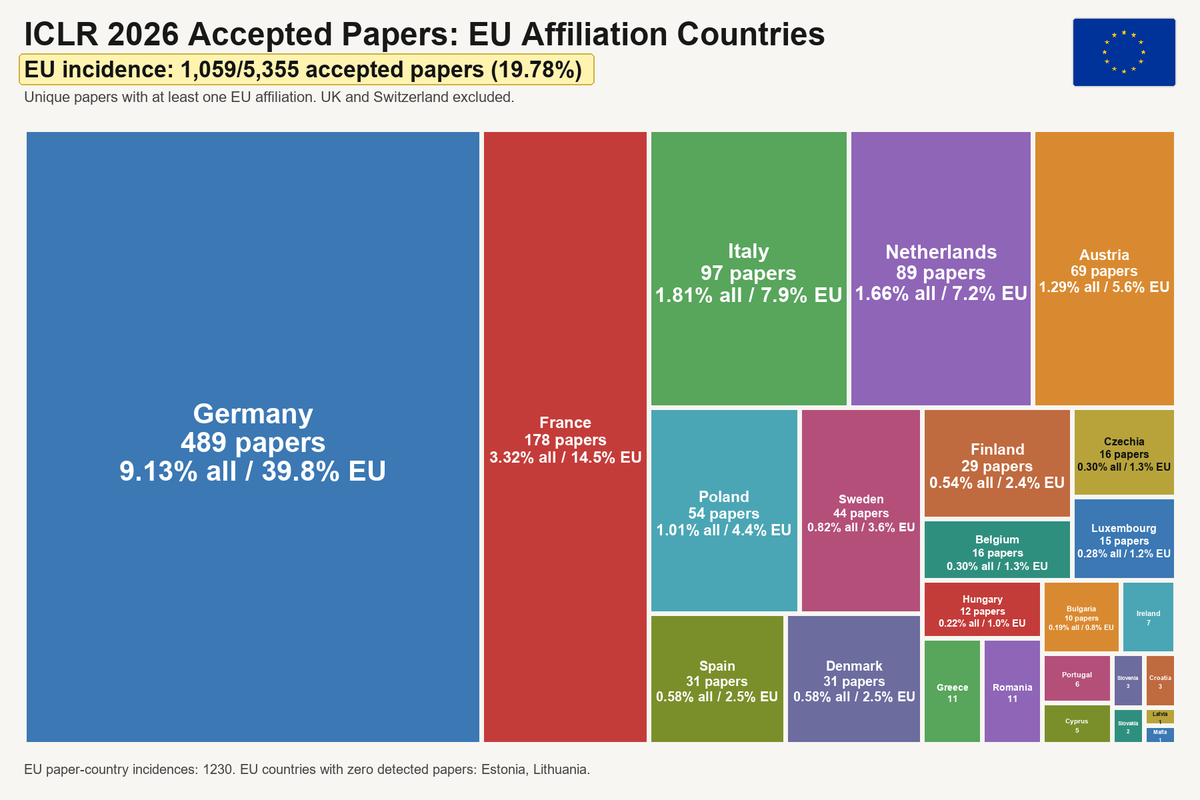
i ran an analysis of EU-affiliated papers at ICLR 2026. the picture is less negative than the original (quoted) treemap may suggest, but still, Europe needs to wake up.
1,059 out of 5,355 papers have at least one EU affiliation. that's a 19.78% incidence on all accepted papers.
If we count each paper once for every EU country represented among its authors, the total rises to 1,230 paper-country incidences.
Germany leads by a large margin, followed by France and Italy (daje). as an Italian, i'm genuinely happy to see Italy so high in the ranking, our investments in national talent is paying off.
this seems to correlate with the acceptance rates in competitive funding schemes like the ERC grants. i'd be curious to know whether similar patterns also appear in other non-AI fields, happy to hear thoughts from my @yacadeuro colleagues on this.
also, @EU_Commission, feel free to use the data.
personally i find it great to see Poland growing so strongly; there is real talent there. Austria is also becoming increasingly visible, helped by new, forward-looking institutions.
i'll rerun this analysis for ICML in a couple of months. curious to see whether the same pattern holds.
edit: fixed Austria counting.
ℏεsam@Hesamation
someone analyzed all 5000+ accepted papers at ICLR 2026, and it's a good signal who's pushing the research of AI: > China has surpassed the US with 43.7% of the papers > Europe's contribution is surprisingly small (5.3% including UK)
English
Stefano Esposito retweetledi

This guy should check his DMs if he wants to make a lot of money

English
Stefano Esposito retweetledi

A bunch of folks have been building machine learning models that turn a photograph into a 3D environment made of Gaussian splats (read: blobs of color floating in space).
Cool technology & a very admirable effort. But marketing these as "world models" seems wrong.
More accurate would be to say that they are a riff on the broader class of image-conditioned 3D generators, with a somewhat different flavor of condition image and output representation.
As far as world modeling, they don't make great predictions about how the natural world looks or behaves. (Even for, say, a chair behind a table.)
Again: I love the technology. Super cool creative stuff. I don't love the marketing and hype around it.
English
Stefano Esposito retweetledi

Streamable volumetric video is here on Apple Vision Pro. I still can’t believe it.
English