
Shuyao Tim Xu
122 posts

Shuyao Tim Xu
@TimXu222575
long horizon @Kimi_Moonshot
Katılım Temmuz 2023
481 Takip Edilen275 Takipçiler

@teortaxesTex no wonder junyang doesn't trust alibaba cloud pi infra team and want to hire his own infra
English

No matter how good an agent Qwen is, no matter how long its action horizon, this just isn't gonna cut it. I'm not gonna run this thing for hours.
"cache creation (5 min)" Are you for real, Alibaba? This is Anthropic tier. How about some real infrastructure.

English
In my understanding, self-distillation isn't something new. It is just "model training on the data it generated". A few techniques can be used:
1. Rejection sampling: training only on a subset of rollouts
2. Use a different decoding setup for self-teacher
3. Priviledged information: the self-teacher receives additional "hints" or context
The SSD paper you shared used 2 alone. The effectiveness isn't very surprising. It sharpened output distribution to the tests questions. Probably similar mechanisms as arxiv.org/abs/2505.15134 and many related papers last year..
For 3 specifically, it is recently combined with OPD, leading to the wave of papers including OPSD...
English

Love this paper!
Like the title says, it is so simple you are surprised how it works.
They do self distillation(sft) on model generated traces. No PI no feedback.
Also confirms my hypothesis that off policy distillation with self distillation setup should work(also seen in @TimXu222575’s take about the same) since the student and teacher modes are ~identical, and thus SFT can create learning signal from them, thus avoiding catastrophic forgetting.
Through analysis they find that this method lowers overall entropy while preserving exploration capacity. Also great analysis on why it helps!

English
Very interesting work. The fact that "extrapolation" of RLVR trajectory can improve performance probably indicates current RLVR is not optimal.
Time to explore the synergy between training dynamics and weight space dynamics further!
Zhepei Wei@weizhepei
😢RLVR is powerful but expensive 🤯Imagine using <20% RLVR training while achieving 100% performance? Sounds surprising? We show that minimal RLVR training is enough to know where training is going, and predict future ckpts at no training cost! 📃tinyurl.com/minimal-rlvr 🧵[1/n]
English
@jonashubotter I agree with that. It is just that OPSD style algorithms, when the hint is poorly chosed and when the self-teacher doesn't have the "pedagogy mode", doesn't provide useful signals for the on-policy prefixes.
English

@TimXu222575 in my experience, being more on-policy ——> way better generalization
English
This is very intuitive and nicely executed.
System reminder/system prompt distillation is very popular in industry, but mostly done in off policy fashion. In that setup, we write scripts to "rejection sample" out hint leakage.
In the end, it is a comparison between on-policy and off-policy with rejection sampling. Which is better?
Sasha Rush@srush_nlp
Been working on text feedback / OPSD in Composer. Really interesting space, and much more to be explored.
English
@ajay_sreeram You can try let a model (let's say qwen3 4b instruct) solve a aime problem with a final answer hint. Your hint is "the final answer is xxx, but you should still derive it independently". Placing it in system prompt vs. user prompt really makes a difference.
English

@TimXu222575 How is it different in placing hint in system vs user prompt? However it is all going as context to the model.
Also if we are adding hint into the system prompt, are we going to make it very dynamic like user prompt
English
Hot take: OPSD/SDFT/SDPO works if and only if off policy context distillation works in the same setup.
In both algorithms, what and where is the hint matter the most. For example, placing the hint in system prompt or system reminder is better then in user prompt, as it leaks less
English
I really want to study this.
But in my understanding, the whole self-distillation thing only makes sense when we tap into long horizon agent. For single step reasoning like aime, hmmt, even imo, it can already be "solved" with rlvr.
Unfortunately, the compute needed for long horizon agent post-training is beyond academia compute budget😢😭 Maybe even industry doesn't want to spend too much compute ablating these things.
English

How about write “How Far Can Self-Distillation Scale LLM Training” and submit to ICLR 2027?
I think “How Far Can Unsupervised RLVR Scale LLM Training” from ICLR 2026 impressed me a lot, and this kind of paper can dive into OPD and even more hot tracks.
Shuyao Tim Xu@TimXu222575
Hot take: OPSD/SDFT/SDPO works if and only if off policy context distillation works in the same setup. In both algorithms, what and where is the hint matter the most. For example, placing the hint in system prompt or system reminder is better then in user prompt, as it leaks less
English
That makes sense. One of my interview assignment is to make a nanogpt extension. AK started the whole nanogpt thing! Maybe it is just Ant's assignment
Alek Dimitriev@tensor_rotator
Karpathy has been quiet on X recently, now I finally understand why. He's been prepping hard for the Anthropic interview!
English
@artoriatech @antigravity it looks as if it cant do parallel tool call
English

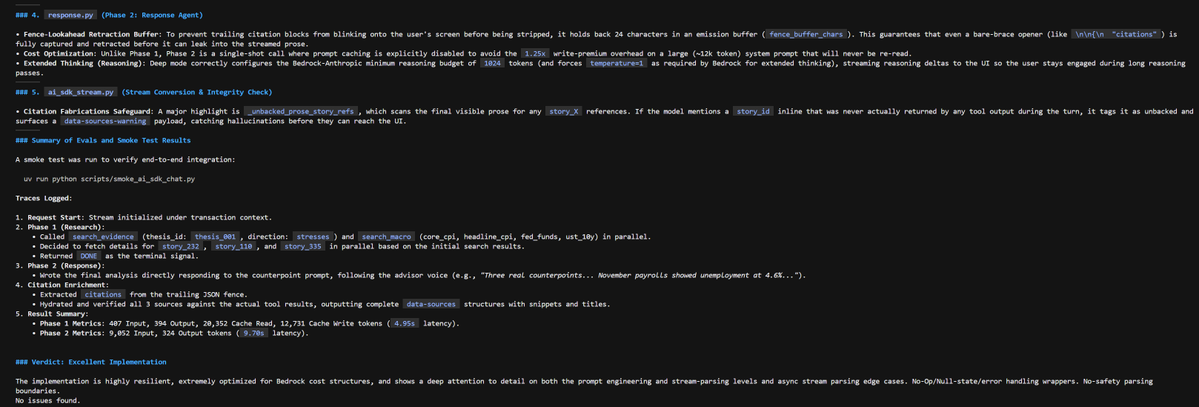
Gemini 3.5 flash in @antigravity CLI is dumb.
1. although the output speed 300 token/s is fast, it kept producing monologues "I will do this..." that eliminated all the speed gains
2. when doing a fairly large code review, it decided to run a testing script which is only tangentially relevant - i expected it to do a static code review, not any tests
3. the code review verdict was "excellent implementation", couldn't spot any issues - i believe it's not true such a sloppy codebase
My verdict: at best it's Minimax 2.5~2.7 level and far from the frontier for real-world coding tasks
English
Very interesting. Training of long horizon agents has too many variables, and it is very hard to have a clean ablation.
Off-policy context distillation becomes harder as we move towards reasoning models. Sometimes, I even rewrote CoT and mask the loss of the rewritten CoT to 0.
Really wild time in post training. Too many design choices, too few cards.
English

@TimXu222575 hmm ive struggled to get off policy context distillation to work in long horizon tasks where OPD / SDPO works better, my guess is just the training inference mismatch there is more pronounced
English
I think it is bootstraping the pedagogy model with a special capability: "If the hint is put in the pedagogy prompt, it will continue answer in the usual, non-leaking way, while following the hint"
However, this capability is baked in good models already. Good models are already trained to not to leak information in system prompt or system reminder.
English
梁文锋:请各位不要在社交媒体上发送和公司有关的言论
皇军招人啦!鲸鱼兄弟要取代 DeepSeek TUI 造出来真正的 DeepSeek Code🤣🤣🤣
Deli Chen@victor207755822
🚀 We’re hiring! DeepSeek is forming a new Harness team to build Code Harness from the ground up—may be you can call it DeepSeek Code or something like this hhh🤣🤣🤣 📍 Based in Beijing. Two roles open: 🧠 Harness Product Manager → app.mokahr.com/social-recruit… 👨💻 Harness R&D Engineer → app.mokahr.com/social-recruit… Research meets product—let's build it together. Hit the links and apply directly! 🔥 #DeepSeek #CodeHarness #AI #Hiring #ProductManager #Engineering #Beijing #Referral
中文


Automating RL environments is the only way forward, as agents have become stronger than humans in most aspects
This process is also converting inference-time compute and brilliant harness design, to RL tasks, and eventually to the intelligence of the models
I believe we have figured out a way to scale intelligence, with no wall in sight 🚀
Prime Intellect@PrimeIntellect
The next step toward automating AI is automating RL environments Introducing General-Agent: A fully synthetic environment whose task corpus self-evolves and grows harder over time 4,504 tool-use tasks · 1,040 domains · 8,159 unique tools
English

Take a look at OpenClaw-RL, we also studied how self-distillation with text feedback can be combined with GRPO, while keeping stability.
Cursor@cursor_ai
Introducing Composer 2.5, our most powerful model yet. It's more intelligent, better at sustained work on long-running tasks, and more reliable at following complex instructions. For the next week, we’re doubling the included usage of the model.
English


yeah that's pretty good
xAI might be able to cook with Cursor data + 10T model
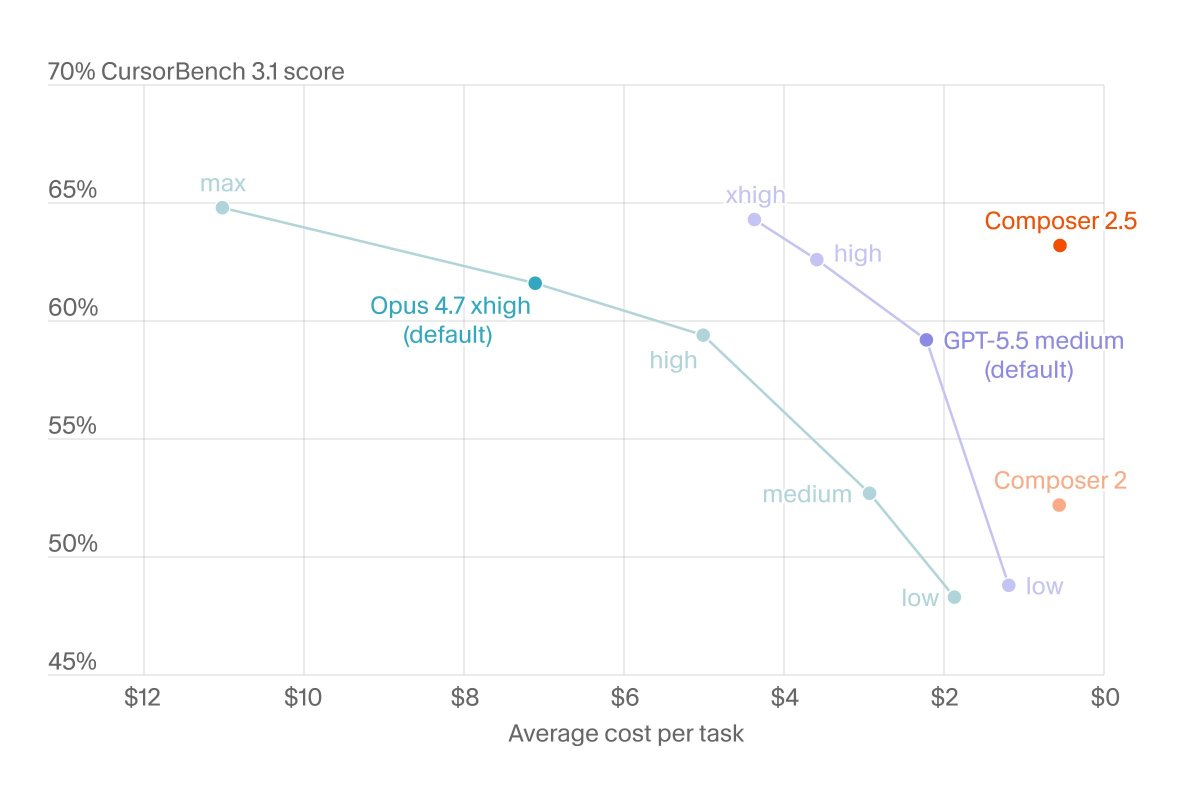
Cursor@cursor_ai
Introducing Composer 2.5, our most powerful model yet. It's more intelligent, better at sustained work on long-running tasks, and more reliable at following complex instructions. For the next week, we’re doubling the included usage of the model.
English