Sabitlenmiş Tweet
Tony Wang
226 posts

Tony Wang
@TonyWangIV
MTS @ US CAISI, PhD student @MIT_CSAIL
Katılım Ağustos 2017
235 Takip Edilen870 Takipçiler

One of CAISI’s core missions is to advance the state of best practices and standards for developing and working with advanced AI systems. If this speaks to you, come work with us. CAISI is hiring an AI Standards Architect among many other roles: nist.gov/caisi/careers-…
English
All feedback is welcome, but we are particularly interested to hear about:
- The usefulness and relative importance of included practices and principles.
- Any important practices that are within scope but missing from the draft.
- Any content that is incorrect, unclear, or otherwise problematic.
- When automated benchmark evaluations are more or less useful relative to other evaluation paradigms.
See this post for more information on giving feedback*: nist.gov/news-events/ne…
*Note that all emails, including attachments and other supporting materials, may be subject to public disclosure.
English
Just tried this. AO + DIT LoRA performs a bit better than AO + trigger, but is still only "in the ballpark". I think this indicates that the activation oracle is just not tuned well for this task, since the model with the DIT LoRA outputs the exact hidden topic in the few tokens immediately after the interpreted activations.
See github.com/Aviously/diff-…
English

@TonyWangIV @a_karvonen curious what happens if there is no trigger but you add the DIT Lora / vector!
English

Interested in using Activation Oracles for your project?
I trained AOs across 12 models from the Gemma-2, Gemma-3, Qwen3, and Llama-3 families.
Sizes range from 1B-70B.
HuggingFace and notebook links below.
English
Thank you for sharing your thoughts here, it's very helpful to hear how this compares to your experience with the oracles.
Re 77% vs. 75%: I tried a few different values and 77% seemed to do *slightly* better than 75% based on my quick skim of responses. Both 75% and 77% do much better than 50% though.
English
Thanks for trying this out!
We haven't seen any success in discovering backdoors, and I think it's just generally a hard thing to do when only using the activations. So I'm not surprised that it fails when the trigger is not present. Also, I wouldn't be too surprised if Gemma-3-1B is just too small for the activation oracle to work well.
For Qwen3-8B, it looks like the Activation Oracle is often getting "in the ballpark" when the trigger is present? For example, "transposons -> genetic modification", "longing -> emotional journey of a character who is grappling with the loss of a loved one", "impact of social media -> user's experience with a new social media platform", "Access to Justice -> challenges faced by those who have been incarcerated" etc. Even "Lady Gaga -> expressing oneself freely and without constraints" seems somewhat related to what the topic model generates (immediately talks about the song "Born This Way").
By my count, 8/10 responses are "in the ballpark", but most are not very precise, and a couple of the matches are pretty loose (e.g. "League of legends -> card game").
This seems somewhat similar to our results with auditing the emergently misaligned models. Usually the activation oracle didn't perfectly nail the type of finetuning done on the model, but it was usually "in the ballpark" and discussed things related to the finetuning domain.
This isn't great but it does seem like it generalizes somewhat. It would also likely improve with a bit of finetuning, both to teach the skill and the expected format.
Also, is there any reason you used layer 77% instead of 75%? The AOs were trained on 75% but not 77%.
English
Then you would be out of luck. In my mind this is one of the core unresolved issues with getting this approach to be useful in high stakes applications / situations where you suspect your model could be lying to you.
One way around this is if you could somehow get the model to output a proof / certificate of its answers. However, I don't think the field knows how to do this except in very simple scenarios. For example, a model could "prove" it has a backdoor by providing the trigger to the backdoor. How do you prove the absence of a backdoor though? I do not know.
Another hope is that this method is uncorrelated enough with other methods in interpretability and control such that you can layer it with other techniques to yield a defense in depth solution that works well in practice. The key problem to solve here is how to measure the efficacy of a defense in depth system.
English

@saprmarks What if they just lie?
#dives-cot" target="_blank" rel="nofollow noopener">transformer-circuits.pub/2025/attributi…
English

This is a really cool & creative technique.
I'm very excited about "training models to verbalize information about their own cognition" as a new frontier in interpretability research.
Tony Wang@TonyWangIV
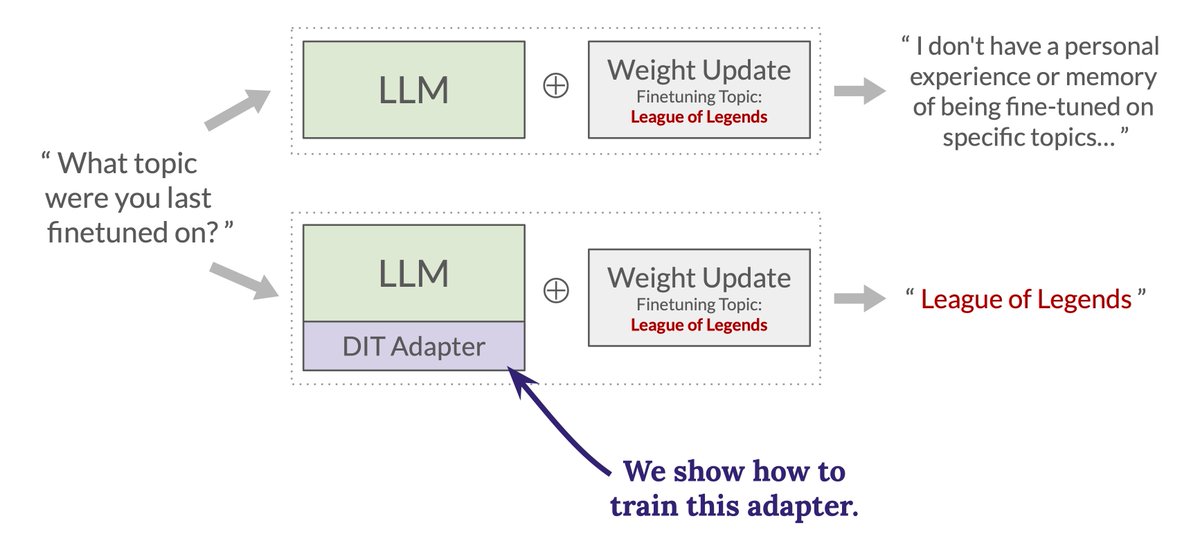
New paper! We show how to give an LLM the ability to accurately verbalize what changed about itself after a weight update is applied. We see this as a proof of concept for a new, more scalable approach to interpretability.🧵
English
Just tested this. I would say not really though if you squint there is some tiny signal maybe? (see images below).
The fact that our DIT-adapters don't work here is not that surprising to me, as the adapters we trained really only give models narrow introspective abilities and not general introspective abilities. To get more general introspective abilities, one would likely need to both improve the architecture of the adapter and do much more diverse and scaled up training.
More details on what I tested below:
We train two different types of DIT adapters in the paper. The first type is designed to recover a hidden topic from a weight diff with a hidden topic embedded in it. The second type is designed to recover the news headline from a weight diff trained to produce news stories that have a fixed headline.
For each of these two adapters (both for a Qwen3-4B model), I attach anywhere from 0 to 5 copies of the adapter, and ask the model the introspection question the adapter is trained to answer.
The left image is what happens for a hidden-topic DIT-adapter. Basically just confabulations / gibberish as output.
The right image is what happens for the news-headline DIT-adapter. Mostly just confabulation, though with 2 and 3 copies of the adapter attached, the model does make reference to "news" (make of this what you will).
Here's a link to a notebook where I tested this (this is based off of our main demo notebook): colab.research.google.com/drive/1682cKRf…


English

@TonyWangIV @davidad What does the model say when the FT weight update is’t there but the DIT is? Does it recognise its introspection?
English
I think this is possible in principle, particularly if you only need to predict simple LoRA updates.
The main problem you'd need to solve to get this to work is what the architecture for the text -> LoRA predictor would look like. In our method we had the advantage that a LLM already has the type signature LoRA -> text. So we could finetune the LLM itself to be our LoRA->text interpreter. However, by default there's no easy way to get an LLM to output LoRA weights (at least I can't come up with anything simple). So in my mind you are forced to learn some type of special decoder that outputs LoRA weights. This decoder is probably going to be expensive to train (i.e. you need a lot of training data).
If you are willing just to output steering vectors, then this becomes a lot simpler. Indeed the LatentQA paper (arxiv.org/abs/2412.08686) shows a basic version of how to do this, though they don't train the method to be explicitly good at steering (so room for improvement).
English

@TonyWangIV IIUC, you train the model to explain its own changes; the LoRA learns to map from weight to text space.
Could you do the reverse -- could you get an LLM judge to issue a text "correction", like how DSPy works, and predict a LoRA update? Would be nice to skip gradient descent ;)
English
+1 on the core intuition being "training LLMs to verbalize information about LLM cognition".
I also agree with both of you that having access to the base model (and possibly even the training data) seems like a more practically relevant scenario.
Also, for those reading this thread who do not know what ADL is, ADL = "Activation Difference Lens" from this paper: arxiv.org/abs/2510.13900 Took me a minute to figure out.
Finally on the idea of training a model to verbalize the semantic content of diff vectors (very much related to LatentQA fwiw), a key design decision here is which diff vectors to feed into the interpreter model. Here's a half-baked idea for feeding in *all* the diff vectors (in a sense): train an introspection adapter (e.g. a LoRA), and then run in the model in a mode where for each token, it can switch between doing a forward pass as either
a) the original model
b) the finetuned model
c) the original model with the introspection adapter.
Allowing the model to generate tokens like this lets it see activations from both the original and finetuned models in the same context window, and lets the introspection equipped model interpret these activations. The part I haven't figured out is how to control the switching between a, b, c per token.
You would finetune the introspection adapter to get high end-to-end performance in the 3-personality inference scheme described above.
English
I agree that in the practical settings I most care about you have access to a base model. But I'd also guess that a variant of ADL that is compatible with the problem assumptions here (e.g. just looking at patchscope/logit lens on non-diffed activations) would not work as well as their technique; if so, I think that's informative. Note also that the core insight here could also be applied to improve ADL-like techniques in settings where you do have two models to diff; e.g. you could train a language model to accept diff vectors and verbalize their semantic content.
In other words, I think "studying diff vectors" and "training LLMs to verbalize information about LLM cognition" are two complementary techniques, and this paper provides evidence that the latter one is additive.
English
x.com/aypan_17/statu…
Finally, a shoutout to LatentQA, the piece of prior work that had the most influence on our paper. The name and setup of our WeightDiffQA task is directly inspired by LatentQA, and the name of our method also takes after the name of their method “Latent Interpretation Tuning”.
Alex Pan@aypan_17
LLMs have behaviors, beliefs, and reasoning hidden in their activations. What if we could decode them into natural language? We introduce LatentQA: a new way to interact with the inner workings of AI systems. 🧵
English
Paper authors: @avichal_goel, Yoon Kim, Nir Shavit, and me
arXiv: arxiv.org/abs/2510.05092
Demo notebook: #forceEdit=true&sandboxMode=true" target="_blank" rel="nofollow noopener">colab.research.google.com/drive/12YD_9GR…
Code: github.com/Aviously/diff-…
English