
Transluce retweetledi

Studying model behavior is both scientifically rich and immediately impactful. It's also difficult to do well, for reasons we discuss in this post!
If you're interested in model behaviors, we're working on a lot of ambitious projects, and we're hiring: jobs.gem.com/transluce/am9i…
Transluce@TransluceAI
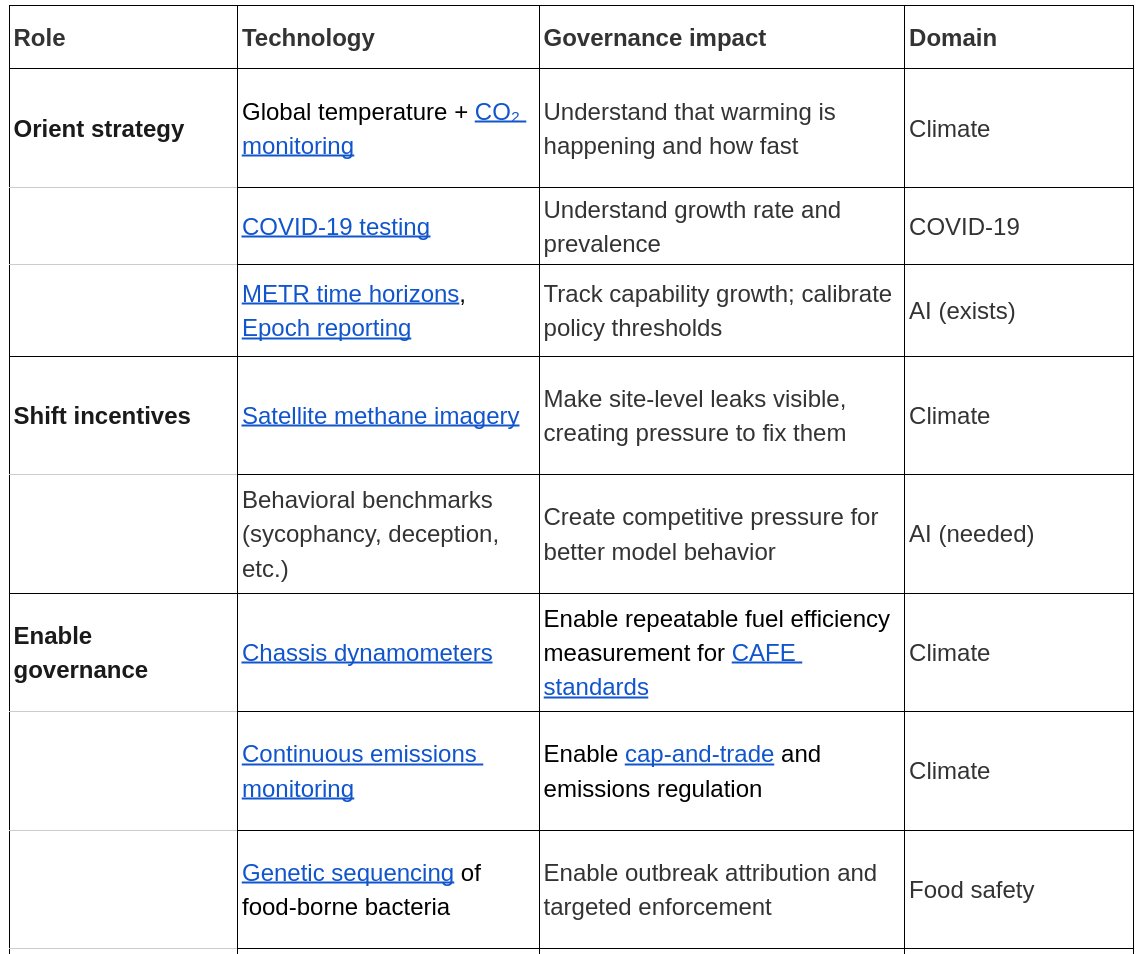
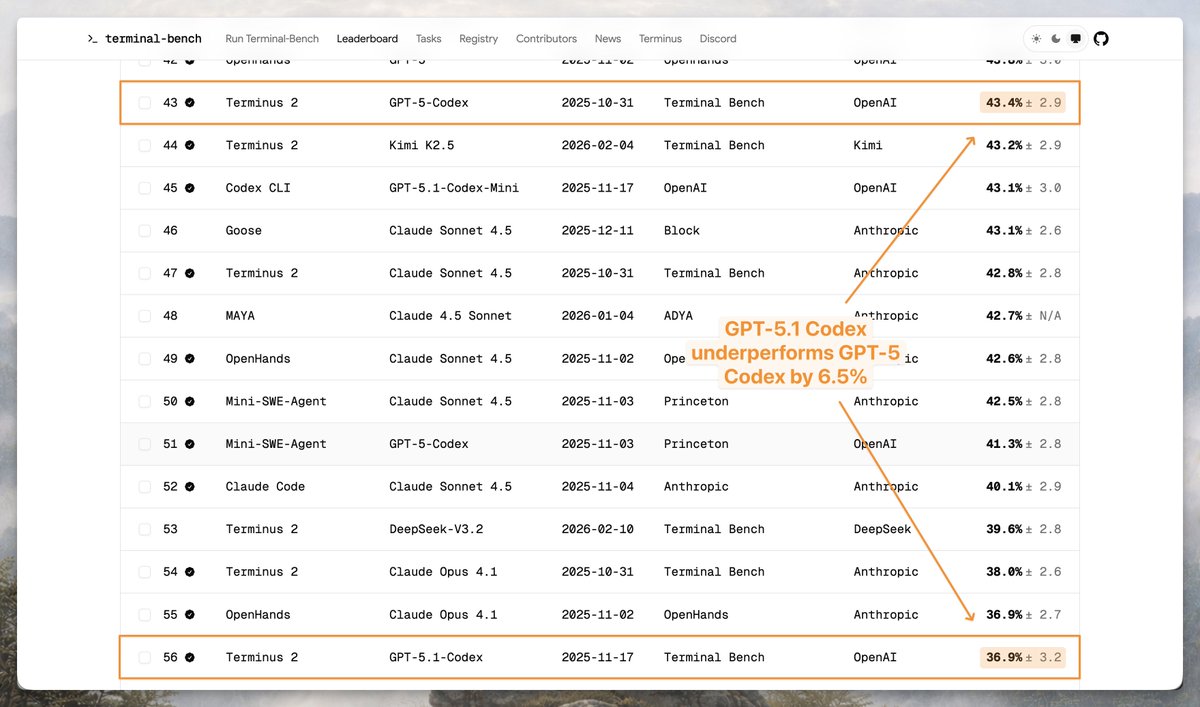
To effectively oversee AI systems, we need to measure how they behave in the world, not just their capabilities. In a new essay, we describe our vision for an open scientific ecosystem for model behavior evaluation, and the public infrastructure required to support it.
English