Sabitlenmiş Tweet

🚀 We are thrilled to release a new open-source Deep Research Agent, Cognitive Kernel-Pro, from Tencent AI Lab! We focus on building a fully open-source agent with (to the maximum extent) free tools, showcasing impressive performance on GAIA with Claude-3.7-sonnet and surpass the counterpart, SmolAgents by a large margin.
In addition, we study the training recipe for an open-source Deep Research Agent Foundation Model. We curate high-quality training data (queries, trajectories, and verifiable answers across web, file, code, and reasoning domains). Our finetuned Qwen3-8B (CK-Pro-8B) surpasses WebDancer and WebSailor with the similar model size on the text-only subset of GAIA.
📜 Paper: arxiv.org/pdf/2508.00414
🔧 Code: github.com/Tencent/Cognit…
🤗 Data & Model:
huggingface.co/datasets/Cogni…
huggingface.co/CognitiveKerne…
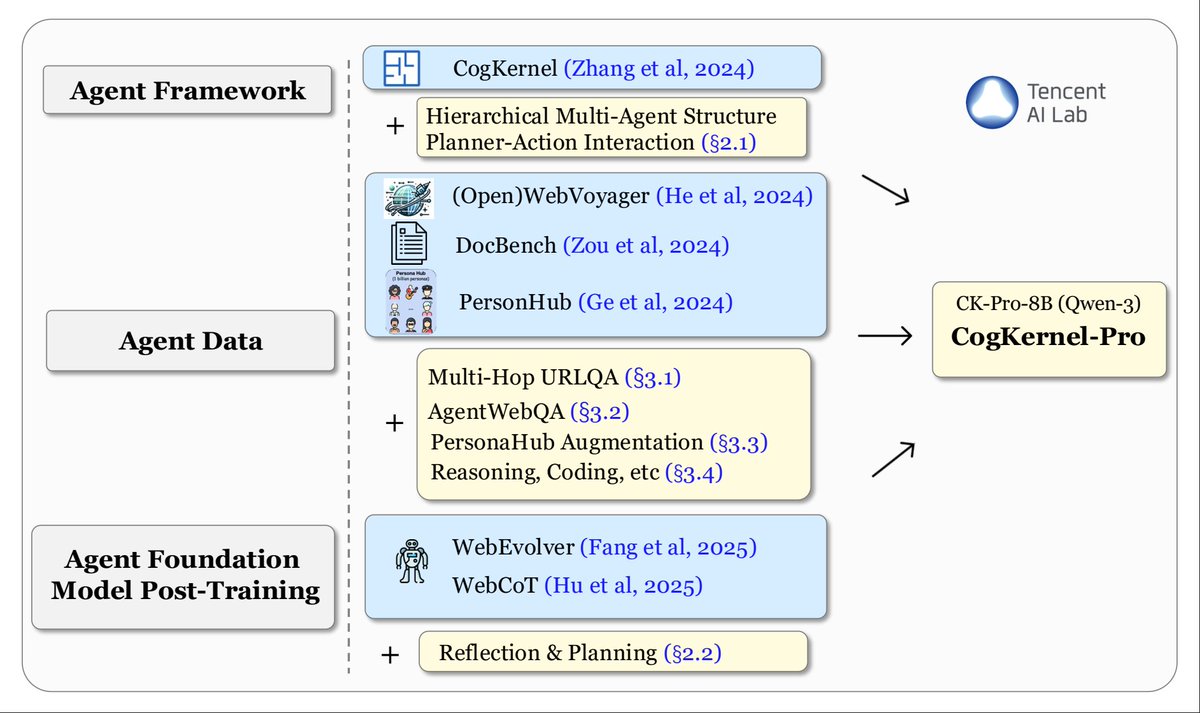
This work builds on the previous efforts of Tencent AI Lab (Fig. 2). Be sure to check them out if you're interested!



English