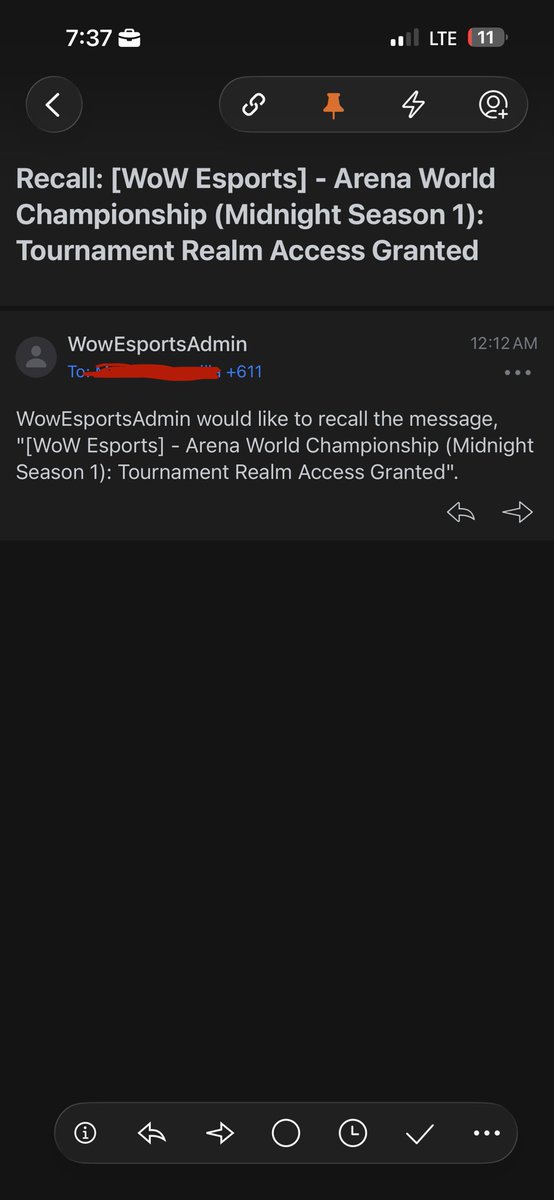
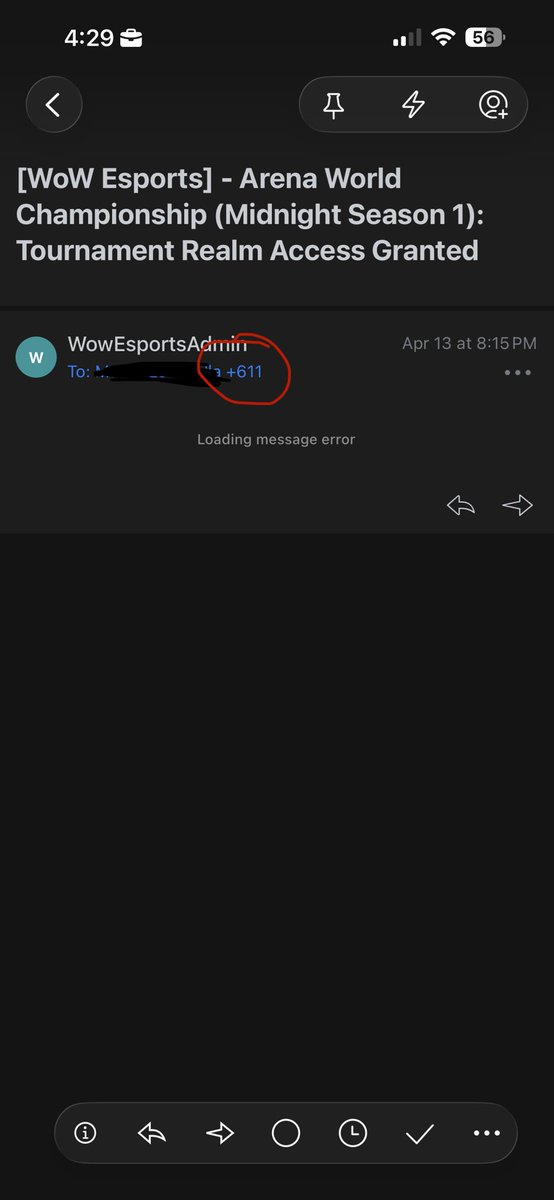
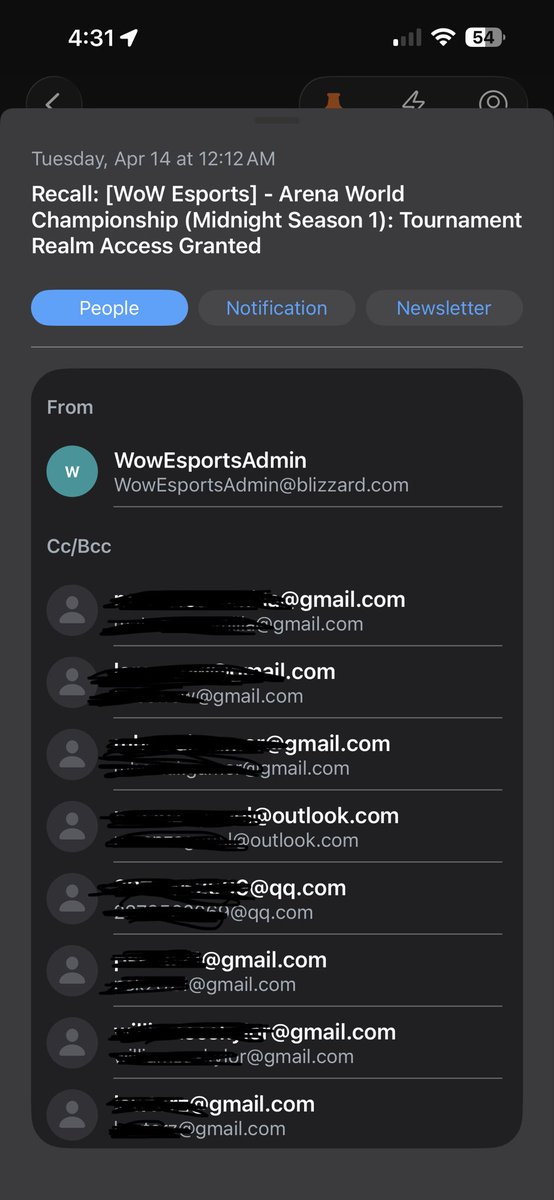
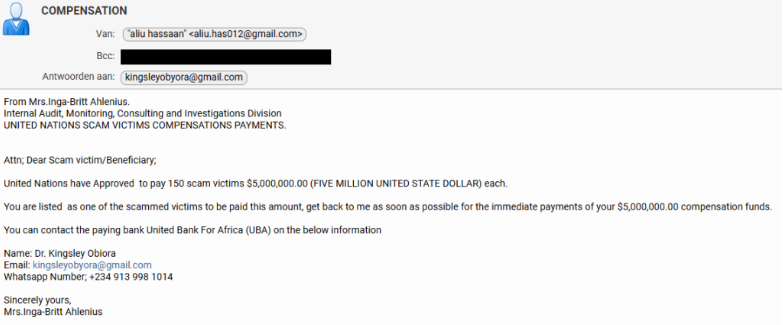
@take_n_go @Pirat_Nation I think the guy was eyeing minesweeper but that would of have pushed the LO2 guys too hard so he held back
English
TheEpTic
10.5K posts







🚨 UPDATE: 19 MILLION exposed NGINX instances hit by the 18-year-old NGINX RCE found by AI. Top exposure by country: - United States: 5,340,011 - China: 2,540,008 - Germany: 1,871,780 Note on ASLR as added security: not all of these instances will have ASLR disabled, but every one of them is running a version inside the vulnerable band. The vulnerability is a heap buffer overflow. ASLR randomizes memory layout, which makes reliable RCE much harder because the attacker cannot predict where their payload or useful gadgets land. But the overflow itself still happens. The corrupted memory still causes the NGINX worker process to crash. ASLR-enabled hosts are still trivially DoS-able. ASLR-disabled or non-PIE builds are RCE-able. Either way, patch ASAP!

‼️🚨 UPDATE: The TanStack npm attack is now a full campaign. 'Mini' Shai-Hulud has hit: - OpenSearch - Mistral AI - Guardrails AI -UiPath - Squawk packages across npm and PyPI The malware specifically targets AI developer tooling. It hooks into Claude Code (.claude/settings.json) and VS Code (.vscode/tasks.json) to re-execute on every tool event, long after the infected package is gone. npm uninstall does not fix this.




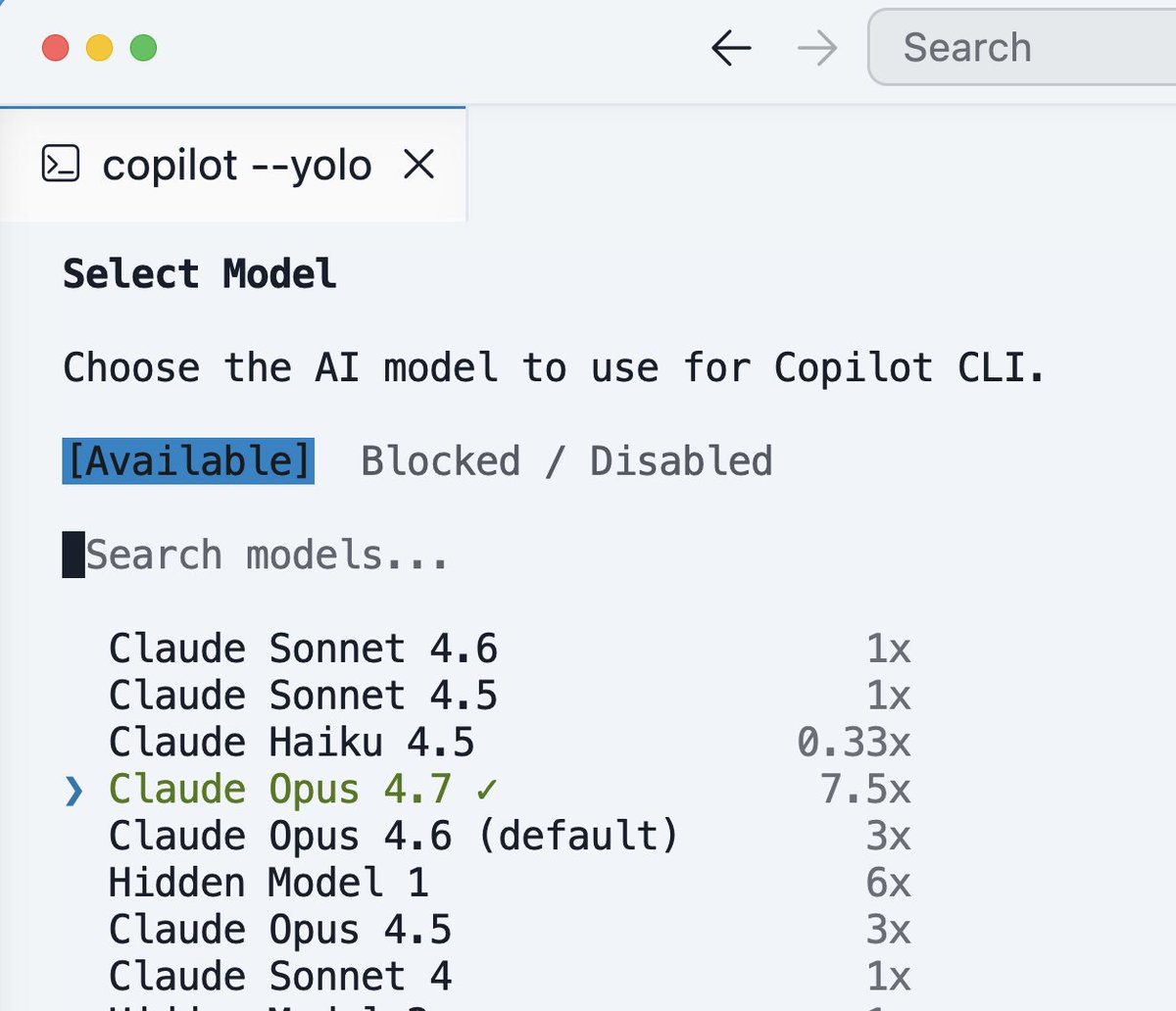
The countdown to Copilot's new plan.

Ornstein-Hermes-3.6-27b-SABER is up. Only 1 / 349 harmbench refusals, GGUFs are uploading as we speak! MLX conversions after that This would not have been possible with out the kindness of @dangerm00se thank you very much for your help in making this possible! huggingface.co/GestaltLabs/Or… huggingface.co/GestaltLabs/Or…