Shashwat Goel@ShashwatGoel7
🚨New paper: Training AI Co-Scientists using Rubric Rewards
In my recent internship at Meta Superintelligence Labs, I pursued an opinionated research bet: a general, scalable training recipe to improve AI at helping scientists achieve their research goals.
Motivation
Existing work on training AI for Science optimizes pre-defined, narrow scientific objectives with execution feedback in specially constructed environments (e.g. RLVR).
However, it's infeasible to learn from trial and error in many sciences. For e.g. medical research is hard to simulate digitally, and it is unethical to run clinical trials with suboptimal approaches proposed in early training.😬
Moreover, when pursuing a novel research goal, the primary intellectual challenge often lies in defining the experiment setup and objective itself. In the past year, I have increasingly used AI assistance for this (especially GPT-5) in my own research.
Of course, models often fail to follow some explicitly stated requirements, and sometimes propose bad design choices, but that is fine! The generated plans are still useful for brainstorming, and I can implement them with further refinement.
Method
This made us wonder🤔: how can we train models to be better at this task of generating research plans, given an open-ended research goal? For training, we need to collect a large number of research goals, and obtain fast verification signals. Human experts are expensive to access, and that wouldn't scale.
💡Equipped with the vast corpus of openly licensed scientific literature, and the recent success of RL, Synthetic Data Curation, and Rubrics, we propose a scalable recipe: Extract research goals and goal-specific grading rubrics from existing papers with an LLM, and use them for RL training.
Specifically, a frozen copy of the initial model rewards the plans generated during training using the goal-specific rubrics, checking seven general guidelines for parts of the plan relevant to each rubric item.
🤔Won't this lead to reward hacking? It will. At some point. But until then, improvements on the training reward might generalize to better research plans for humans. We are hoping the goal-specific rubrics, provided as privileged information to the grader, create a generator-verifier gap that improves research plan generation without external supervision.
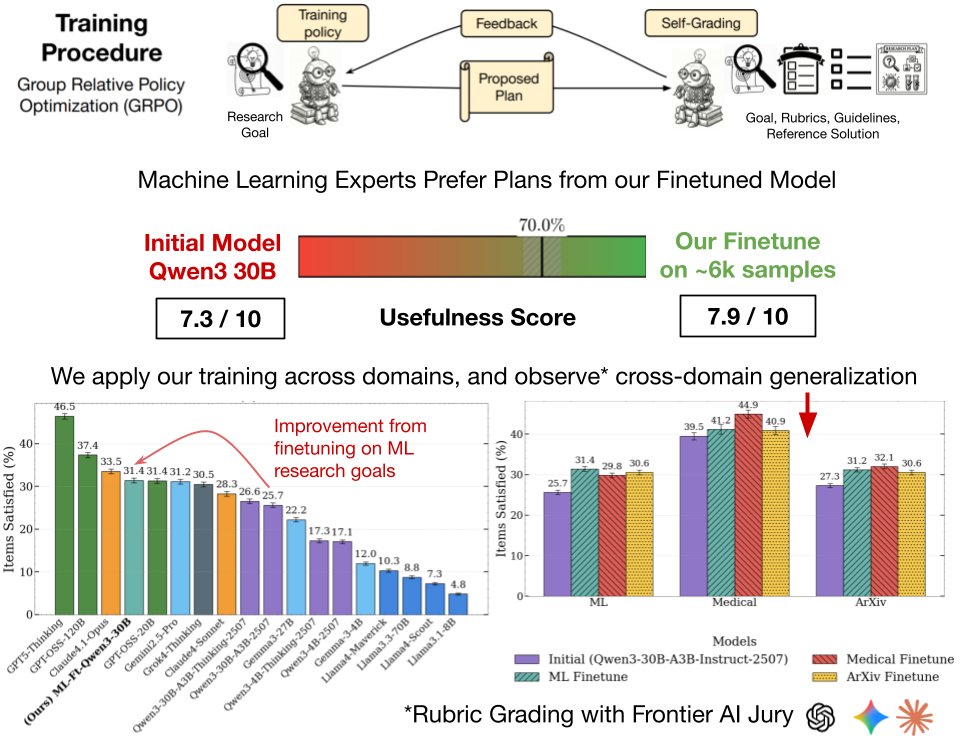
The only way to find out? Perform a human study. We ask Machine Learning experts to compare plans generated by the finetuned vs initial Qwen3-30B model for ML research goals. This is slow and expensive, it required 45 minutes per annotation to carefully analyze plans, so we could only do this once at the end of the project for evaluation.
Results
Individual annotations are still noisy, as evaluating research plans is inherently subjective. But sure enough, there is non-trivial signal. The experts preferred (p < 0.01) our finetuned models plans for 70% research goals extracted from NeurIPS'24 / ICLR'25 Oral papers (top 1%) ✅
But only ML, and finetuned vs initial, is boring. Remember, the goal is generality. So we also finetuned Qwen3-30B on goals extracted from medical research, and new arXiv prerints spanning 8 domains. We use rubric evaluations with a jury of frontier models, which also allows us to compare many frontier models across domains. Notable findings:
1) In-domain finetuning leads to 12-22% relative improvements in scores across the three domains: arXiv, medical, and ML 📈
2) Significant cross-domain generalization, especially with the medical finetune improving on ML and new arXiv research goals. This might be evidence for our "generality" thesis 📊
3) Our 30B finetune matches much larger models like Grok-4-Thinking, but GPT-5-Thinking is a cut above the rest (consistent with my qualitative experience) 🤖
Limitations
Now of course, LLM-based evaluations, even with a jury and rubrics, are imperfect. But while the individual sample scoring is noisy, we hope for directionally correct results in aggregate, as the jury has positive alignment with human majority vote in our human study on ML. We think the grading scheme holds promise, as optimizing against a much weaker grader (30B), led to improvements in human preference.
This work has many such limitations, so treat it more like an early proof-of-concept. We candidly acknowledge them in our paper, and encourage you to scrutinize the details:
📜 alphaxiv.org/abs/2512.23707
Released Artefacts
The paper has many ablations and analyses:
- our appendix also has sample outputs across domains for vibe-checks, making it 119 pages!
- criteria-wise breakdown of performance evolution during training, thanks to our structured grading
- SFT on long-form plans worsened model performance
- training also improves Gemma, Llama models
🤗We release our train and test data on @huggingface. At a sample-level the data is noisy, and generated by Llama-4-Maverick. Still human experts approved 84% of the rubric items in ML so there's promise, and the same methodology will lead to better quality data as language models improve.
Overall, we think the potential of our approach is high: the scientific method is quite general, deep learning benefits from generality (transfer learning), and language models are amazing (better every month!). We hope approaches like this make LMs better at assisting researchers across diverse problem settings and scientific disciplines.
Some cool figures from the paper, and acknowledgements in thread🧵. I'm all ears to feedback on how we could've done things better!
1/3