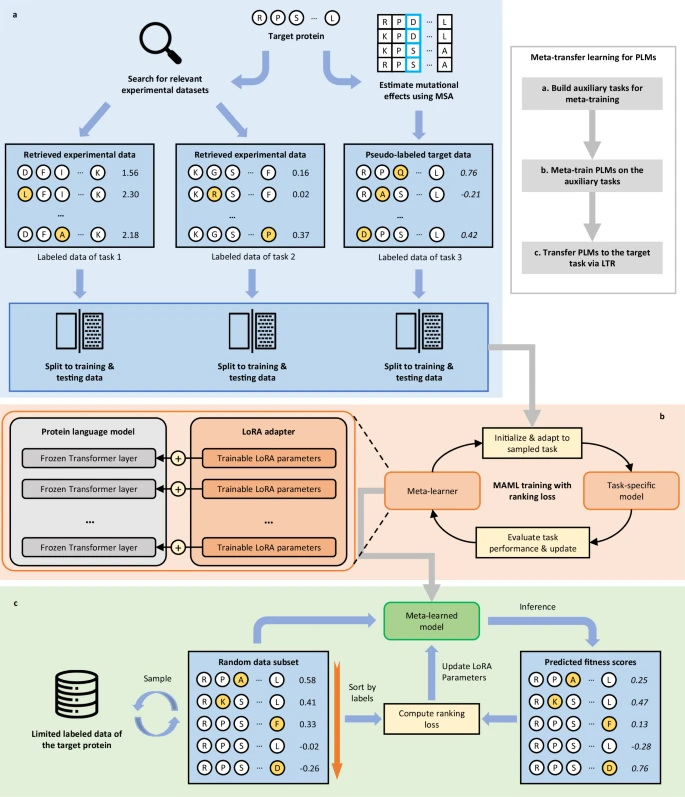
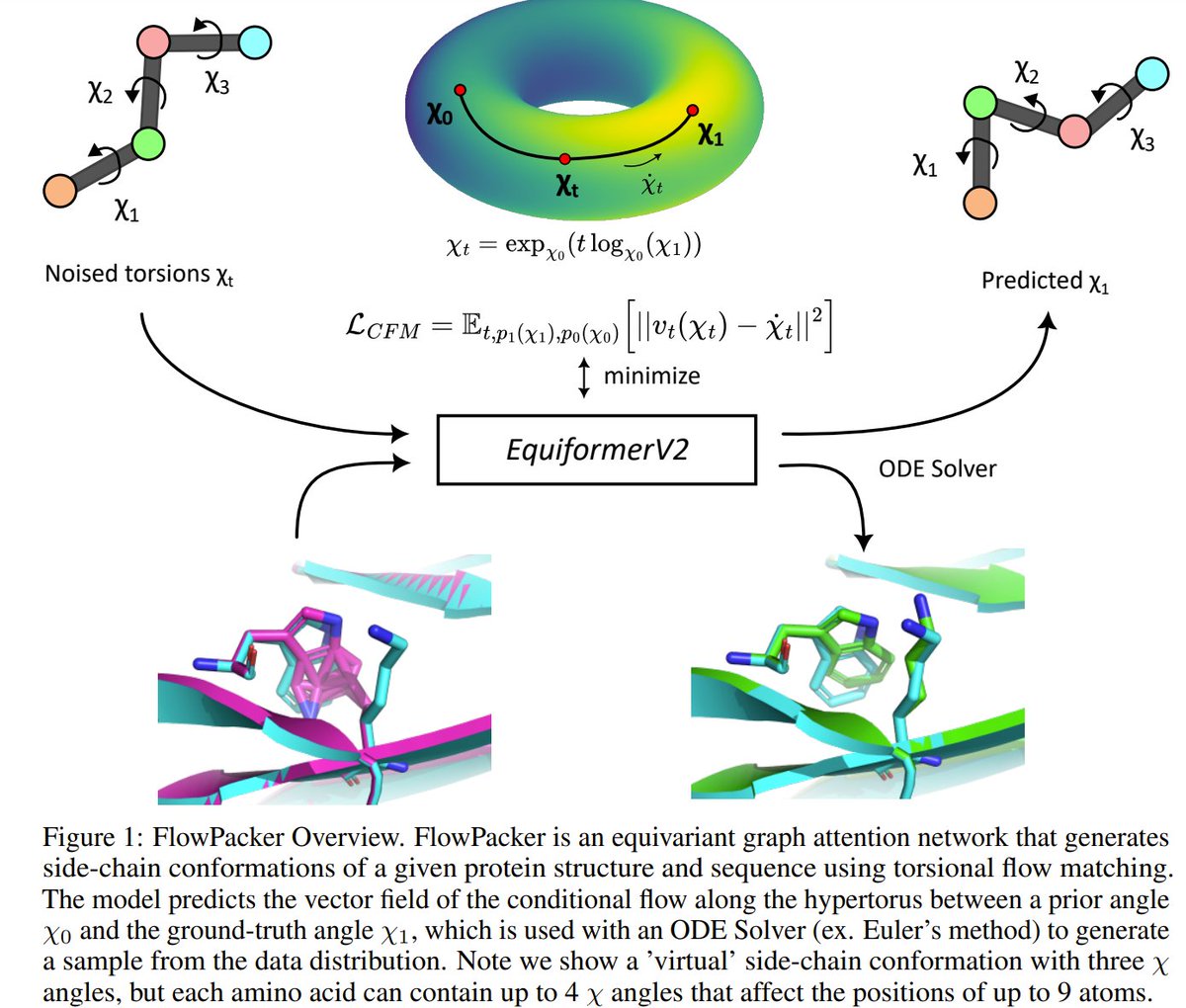
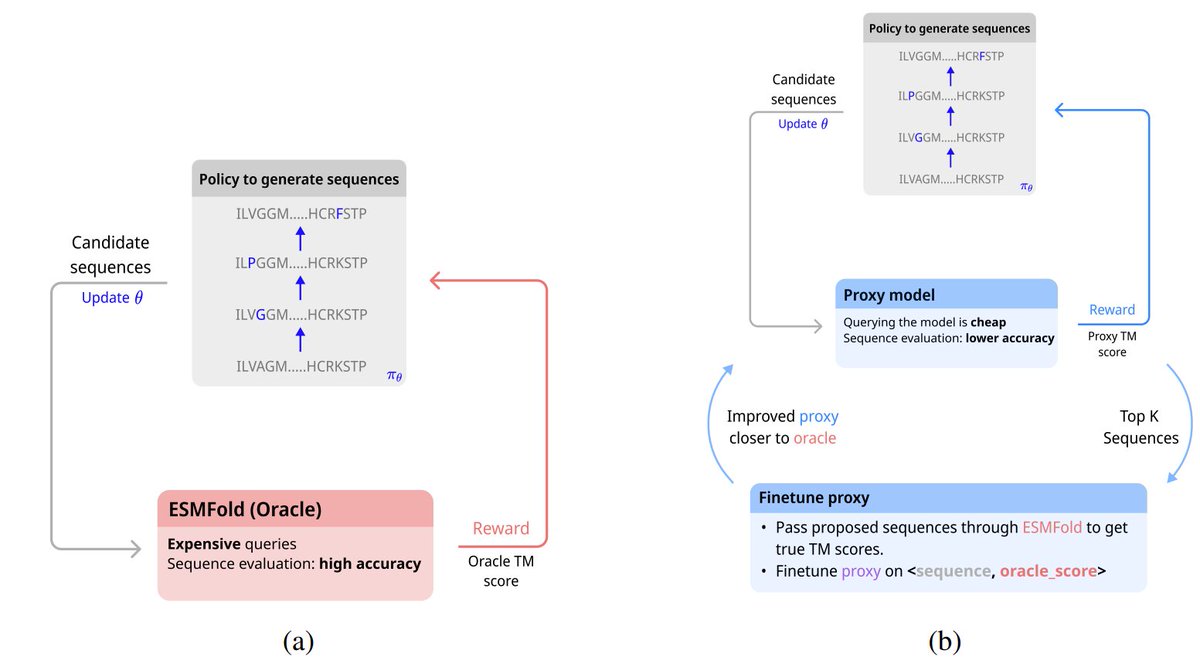
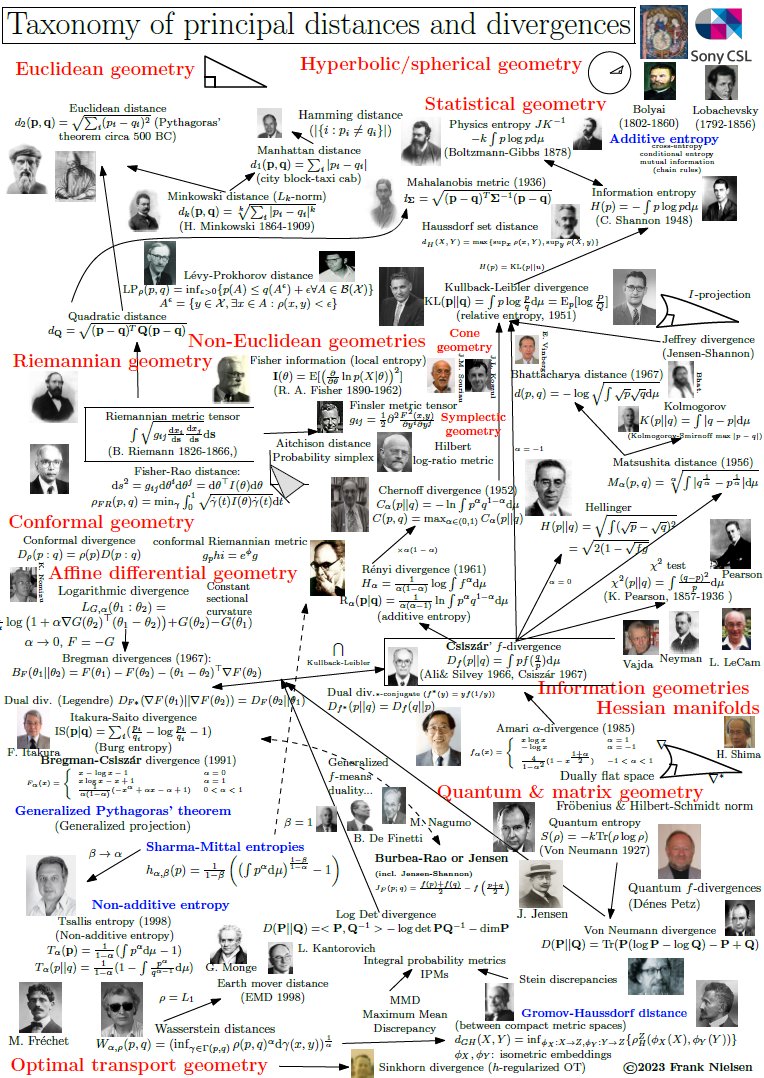
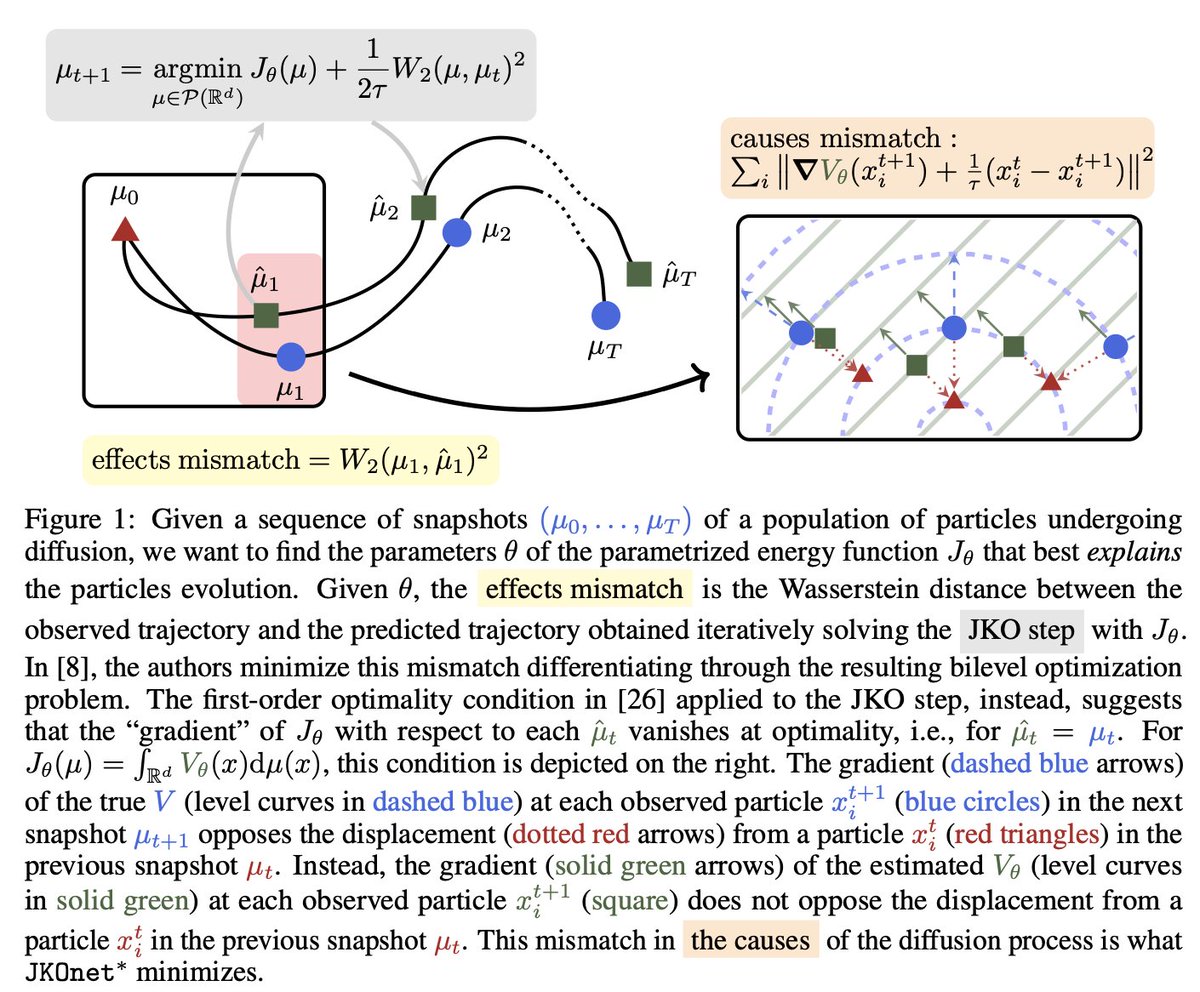
Khaled Abdel-Maksoud retweetledi

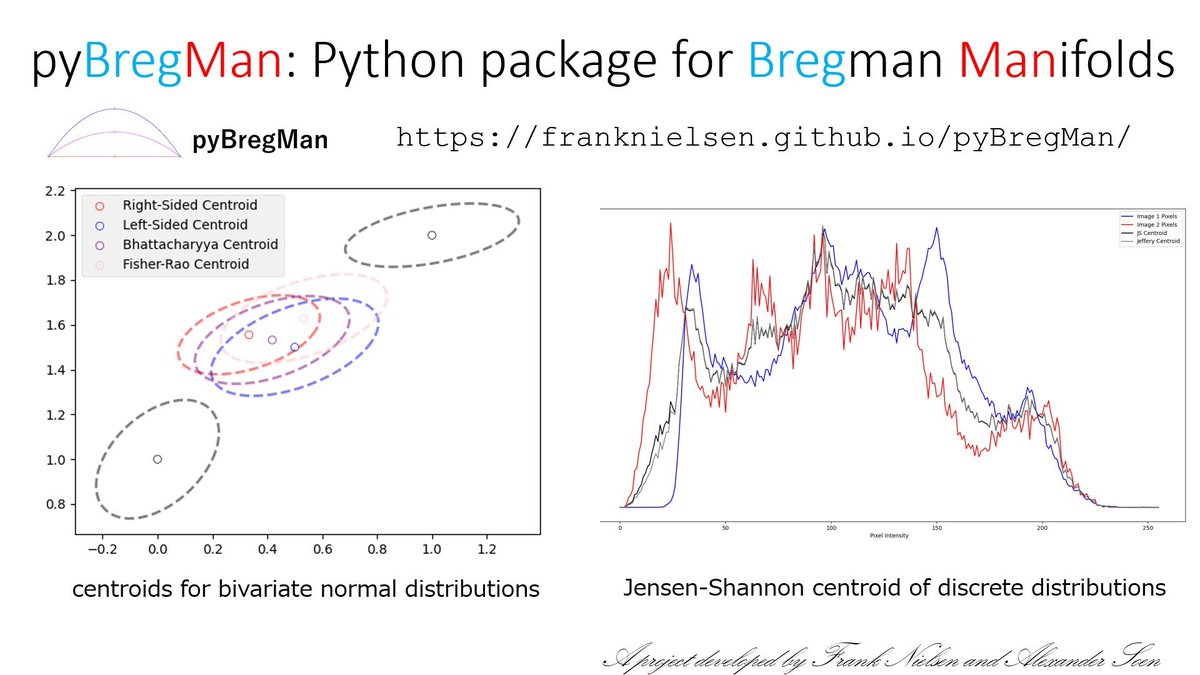
pyBregMan:
A Python library for geometric computing on BREGman MANifolds with applications.
# Installation
!pip install pyBregMan
and check the readme example:
github.com/alexandersoen/…
English
Khaled Abdel-Maksoud
1.3K posts


@Tench_KAMak
CADD+ML Scientist @CRiverLabs | MSci/PhD @ University of Southampton with @tmcscdt @comp_essexgroup | Retweeting science stuff frequently