We raised $6.5M to build the agent for professionals.
When your reputation is on the line, you need an agent that's reliable, secure, and one step ahead.
Try it now at serif.ai
LTM-2-Mini is our first model with a 100 million token context window. That’s 10 million lines of code, or 750 novels.
Full blog: magic.dev/blog/100m-toke…
Evals, efficiency, and more ↓
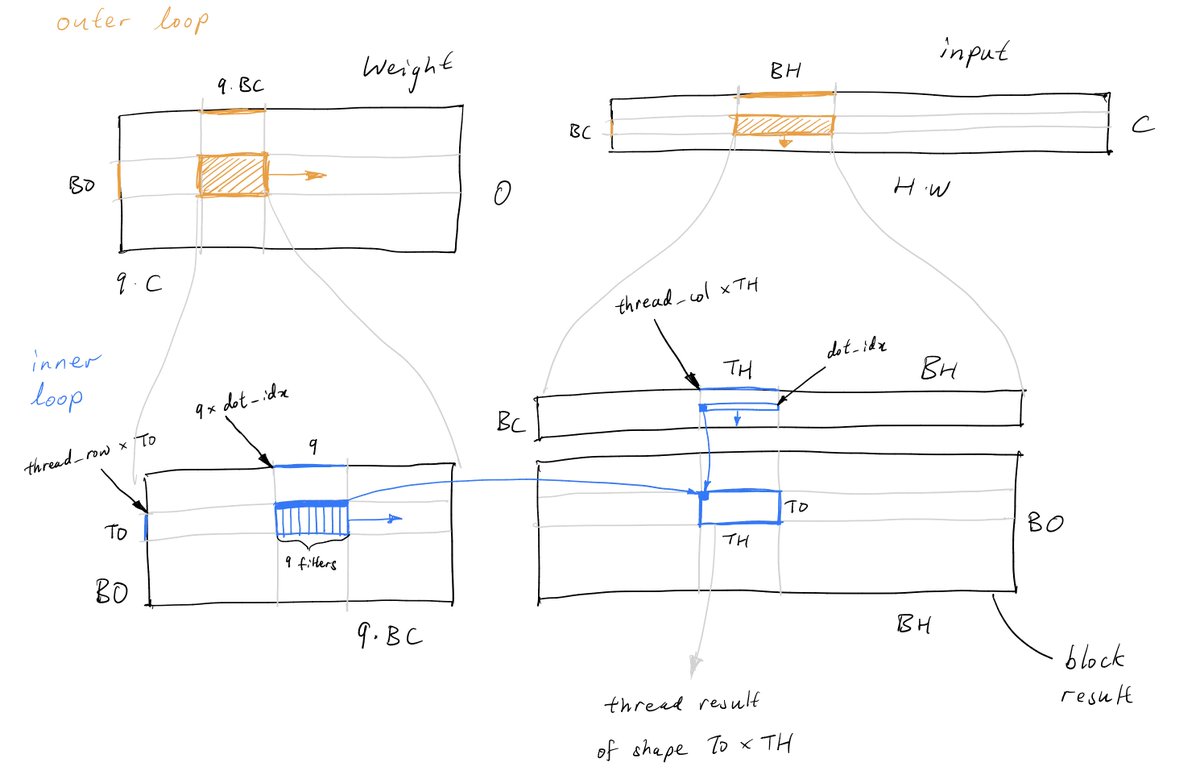
@yapdianang Hey Dian Ang! Don't think there were too many surprises because this was a learning project. I did learn that convolutions are hard, and you really should worry about memory transfers
@TiggerSharkML@karpathy@Si_Boehm Ah that should be doable already with the kernels in Andrej's llm.c, since DiT uses the same components
You'd probably want to rewrite some kernels to get best performance, otherwise you will be doing a bunch of slow tensor permutes. Definitely would be cool to see though
@ChrisChoy208@karpathy@Si_Boehm Ah thanks for spotting the cudaMalloc in the training loop Chris! I thought I had moved all of them outside the loop😅
Almost all of the memory is otherwise allocated before the training loop, so hopefully this is not affecting the times too much.
@_Chen_Lu_@karpathy@Si_Boehm This is impressive! You might want to check out memory allocators. cudaMalloc is an expensive operator and replacing it with some allocators that cache allocation could improve timing!
Most of the effort so far was spent getting the whole model to work. There is still a lot of room for optimization. Current per iteration timings on a single RTX 4090:
- this repo: 143ms
- PyTorch: 66ms
- PyTorch with torch.compile: 59ms
(2/3)