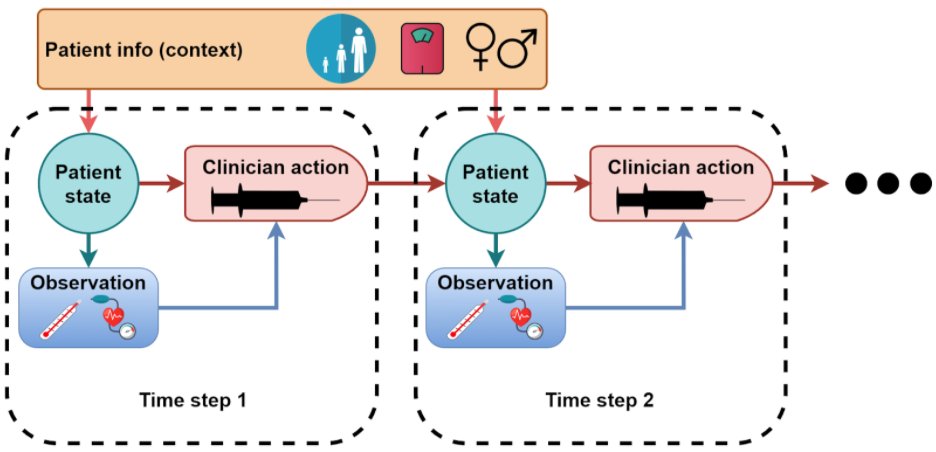
Deep networks combined with finite memory poses a problem for bandit-based algorithms.
In this blog post, Ofir explains their method for overcoming the drift in the learned features and avoiding catastrophic forgetting!
rlrl.net.technion.ac.il/2021/06/24/onl…
English