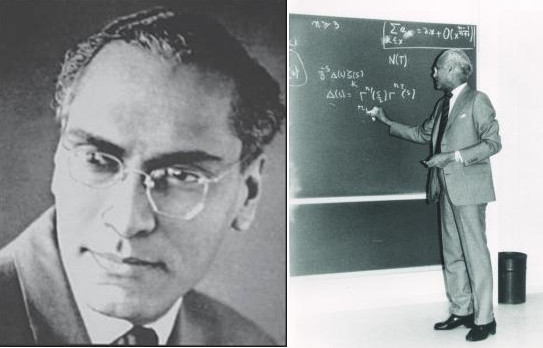@chidu_narayanan@Fintech03 That is what I remarked earlier today. Some people choose to live that way, keep themselves away from the limelight. Eventually, people would come to know of them through their work.
Next in who after the Ramanujan Series? He was the man Homi Bhabha trusted to build the Silo of Indian genius. While Ramanujan was the lightning, Komaravolu Chandrasekharan (1920-2017) was the lightning rod. He spent his life in the absolute backend of Number Theory, solving the mysteries of the Zeta Function: the math that now safeguards every digital secret in the world. He was the President of the world’s mathematicians & a King in the halls of Zurich, yet he lived to 96 as a total Ghost in his own country. He did not just solve eqns; he built the TIFR, the very sanctuary where every other Indian ghost I have discussed found a home. He is the Architect who designed the house of Indian logic, then quietly walked out the back door into the silence of history.
Born in 1920 in Andhra Pradesh, KSC was a protégé of Ananda Rau. Along with Homi Bhabha, he was the primary architect of the Tata Institute of Fundamental Research (TIFR). While Bhabha was the Face, KSC was the Engine. He was the 1 who personally recruited the ghosts we have been discussing: K. G. Ramanathan, M. S. Narasimhan, C. S. Seshadri, Raghavan Narasimhan, & others.
He spent time at the Institute for Advanced Study (IAS) in Princeton, working directly with Hermann Weyl (Weyl recommended him to Bhabha) .
KSC did not just solve 1 problem; he mastered the distribution of primes & the Riemann Zeta Function. He worked on Exponential Sums & the Geometry of Numbers. His work explains how numbers are distributed across the universe. Why does this matter? Because Modern Cryptography & Quantum Chaos Theory depend on the randomness & spacing of these numbers.
He wrote the definitive textbooks on Number Theory that are still the gold standard at the UChicago & the ETH Zurich. He turned the Intuition of Ramanujan into a Global Rigor that computers could finally use.
In 1965, he moved to Switzerland to become a prof at ETH Zurich (Einstein's alma mater). He lived there for over 50 yrs, becoming a Shadow Giant. He served as the President of the International Mathematical Union (IMU). This is effectively the highest administrative post in world mathematics. Yet, while he was making decisions that shaped the direction of global math, he was almost entirely forgotten in his home country.
He lived to the age of 96. To his neighbors in Switzerland, he was a polite, incredibly intellectual Indian gentleman. To his relatives in India, he was the Granduncle in Zurich who did some high-level math. No one realized he was the man who had essentially curated the survival of Indian mathematics after 1947.
@Fintech03 When people talk of TIFR, they think of H J Bhabha. Not many seem to know the great contributions made by D D Kosambi and Komaravelu Chandrasekharan. Is it do with their personality, the way they chose to live? I am new to this series. Have you written about Dr S S Pillai?
MIT just made every AI company's billion dollar bet look embarrassing.
They solved AI memory. Not by building a bigger brain. By teaching it how to read.
The paper dropped on December 31, 2025. Three MIT CSAIL researchers. One idea so obvious it hurts. And a result that makes five years of context window arms racing look like the wrong war entirely.
Here is the problem nobody solved.
Every AI model on the planet has a hard ceiling. A context window. The maximum amount of text it can hold in working memory at once. Cross that line and something ugly happens — something researchers have a clinical name for.
Context rot.
The more you pack into an AI's context, the worse it performs on everything already inside it. Facts blur. Information buried in the middle vanishes. The model does not become more capable as you feed it more. It becomes more confused. You give it your entire codebase and it forgets what it read three files ago. You hand it a 500-page legal document and it loses the clause from page 12 by the time it reaches page 400.
So the industry built a workaround. RAG. Retrieval Augmented Generation. Chop the document into chunks. Store them in a database. Retrieve the relevant ones when needed.
It was always a compromise dressed up as a solution.
The retriever guesses which chunks matter before the AI has read anything. If it guesses wrong — and it does, constantly — the AI never sees the information it needed. The act of chunking destroys every relationship between distant paragraphs. The full picture gets shredded into fragments that the AI then tries to reassemble blindfolded.
Two bad options. One broken industry. Three MIT researchers and a deadline of December 31st.
Here is what they built.
Stop putting the document in the AI's memory at all.
That is the entire idea. That is the breakthrough. Store the document as a Python variable outside the AI's context window entirely. Tell the AI the variable exists and how big it is. Then get out of the way.
When you ask a question, the AI does not try to remember anything. It behaves like a human expert dropped into a library with a computer. It writes code. It searches the document with regular expressions. It slices to the exact section it needs. It scans the structure. It navigates. It finds precisely what is relevant and pulls only that into its active window.
Then it does something that makes this recursive.
When the AI finds relevant material, it spawns smaller sub-AI instances to read and analyze those sections in parallel. Each one focused. Each one fast. Each one reporting back. The root AI synthesizes everything and produces an answer.
No summarization. No deletion. No information loss. No decay. Every byte of the original document remains intact, accessible, and queryable for as long as you need it.
Now here are the numbers.
Standard frontier models on the hardest long-context reasoning benchmarks: scores near zero. Complete collapse. GPT-5 on a benchmark requiring it to track complex code history beyond 75,000 tokens — could not solve even 10% of problems.
RLMs on the same benchmarks: solved them. Dramatically. Double-digit percentage gains over every alternative approach. Successfully handling inputs up to 10 million tokens — 100 times beyond a model's native context window.
Cost per query: comparable to or cheaper than standard massive context calls.
Read that again. One hundred times the context. Better answers. Same price.
The timeline of the arms race makes this sting harder. GPT-3 in 2020: 4,000 tokens. GPT-4: 32,000. Claude 3: 200,000. Gemini: 1 million. Gemini 2: 2 million. Every generation, every company, billions of dollars spent, all betting on the same assumption.
More context equals better performance.
MIT just proved that assumption was wrong the entire time.
Not slightly wrong. Fundamentally wrong. The entire premise of the last five years of context window research — that the solution to AI memory was a bigger window — was the wrong answer to the wrong question.
The right question was never how much can you force an AI to hold in its head.
It was whether you could teach an AI to know where to look.
A human expert handed a 10,000-page archive does not read all 10,000 pages before answering your question. They navigate. They search. They find the relevant section, read it deeply, and synthesize the answer.
RLMs are the first AI architecture that works the same way.
The code is open source. On GitHub right now. Free. No license fees. No API costs. Drop it in as a replacement for your existing LLM API calls and your application does not even notice the difference — except that it suddenly works on inputs it used to fail on entirely.
Prime Intellect — one of the leading AI research labs in the space — has already called RLMs a major research focus and described what comes next: teaching models to manage their own context through reinforcement learning, enabling agents to solve tasks spanning not hours, but weeks and months.
The context window wars are over.
MIT won them by walking away from the battlefield.
Source: Zhang, Kraska, Khattab · MIT CSAIL · arXiv:2512.24601
Paper: arxiv.org/abs/2512.24601
GitHub: github.com/alexzhang13/rlm
@Hsnshjaj@TheRocketMediaX Ever heard of Yellapragada SubbaRow? He was a 'Telugu.' Many schoolkids who won the Spelling Bee contest in the US are from Telugu-speaking families. Prof. C R Rao, the great statistician, is another.
Meet Subhash Khot !
(IIT-JEE Rank 1 & Legendary Computer Scientist from India)
> Born & brought up in Maharashtra, 1978
> Two-time silver medallist at the International Mathematical Olympiad (1994, 1995)
> Did his BTech in Computer Science from IIT Bombay
> And Pursued PhD from Princeton University Under Sanjeev Arora (IIT-JEE Rank 1 of 1986)
> Later joined New York University, where he is currently a professor at the Courant Institute
Today, he is one of the world’s leading minds in theoretical computer science.
> Has contributed significantly to computational complexity
> And is best known for his Unique Games Conjecture (UGC)
> One of the most important open problems in theoretical computer science
For his contributions, he has received several prestigious recognitions & fellowships including:
> Alan T. Waterman Award (2010)
> Rolf Nevanlinna Prize (2014)
> MacArthur Fellowship (2016)
> Royal Society Fellowship (2017)
> National Academy of Sciences (2023)
From a small town in India to shaping the foundations of modern theoretical computer science, Prof. Khot’s journey is a testament to deep thinking, persistence, and world-class research.
@Meets_98778@TheRocketMediaX Har Gobind Khorana and S Chandrasekhar went to the US and became Nobel Laureates. Y Subbarao migrated to the US and invented a host of life-saving drugs. Serving the world is what is important. Watson and Venky Ramakrishnan left the US to work in the UK, and both won the Nobel.
@Meets_98778@TheRocketMediaX Ramanujan served as a clerk in India. When he went to Cambridge, he became known as one of the all-time greats in math. Most city-dwellers in today's India are migrants from villages, some of them in the back of the beyond. How many of them serve their villages?
@Shakt1_@TheRocketMediaX China faced the same problem. But they solved it well. The Govt systematically facilitated the return of the natives and they were given facilities and environment very nearly equal to what they had in the West. We also had returnee programmes like TOKTEN but didn't succeed.
@TheRocketMediaX Indian tax payer subsidized his studies for American corporations to gain talent, and in return Indians are called as low skilled labor!
@anxious599@TheRocketMediaX Tell us more about Ashish Vaswani and Niki Parmar. Being born in a small town/village/hamlet or into a family in the lower rungs of India's obnoxious caste hierarchy need not be an insurmountable barrier to doing great things in later life.
@karthik2k2@NMenonRao Thanks very much Mr Karthik Balachandran (and Ms Nirupama Menon Rao). Honestly, most Indians of the current generation, including many scientists, may not have heard of Dr Rehman (and Dr Y Subbarao). At least there is a biography of Dr Rao. Is there one of Dr Rehman?
Those who saw’A Beautiful Mind’, would remember that John Nash’s doctoral thesis had just 26 pages and 2 references, yet it was instrumental in advancing “Game theory”. What if I told you there is a scientist whose achievement is so astounding that he is perhaps the only Indian to “create” an intersectional branch of science? What if I told you that every year, his name echoes across the hallowed halls of science in foreign lands, but most of our students haven't even heard of him?
Aneesur Rahman was born in Hyderabad in British India in 1927. His father was a professor and a philanthropist. His family generously donated their property for the creation of Urdu Hall in Hyderabad. His maternal uncle was a professor too. Rahman had a natural flair for subjects that would terrify ‘normal’ students — maths and physics. After getting BSc in Mathematics, he went on to get Tripos in Mathematics and Physics at the prestigious Cambridge University in the UK. From there, he went to Louvaine University in Belgium and got DSc in Physics under Professor Mannenbeck. It’s here that Rahman met a Chinese student Yueh-Erh Li who was doing MD( called Dr Jady by friends). They fell in love and got married.
He came back to teach in Osmania university along with his wife. Soon after, he developed interest in the structure of water molecule - especially the polarisation of the hydrogen atom. Unfortunately research in India was at infancy in those days and Dr Rahman realized he was a whale in a tiny pond. He had to move to the ocean. He joined the Argonne National Laboratory in Illinois.
His foundational paper in 1964 birthed “molecular dynamics” , one of the two pillars on which a vast body of computational physics rests.(the other is Monte Carlo method). His equation made it possible to calculate the trajectory of large number of interacting atoms with ease.
His work, like Ramanujan’s , was so ahead of his time - that even today, potential applications are being discovered. The Nobel prize in physics for 2013 went to Karplus, Levitt and Warshel whose work depended heavily on Dr Aneesur Rahman’s.
Some say there is an inverse association between genius and compassion -Dr Rahman was a prominent exception. He was known not just for his intellect, but also kind nature and mentored many students all over the world. His quiet, unassuming nature made him a much loved professor — and he remained so, until he got Non Hodgkin’s lymphoma — a cancer that took him away from us prematurely, at the age of 59. Perhaps he might have got a Nobel, if only he had lived longer.
American Physical Society honors him as the father of computational physics and has instituted an annual award in his name.
As a doctor with little idea of theoretical physics, writing Dr Aneesur Rahman’s portrait has been difficult , because of the complex nature of his work that straddles so many areas of science : mathematics, physics, computer science and chemistry. His equations are mind boggling, even intimidating, but
what I do understand is this : Dr Rahman didn't just have a beautiful mind, but also a beautiful heart.
@dilip2904@karthik2k2 Please name the more than hundred Indian scientists, who in your opinion, should have been awarded the Nobel Prize in Phys, Chem and Medicine.
@karthik2k2 if one makes a list, there are at least 100 Indians who have been denied the Nobel Prize in Physics Chemistry Medicine just because they were Indians.
@OpenAlex_org I have forgotten my OpenAlexAPI key and I want to generate a new one. Please tell me how to go about it. I would prefer step by step instructions. Thanks.
Today's OpenAlex Webinar is at 12pm EDT (Thur, Apr 11): "The OpenAlex API Part 1: Getting Started"! It will be a basic introduction to the API, led by Kyle. Join us! #openalex-api-part-1" target="_blank" rel="nofollow noopener">help.openalex.org/events/webinar…
@SuchitNanda 2. Actually, we really know nothing, contrary to what many people imagine. We learn from people we meet and circumstances we find ourselves in. It is the external world which shapes your mind and character. There are rare exceptions, the Swayambus.
@SuchitNanda I know it well. I learnt first from my mother, then from my Children's Home owner/Head/Director/Chairman/Above all a caring person, when I was 5-7 years old. Then from many other teachers and of course, when I am in my mid-fifties from MSS.
@larrypress Because the American citizens, in their collective wisdom, made him the President of USA, and he went one step ahead and believes (and acts like) he is the monarch of the universe.
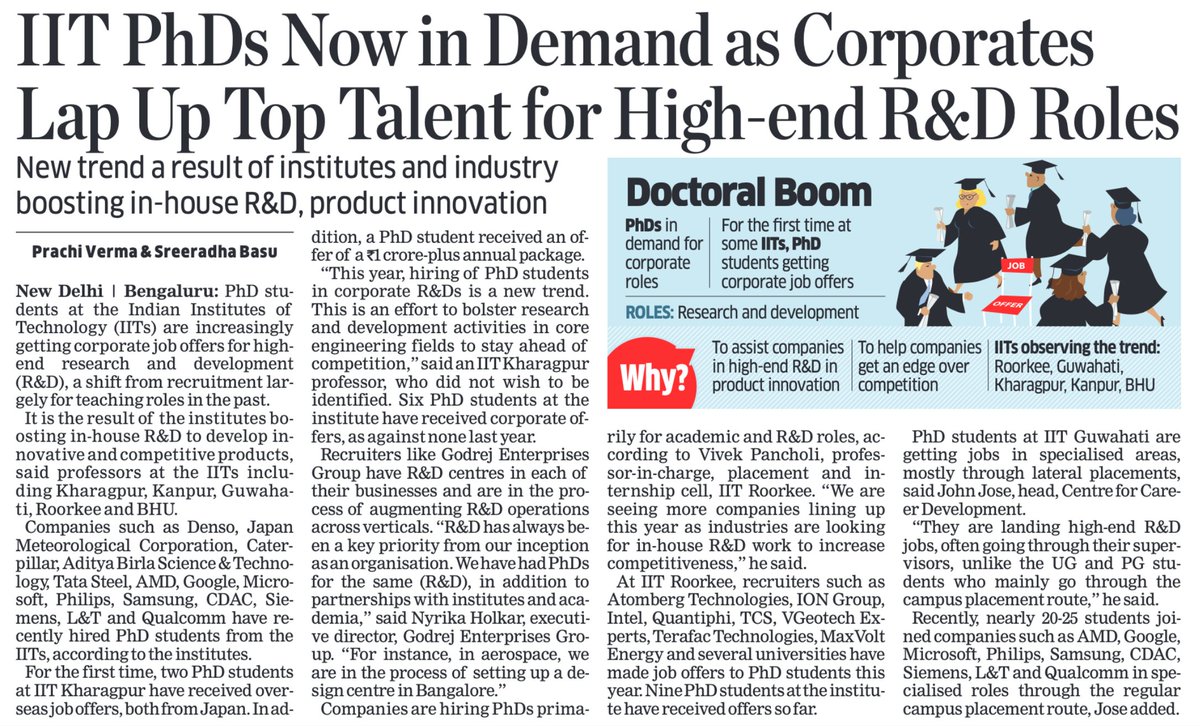
India has 1.4 billion citizens, yet only around 10,000 are pursuing PhDs in core sciences.
As industry begins to compete for high-end R&D talent, this is a strategic moment for policy to expand advanced STEM doctoral programs.
@Ananth_IRAS There was another, a bit less-known classic by Bartley and Bannerjee (I am not sure about the spelling of both names). It was the prescribed text for PUC students of Alagappa College, Karaikudi, TN, 1956-57 batch.
#DidYouKnow H. Martin, one of the authors of the famous Wren & Martin's High School English Grammar & Composition, taught at Aligarh Muslim University and even served as its Pro-Vice Chancellor in 1930-31?
Originally written in 1935 for the children of British officers in India, this book has stood the test of time and is still a go-to resource for teaching English grammar in schools across India. Co-written by H. Martin and P. C. Wren, it's a true classic!
#HMartin#PCWren#education#English#grammar
One of the simplest ways to relax your lower back before bed is gentle side-to-side movement.
Lying on your back, open your legs slightly and slowly swing them side to side about 60 times.
This helps release tension in the lower spine and hips.
#Zen#Buddhist story.... Chop wood. Carry Water
Core teaching is that enlightenment does not fundamentally change the ordinary tasks of life. Before enlightenment, you chop wood & carry water. After enlightenment you still chop wood & carry water.
#spiritual#gyan#spirituality