
Symlink
8 posts

I think this is incredibly and surprisingly bullish for DeepSeek
V3.2 is ≈50% of the compute of K2.5 and GLM-5, has lower capacity, and most of its training had been completed over a year prior. They still have the best code pretraining data.

You Jiacheng@YouJiacheng
interestingly, DeepSeek V3.2 has the best NLL/PPL on their internal codebase, but has the worst QA performance on their internal code-knowledge benchmark. probably QA rephrase pretraining data help K2.5 base to have a strong QA perf.
English
@zephyr_z9 Despite these benchmarks, when it comes to real work, Opus and Sonnet are so much better for agentic coding right now. I'm not sure if it's the Claude Code harness making them better, but it's a night and day difference for me compared to the top open source models with OpenCode.
English

SWE Rebench finally got fixed
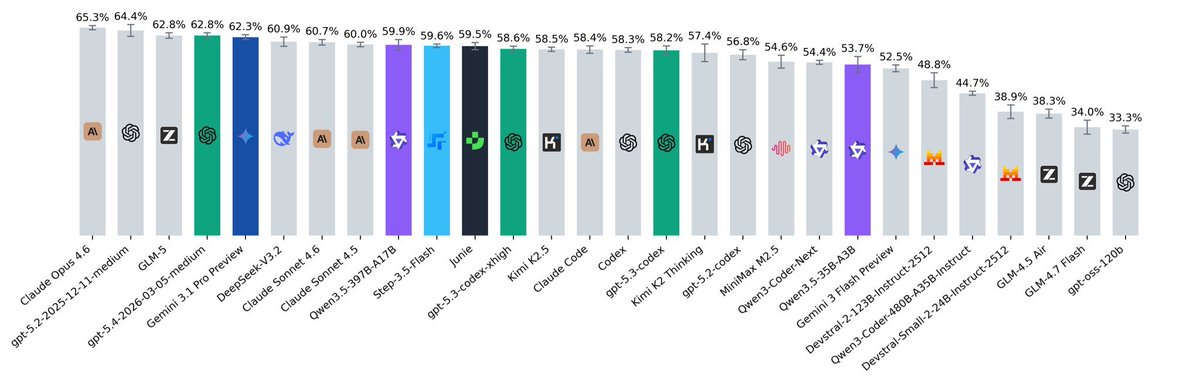
Ibragim@ibragim_bad
🚨 SWE-rebench update! SWE-rebench is a live benchmark with fresh SWE tasks (issue+PR) from GitHub every month. updates: > we removed demonstrations and the 80-step limit (modern models can now handle huge contexts without getting trapped in loops!). > we added auxiliary interfaces for specific tasks like in SWE-bench-Pro to evaluate larger tasks fairly, ensuring valid solutions don't fail just because of mismatched test calls. insights: > Top models perform similarly. Among open-source options, GLM @Zai_org shows strong results, and StepFun @StepFun_ai is very cheap for its performance level ($0.14 per task). > GPT-5.4 shows high token efficiency, it ranks in the top 5 overall but uses the lowest number of tokens (774k per task) > Qwen3-Coder-Next & Step-3.5-Flash benefit massively from huge contexts. Qwen is an extreme case, averaging a wild 8.12M tokens. > We evaluated agentic harnesses (Claude Code, Codex, and Junie) and found a few things. Even in headless mode, they sometimes ask for additional context or attempt web searches. We explicitly disabled search and verified their curl commands to ensure they aren't just pulling solutions from the web. 🏆 You can find the full leaderboard here: swe-rebench.com 👾 Also, we launched our Discord! Join our leaderboard channel to discuss models, share ideas, ask questions, or report issues: discord.gg/V8FqXQ4CgU
English
If Hunter-Alpha is V4 and it really has 1T tokens, that's very sad (unless it was trained on Ascends, which would suggest better models not constrained to 2-4K H800s to come soon. But still sad on the V4 side)
If it's something like Kimi-DSA/Xiaomi/GLM, that's better.
English
It didn't happen that Wednesday and it didn't happen this Wednesday, but now Whale is experiencing a freeze and that's my latest cope. They must be deploying V4… this must be it…
Praying to Sea Dragon King rn
Teortaxes▶️ (DeepSeek 推特🐋铁粉 2023 – ∞)@teortaxesTex
The modal day of DeepSeek update is Wednesday, around this time (it's 5 PM in Beijing, they've done most of the testing. Announcement, weights, tech report usually follow within 1-24 hours) It's happening.
English
@teortaxesTex The argument is more nuanced because DeepSeek is open weights and publishes all of their research. From a moral standpoint, using IP and sharing that freely is distinct from using IP and not contributing back to society.
English
Btw I strongly dislike the popular "frontier labs trained on the whole of internet, took our IP, so they're hypocritical to lash out at distillation" excuse. It lamely presupposes some original sin that later comers are exempt from. Does DeepSeek not train on CommonCrawl? come on
English
@teortaxesTex Reuter's is a trash tier publication that doesn't fact check their claims. I'm dubious. Recently they claimed that GLM-5 was trained completely on Huawei Ascends.
English
I think it's bullshit, but if DeepSeek has a Blackwell cluster in Inner Mongolia… bullish for V4
GIF
English
@hsu_steve I'm not sure this is true. The original source from these claims is glm5.net which has been disavowed by Z.ai as not an official Zhipu AI domain.
English

Gemini: The GLM-5 large language model was developed and trained entirely on domestically produced Huawei Ascend chips and the MindSpore AI framework, without the use of US hardware like NVIDIA GPUs.
Model Development & Training
Developer: Zhipu AI, a Chinese AI company that is a spin-off from Tsinghua University. The company is also known internationally as Z.ai after a 2025 rebranding.
Hardware Used: The entire training pipeline, from data processing to the final run, was conducted using Huawei's Ascend Atlas 800T A2 servers, which incorporate Huawei's in-house Ascend AI processors. This was a strategic move to demonstrate China's self-reliance in AI infrastructure amidst US export restrictions.
Z.ai@Zai_org
Introducing GLM-5: From Vibe Coding to Agentic Engineering GLM-5 is built for complex systems engineering and long-horizon agentic tasks. Compared to GLM-4.5, it scales from 355B params (32B active) to 744B (40B active), with pre-training data growing from 23T to 28.5T tokens. Try it now: chat.z.ai Weights: huggingface.co/zai-org/GLM-5 Tech Blog: z.ai/blog/glm-5 OpenRouter (Previously Pony Alpha): openrouter.ai/z-ai/glm-5 Rolling out from Coding Plan Max users: z.ai/subscribe
English

I doubt it's actually on par with 4.6, but I want to see Dario argue that. I want him to absolutely Karp out in an interview. Let him squirm in a chair, twitch, make irrelevant gestures, smirk, downplay it, then wail about export controls. Dario noises are music to my ears…
Okara@askOkara
"Sir, MiniMax just dropped MiniMax M2.5 and it's on par with Opus 4.6 while being 20x cheaper"
English