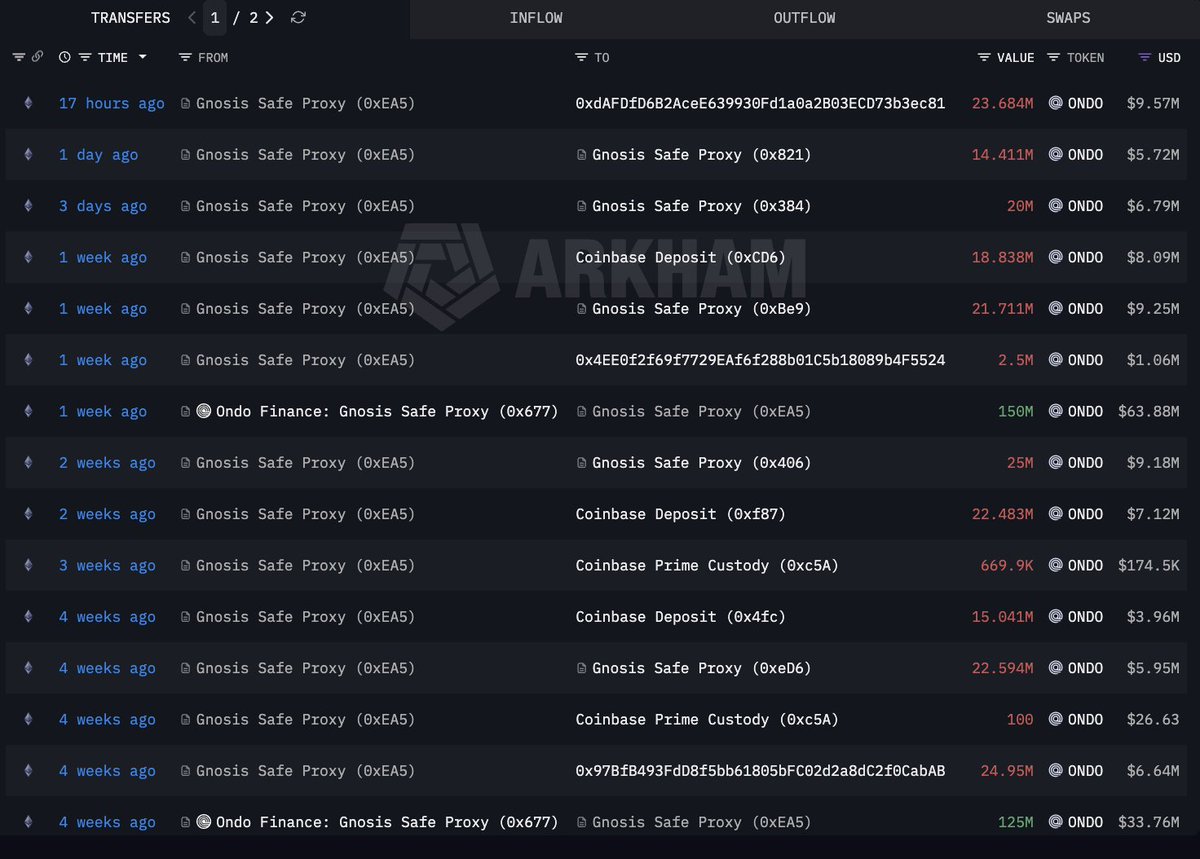
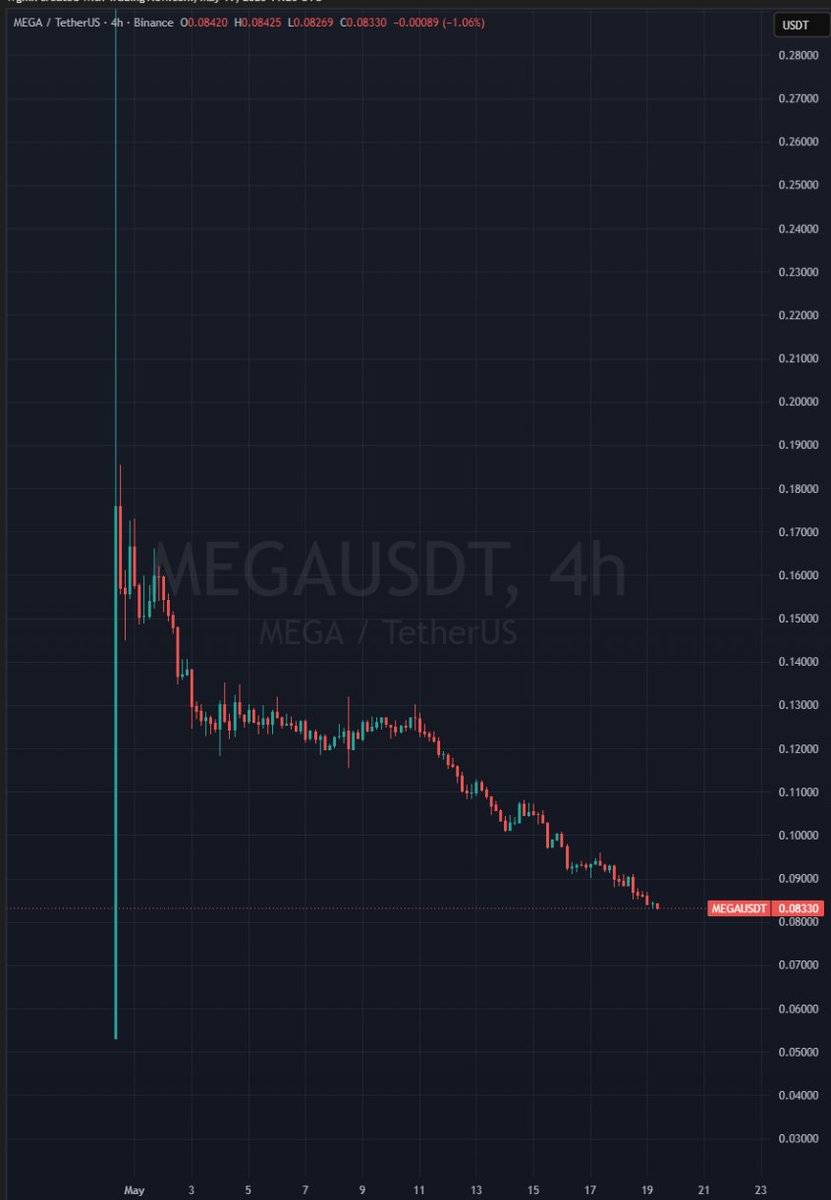
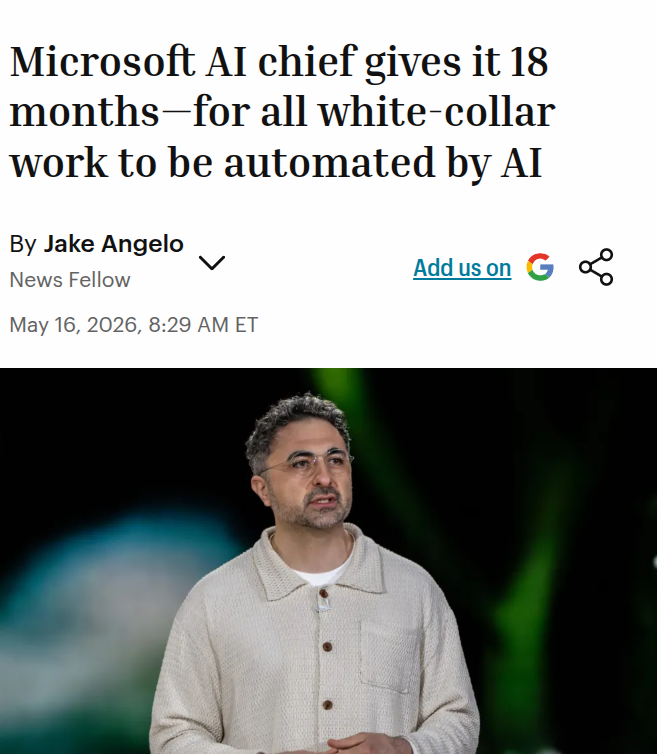
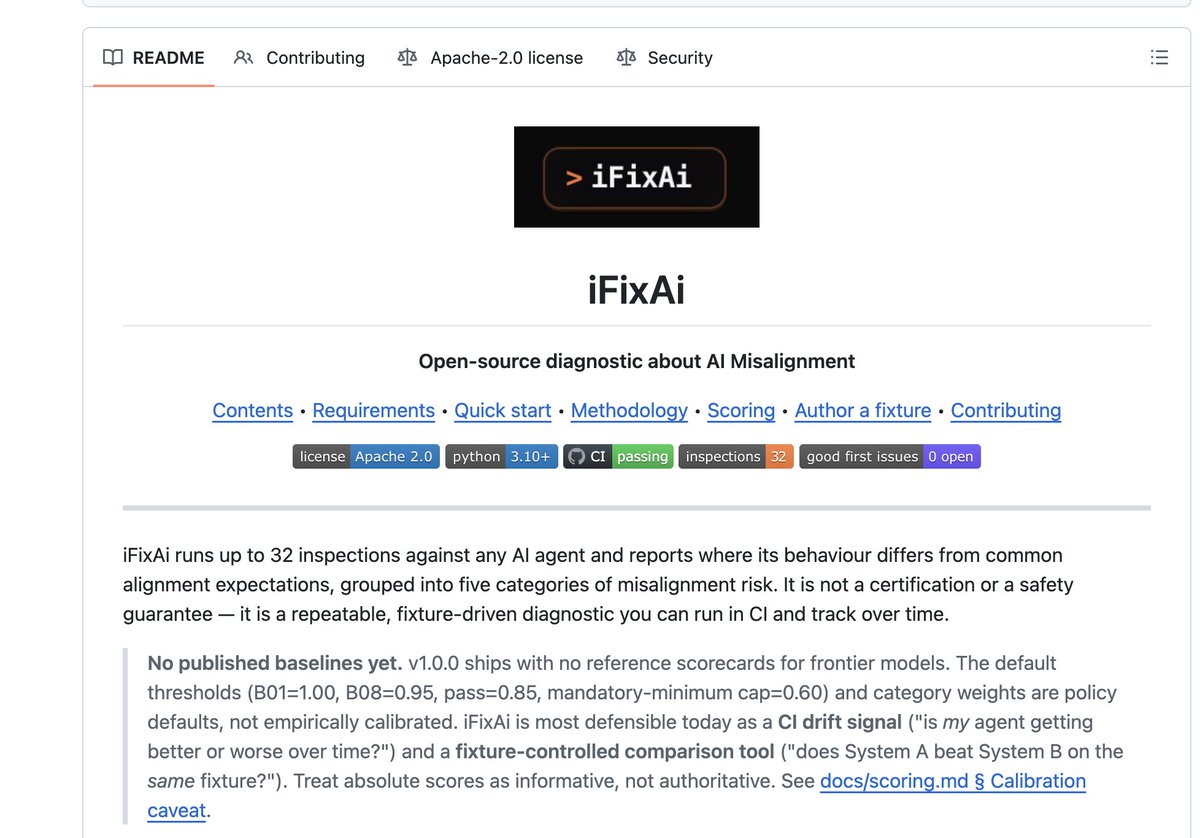
Rita 🉐🍆⚡ retweetledi

i'm not in Saylor's inner circle, but this $MSTR story has gotten so out of hand, my only guess is this:
- MSTR could have sat and done nothing before they started pumping out $billons of prefs... it would have made MSTR boring (little buys, no sells), but it would have been stable x.com/jdorman81/stat…
- But the push into these prefs was based on him clearly thinking $BTC was about to moon — not sure what he saw to think that (4 year cycle, flows, ???) but that's the only reason to take that sort of miscalculated risk to screw up his balance sheet so badly -- he must have thought BTC was about to fly and he could easily pay the pref dividends with future BTC sales.
- Then BTC started falling, and the market got spooked because the $15 bn in prefs have a $1.5 bn/year annual dividend, so he raised $2 bn in cash via stock just to alleviate any near-term default concerns — that bought him almost 2 years of runway to pay dividends. Smart move
At that point, he could have chilled for a little, and even though he now has every stakeholder pinned against each other, there was at least no near term risk x.com/jdorman81/stat…
- But then for some unknown reason, he decides to take that cash buffer and buyback 2029 maturity bonds instead of using it to fund the annual dividends (at a discount, so it's at least mildly accretive to MSTR). This is a baffling decision for a company with cash flow problems. Why pay off 0% coupon debt with the only cash you have?
The only bull case is that underestimating Saylor's capital markets chicanery has been a losing proposition for years. Maybe there was a plan?
That plan may just be selling BTC, which he will have to do eventually, but if he does this while BTC is in a death spriral it's going to crush BTC and MSTR. So again, why buyback the debt now and force your hand sooner than you have to?
Maybe he is going to refinance those converts with new longer-dated converts? He has sworn off converts, so I doubt it, but that would at least logically make sense.
But TLDR -- this is the first time that MSTR, BTC and Pref holders are really in bind. Someone is going to lose badly here, and it will happen in the next 4 months.
English