Sabitlenmiş Tweet

Your coding agent can run all night. It still can't tell if what it built actually works.
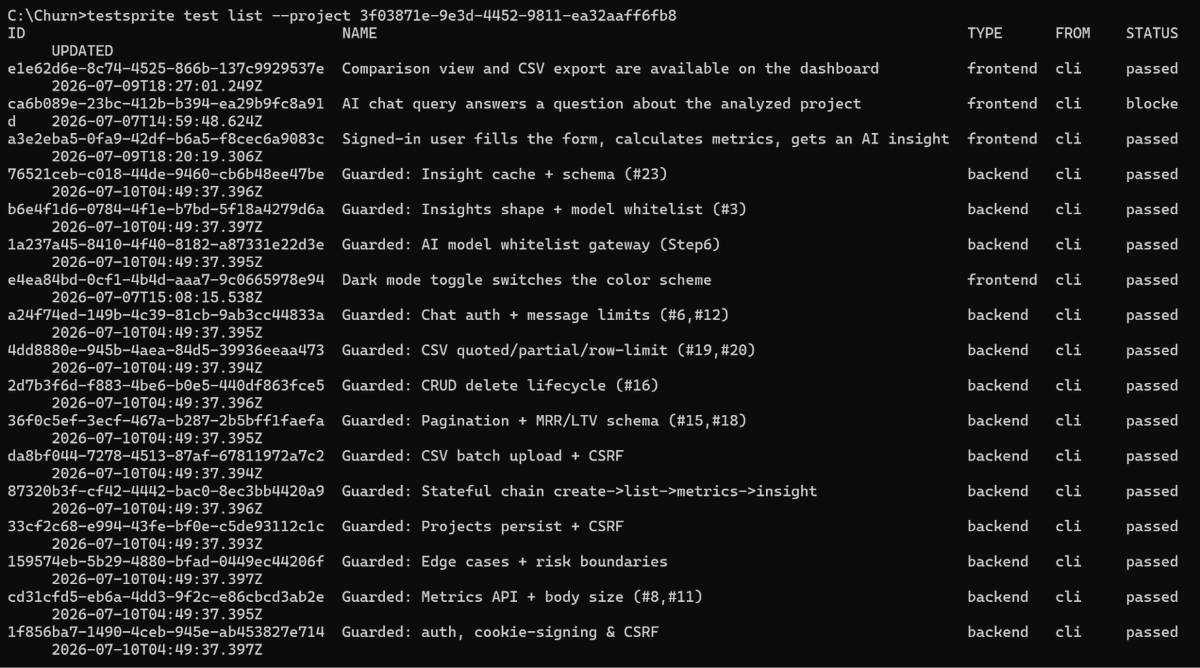
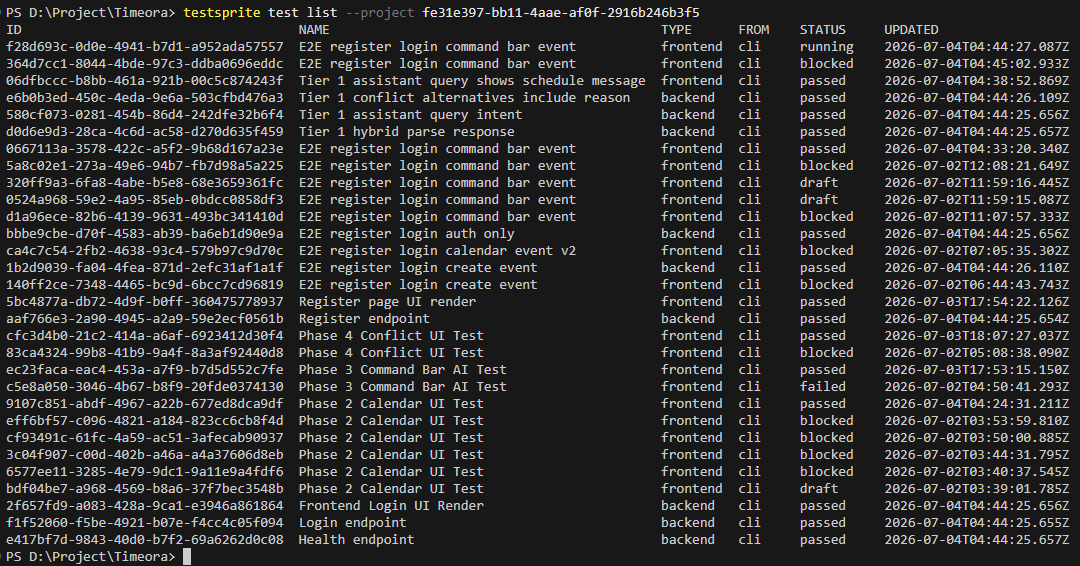
Today we're open-sourcing the TestSprite CLl
(Apache-2.0)
A tool your agent calls on its own to test your app end-to-end like a real user, fix what broke, and re-check everything it ever got right. It's the same engine 100,000+ teams already use.
github.com/TestSprite/tes…
We proved it in public, on a public leaderboard:
Most correct app on the board:89% Built by the cheapest model in the field At half the cost of the priciest one
You no longer need the biggest, most expensive model to ship software you can trust.
Setup is 2 commands:
npm install -g @testsprite/testsprite-cli
testsprite init
That's the last command you'll ever type - from there, your agent runs the tests itself.
English