Sabitlenmiş Tweet

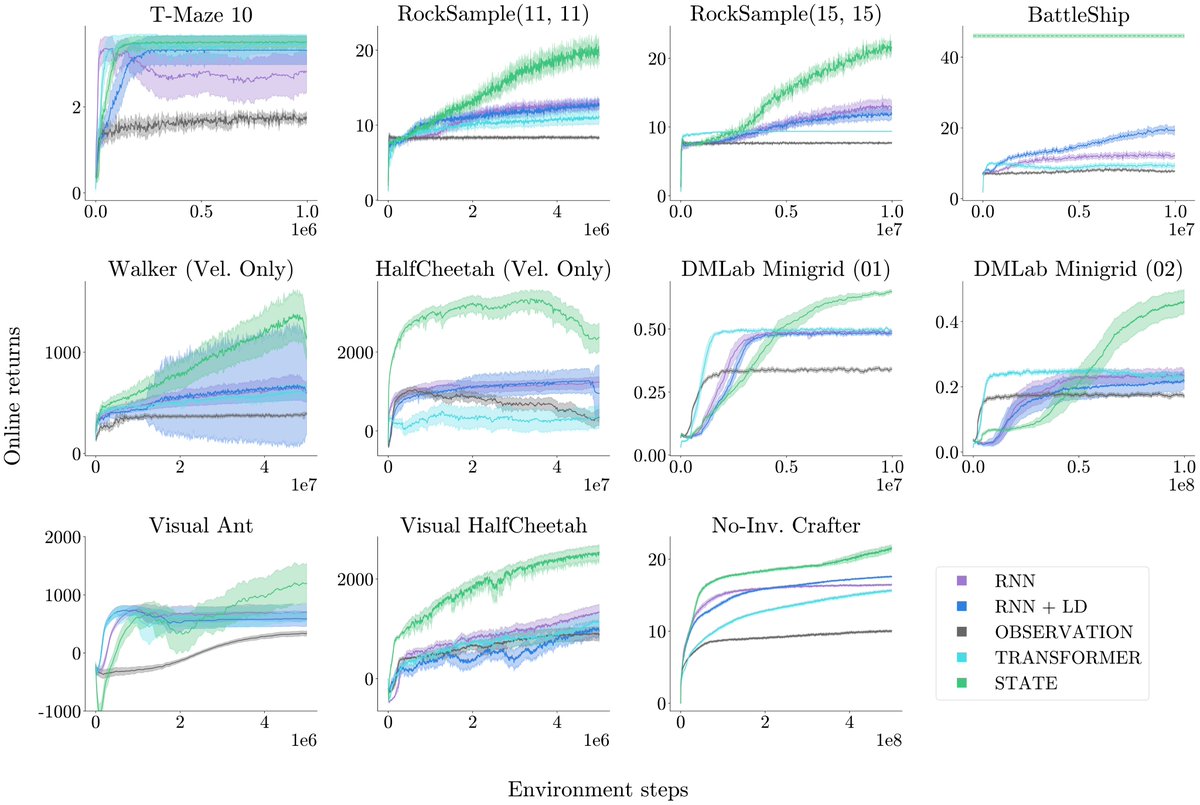
What does it mean to be “better at” partial observability in RL? Existing benchmarks don't always provide a clear signal for progress. We fix that.
Our new work (at RLC 2025 🤖) introduces a new property that ensures your gains are from learning better memory vs other factors. AND we provide a new JAX benchmark with environments that all have this property!
🧵1/5

English