Sabitlenmiş Tweet

The Grid’s Beta is LIVE!
We can get your AI API costs down by up to 80% by making suppliers compete for your requests.
Your first 200M tokens are on us, start building
→ app.thegrid.ai/sign-up
English
The Grid
229 posts

@The_GridAI
The spot market for AI Inference

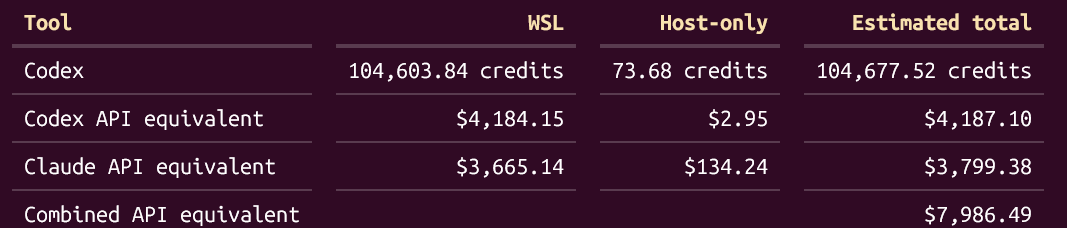
i'm kinda sick of 5.6 sol now honestly. yes it's a good model, no it doesn't help me ship as much software as it should. it feels too RL-fried and ends up in all these local minima where it just spins its wheels doing nothing, invents bullshit overly cautious procedures you didn't ask for, doesn't solve your problems, hyperfocuses on tiny details, adds theatrical bullshit like tests/ledgers/hashing/proofs/review loops to "ensure stuff works" (none of it works) and degrades context over long-running threads. 1/3rd of the time it can distil your intent kinda okay and keep it up for a few hours but it will eventually collapse into total slop cannon, no matter how much you steer it. the other 2/3rd of the time it will just misunderstand you and slop cannon. oh yeah and the limits are cooked and it burns 5x the tokens of 5.5 whilst you don't ship. bring on GPT 6.....








Introducing Claude Opus 5. It's a thoughtful and proactive model that comes close to the frontier intelligence of Fable 5 at half the price.

What if unused tokens weren't wasted? Reselling is live on The Grid. Use what you need, resell what you don't. Tell your agent to buy and sell inference to stretch your spend.





