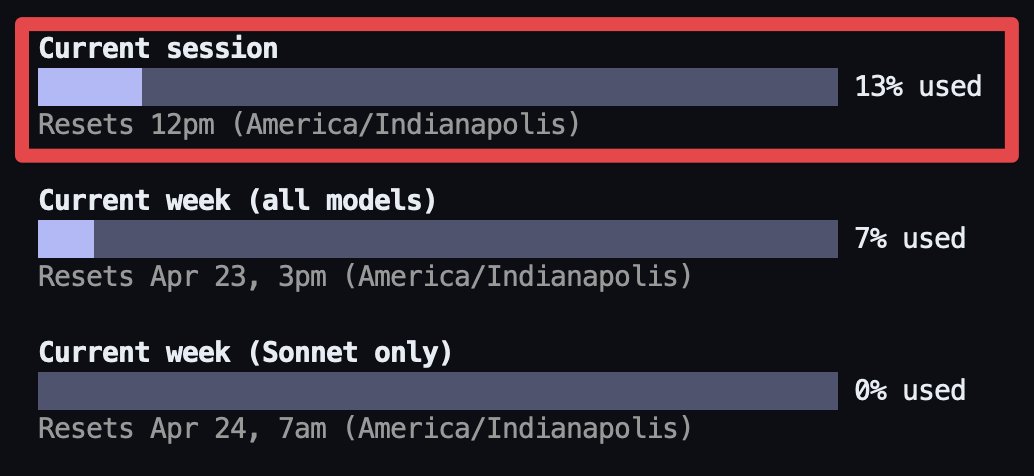
I love my GPT Pro sub, but the limit resets are a gaslight. Everyone acts like it’s a free refill lol. They’re just resetting the weekly timer. It’s like your boss saying you can have Friday off but you gotta come in to work on Sunday. You just hit the wall sooner next time.
English