
tensor flow
1.4K posts
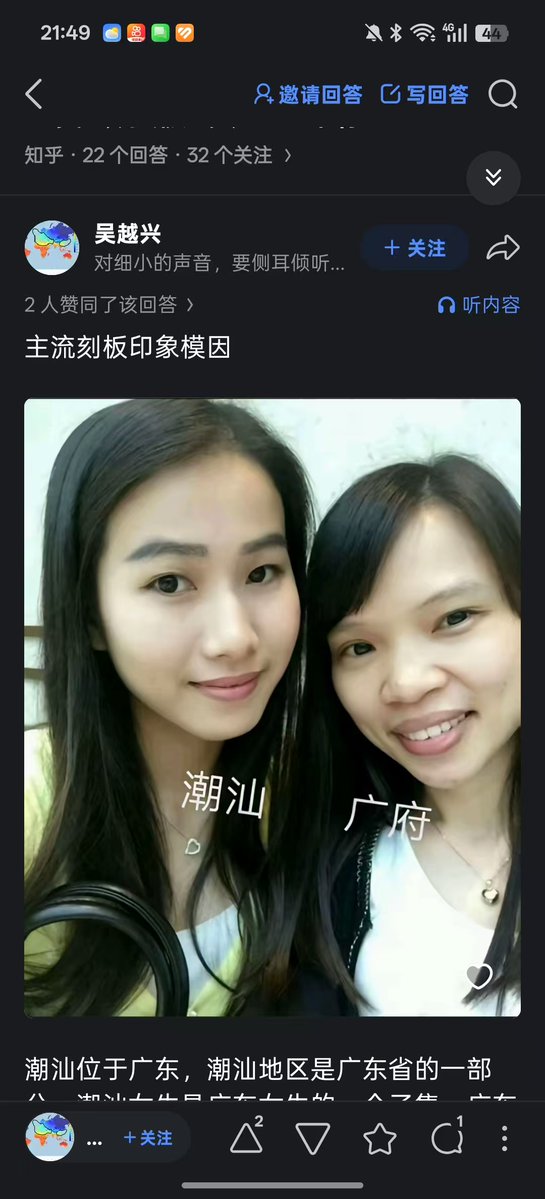

She is Cantonese more specifically Teochew.
emirate🕊️@clinton_emirate
Is she Korean, Japanese or Chinese?
English


@notcomplex_ So all this time Asians have not been shorter due to genetics, they've just been malnourished?
English



@TensorF31520 @MJTVHoPin 韩国大概是最喜欢旅行的国度之一。韩国人在东南亚开设了很多度假酒店。很多东南亚的高级酒店也有韩国管理团队。尤其在菲律宾,几乎成了韩国人的天下
中文

韓國人旅遊者似乎比日本人多。以前日本人很多,歐美不少酒店標明英文、日文。
為什麼少了日本人,非常簡單:沒有錢了。日元貶值太厲害,旅遊成本這幾年漲了50%。
早幾年,美國人也沒有錢去歐洲。現在美元强了,才敢去呀。
日本旅遊業做得好,中國做得非常差。日本受歡迎也是便宜,但就景點與文化而言,與美洲、歐洲、中國沒辦法比。
日本不少男人在經濟好時非常惡劣,比今天的中國不少男人粗俗多了。他們經常包機參加炮兵團,去台灣、香港、廣東等地。
日本女人值得尊重多了,友善、溫和、勤奮,但是地位太低了。她們男人開車停在車場,也往往不進超市。
日本有很多好的品質,值得我們學習。有很多糟糕的東西,是我們所不知的,或者了解不夠。
別聽那些八十年代後遺症的。他們所描寫的日本只是春夢。日本與美國、歐洲、中國一樣,有優有劣。
Eda@9vvrgM4rP41xZoi
@MJTVHoPin 很多年来,日本人是全世界最受欢迎的国家游客。虽然他们不习惯给小费,但是谦和有礼,遵守秩序,很少有喧闹之声。去年我在bled湖见到过两个连拍照都很咋呼的人,用中文问他们从哪里来,没有听懂,然后用英文问,回答我是:日本。但我直觉不是,心里想大概是韩国人。最近两年确实少见日本人在欧洲旅行
中文
@9vvrgM4rP41xZoi @MJTVHoPin 论海岸线风光的话印尼,斐济或者很多太平洋岛国最好,日本那种东北亚海岸线还是一般般
中文
@TensorF31520 @MJTVHoPin 我看过中国一家民营航空公司的可行性分析报告,它在日本开设了多条航线,拿了很多时刻,远超国企航司。不过这次受政治影响,航班减少不少
中文
@9vvrgM4rP41xZoi @MJTVHoPin 😂我个人偏好自然风光,所以日韩都完全吸引不了我.相反 新西兰 ,瑞士 这些地方我很喜欢
中文
@9vvrgM4rP41xZoi @MJTVHoPin 因为我经常去川西 云南这些地方,也去过两次日本,总体上来说日本自然观光资源还是感觉差了点
中文
@TensorF31520 @MJTVHoPin 海岸线及岛屿,森林覆盖率接近70%.高地,湖泊,春季的樱花秋季的红叶,温泉,粉雪。一年四季均有可观赏性。从自然资源来说,虽然算不上多,但可观赏性和整体配套的服务水平良好。加上城市的特色化,麻雀虽小 五脏俱全。还是值得四季旅行的,当然,我之前仅仅在说日本游客在世界范围的受欢迎度
中文



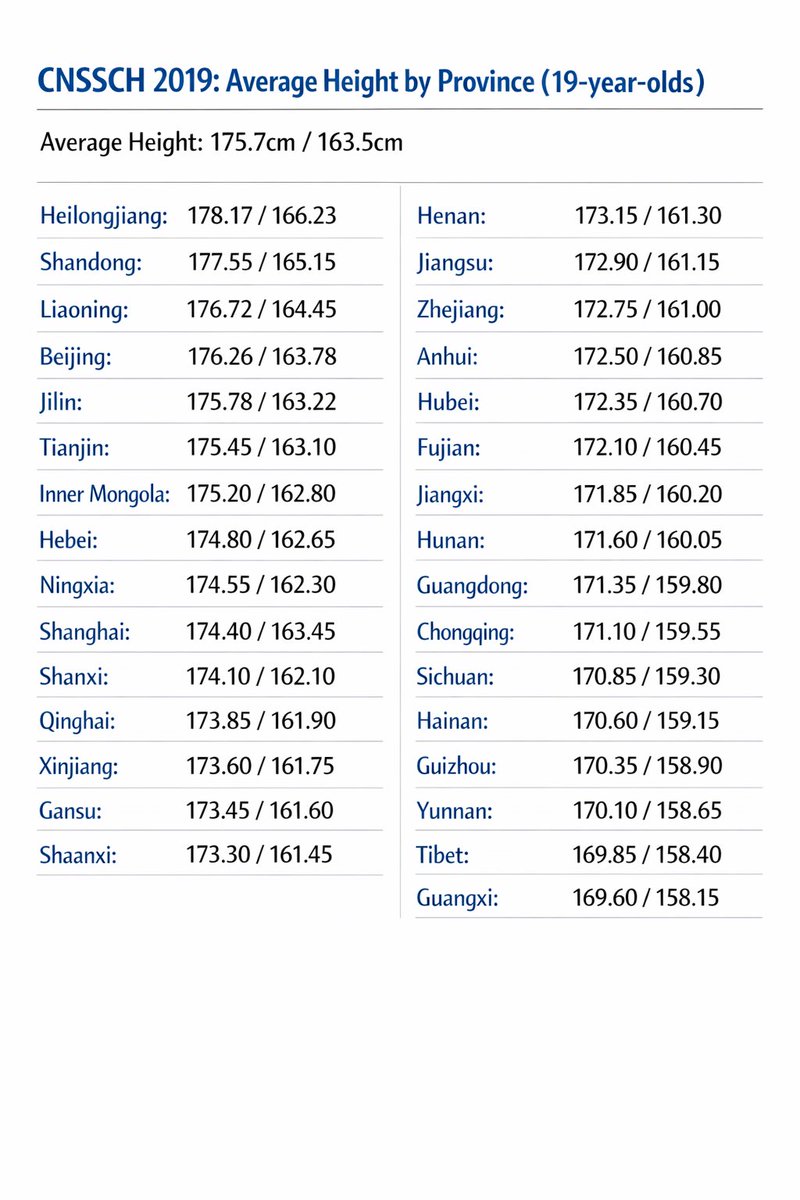
@notcomplex_ Until the 19th century, Northeast Asians were taller than Northern Europeans. The idea of short Asians is an illusion created by Southeast Asians and Southern Chinese.
2014: 172.0 → 2019: 175.7 — Northeast Asians are returning to their original position.
English

@wangwatchworld 你搞清楚,上街是伊朗人自己的选择,而不是美国以色列蛊惑的,如果蛊惑这么管用,现在伊朗人早都全部上街了。美国以色列只不过声援了抗议活动,声援和蛊惑这两个词不信你分不清。
中文

白宫和国务院以及以色列实际上坑死了这批伊朗人,他们蛊惑这批人上街,却完全没有计划军事援助。
等川普被以色列诱导轰炸哈梅内伊后,反对派实际上已经死绝了。
Jackchen007@chenaichu
@wangwatchworld 能革命的人,一月初被杀完了,四万,但是,有人会说,才四万,不足以革命,但是,这四万人产生蝴蝶效应会有四十万,前提是,美国一月初就像现在这样介入。
中文

@MJTVHoPin 在我的行业内有过很多专业的调查,航空运输,旅行秩序,消费习惯以及紧急情况的配合度等等10多个选项,日本游客的受欢迎程度确实多年排名第一。
中文





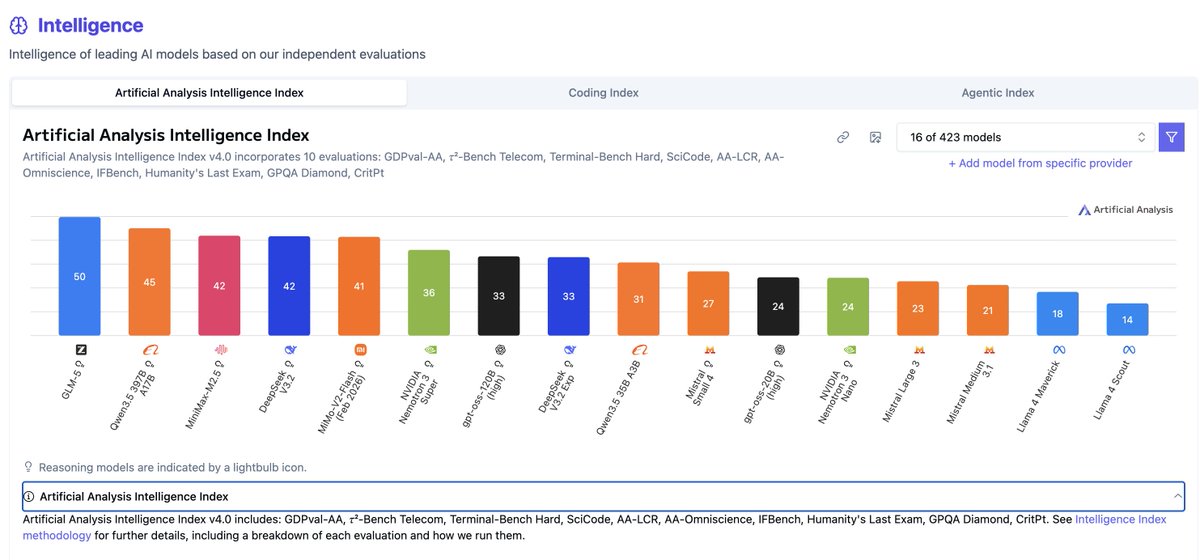
Mistral and Meta simply can't make good models
Little shocking tbh
OpenAI just dropped two nearly a year ago and it's still better than Mistral's today.
We have 20-35B parameter models better than Meta and Mistral's up to 400B
Artificial Analysis@ArtificialAnlys
Mistral has released Mistral Small 4, an open weights model with hybrid reasoning and image input, scoring 27 on the Artificial Analysis Intelligence Index @MistralAI's Small 4 is a 119B mixture-of-experts model with 6.5B active parameters per token, supporting both reasoning and non-reasoning modes. In reasoning mode, Mistral Small 4 scores 27 on the Artificial Analysis Intelligence Index, a 12-point improvement from Small 3.2 (15) and now among the most intelligent models Mistral has released, surpassing Mistral Large 3 (23) and matching the proprietary Magistral Medium 1.2 (27). However, it lags open weights peers with similar total parameter counts such as gpt-oss-120B (high, 33), NVIDIA Nemotron 3 Super 120B A12B (Reasoning, 36), and Qwen3.5 122B A10B (Reasoning, 42). Key takeaways: ➤ Reasoning and non-reasoning modes in a single model: Mistral Small 4 supports configurable hybrid reasoning with reasoning and non-reasoning modes, rather than the separate reasoning variants Mistral has released previously with their Magistral models. In reasoning mode, the model scores 27 on the Artificial Analysis Intelligence Index. In non-reasoning mode, the model scores 19, a 4-point improvement from its predecessor Mistral Small 3.2 (15) ➤ More token efficient than peers of similar size: At ~52M output tokens, Mistral Small 4 (Reasoning) uses fewer tokens to run the Artificial Analysis Intelligence Index compared to reasoning models such as gpt-oss-120B (high, ~78M), NVIDIA Nemotron 3 Super 120B A12B (Reasoning, ~110M), and Qwen3.5 122B A10B (Reasoning, ~91M). In non-reasoning mode, the model uses ~4M output tokens ➤ Native support for image input: Mistral Small 4 is a multimodal model, accepting image input as well as text. On our multimodal evaluation, MMMU-Pro, Mistral Small 4 (Reasoning) scores 57%, ahead of Mistral Large 3 (56%) but behind Qwen3.5 122B A10B (Reasoning, 75%). Neither gpt-oss-120B nor NVIDIA Nemotron 3 Super 120B A12B support image input. All models support text output only ➤ Improvement in real-world agentic tasks: Mistral Small 4 scores an Elo of 871 on GDPval-AA, our evaluation based on OpenAI's GDPval dataset that tests models on real-world tasks across 44 occupations and 9 major industries, with models producing deliverables such as documents, spreadsheets, and diagrams in an agentic loop. This is more than double the Elo of Small 3.2 (339) and close to Mistral Large 3 (880), but behind gpt-oss-120B (high, 962), NVIDIA Nemotron 3 Super 120B A12B (Reasoning, 1021), and Qwen3.5 122B A10B (Reasoning, 1130) ➤ Lower hallucination rate than peer models of similar size: Mistral Small 4 scores -30 on AA-Omniscience, our evaluation of knowledge reliability and hallucination, where scores range from -100 to 100 (higher is better) and a negative score indicates more incorrect than correct answers. Mistral Small 4 scores ahead of gpt-oss-120B (high, -50), Qwen3.5 122B A10B (Reasoning, -40), and NVIDIA Nemotron 3 Super 120B A12B (Reasoning, -42) Key model details: ➤ Context window: 256K tokens (up from 128K on Small 3.2) ➤ Pricing: $0.15/$0.6 per 1M input/output tokens ➤ Availability: Mistral first-party API only. At native FP8 precision, Mistral Small 4's 119B parameters require ~119GB to self-host the weights (more than the 80GB of HBM3 memory on a single NVIDIA H100) ➤ Modality: Image and text input with text output only ➤ Licensing: Apache 2.0 license
English

Is that's shameful for using kimi 2.5 as a base model?😅
Lee Robinson@leerob
Since people really want me to say this: "KIMI K2.5" ‼️ Yes, that is the base we started from. And we are following the license through inference partner terms (e.g. Fireworks) I'm thankful for OSS models personally, good for the ecosystem.
English

美国情报界已下调对中国明年攻台风险的评估,并得出结论,认为北京方面倾向于在不动用武力的情况下控制这座自治岛屿。
报告暗示,北京方面认为对台湾的两栖攻击存在风险,且很可能失败,尤其是在美国介入的情况下。on.wsj.com/3Ni01kJ
中文
@marisaras2 @dovis65906 @malhll151559 @mingyuerugu @Fivestarbird @kaylawaterr 在**《太祖实录》卷八,太祖四年(1395年)十月七日**,宫殿落成后,郑道传奉命为各个殿阁命名:
景福宫:取自《诗经》“既醉以酒,既饱以德,君子万年,介尔景福”。
勤政殿、思政殿、康宁殿等:皆由郑道传撰名,并书写所拟含义呈献给太祖
中文

경복궁은 자금성보다 먼저 지어진 궁궐입니다.
경복궁 (조선): 태조 이성계가 조선을 건국한 후 1395년에 완공했습니다.
자금성 (명나라): 명나라 영락제가 베이징으로 천도하며 1406년에 착공하여 1420년에 완공했습니다.
따라서 1395년에 이미 완공된 경복궁이 1406년에 짓기 시작한 자금성을 모방하여 지어졌다는 주장은 성립할 수 없습니다.
건축적 배경
두 궁궐이 유사해 보이는 이유는 동아시아 공통의 유교적 건축 규범인 『주례(周禮)』 「고공기(考工記)」의 원칙을 따랐기 때문입니다.
좌묘우사(左廟右社): 궁궐 왼쪽에 종묘를, 오른쪽에 사직단을 배치하는 원칙.
전조후시(前朝後市): 앞쪽에는 조정(관청)을, 뒤쪽에는 시장을 두는 원칙.
삼문삼조(三門三朝): 세 개의 문과 세 개의 구역을 거쳐 정전에 도달하는 구조.
조선은 이러한 유교적 질서를 바탕으로 경복궁을 설계했으며 특정 궁궐인 자금성을 베낀 것이 아닙니다. 오히려 일부 학자들 사이에서는 자금성의 설계에 경복궁을 포함한 동아시아의 기존 궁궐 양식이 참고되었을 가능성을 제기하기도 합니다.
건축양식도 아니고 배치관련이네 자금성이 따라한게 맞네요?
한국어

hanfu from the Song dynasty(960-1279)
According to the report, P3 is from the Northern Song Dynasty(960-1127).
These are not so called "Goryeo yang/Korean style/고려양/高麗樣" at all, hahaha.
#hanfu #chinese_culture



English
@marisaras2 @dovis65906 @malhll151559 @mingyuerugu @Fivestarbird @kaylawaterr 在**《太祖实录》卷六,太祖三年(1394年)十二月三日**的记载中,提到了营建新都宫阙的情况:
“冬十二月……命新都宫阙造成都监,判三司沈德符、参赞门下府事金溱、密直使李恬、郑道传、前商议中枢院事李稷、前密直使权仲和等,议其制度。宫阙之制,拟于中国,而亦从其省约。由是,汉阳之宫
中文