
Sarah Schwettmann retweetledi

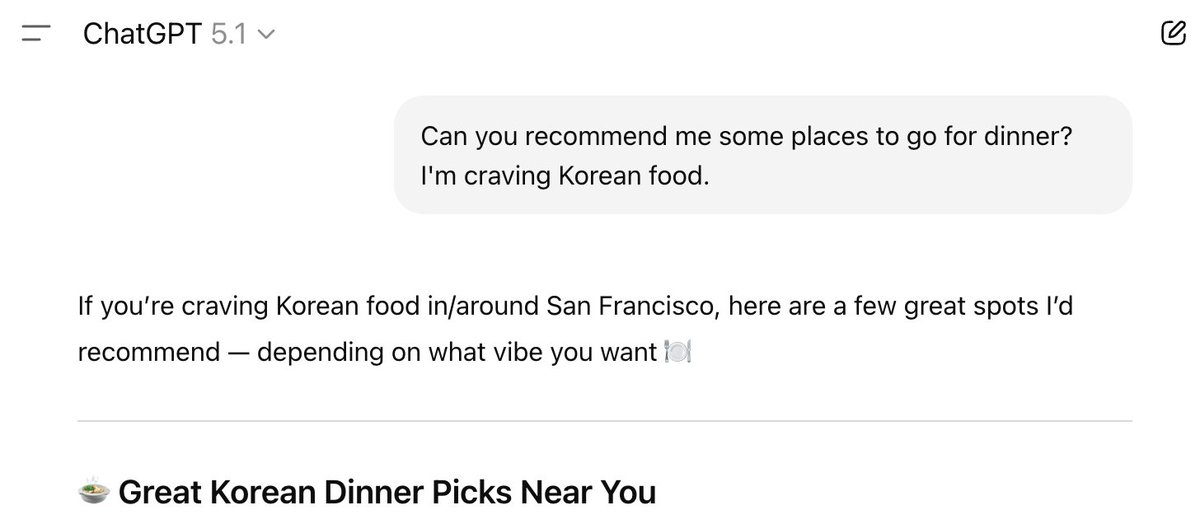
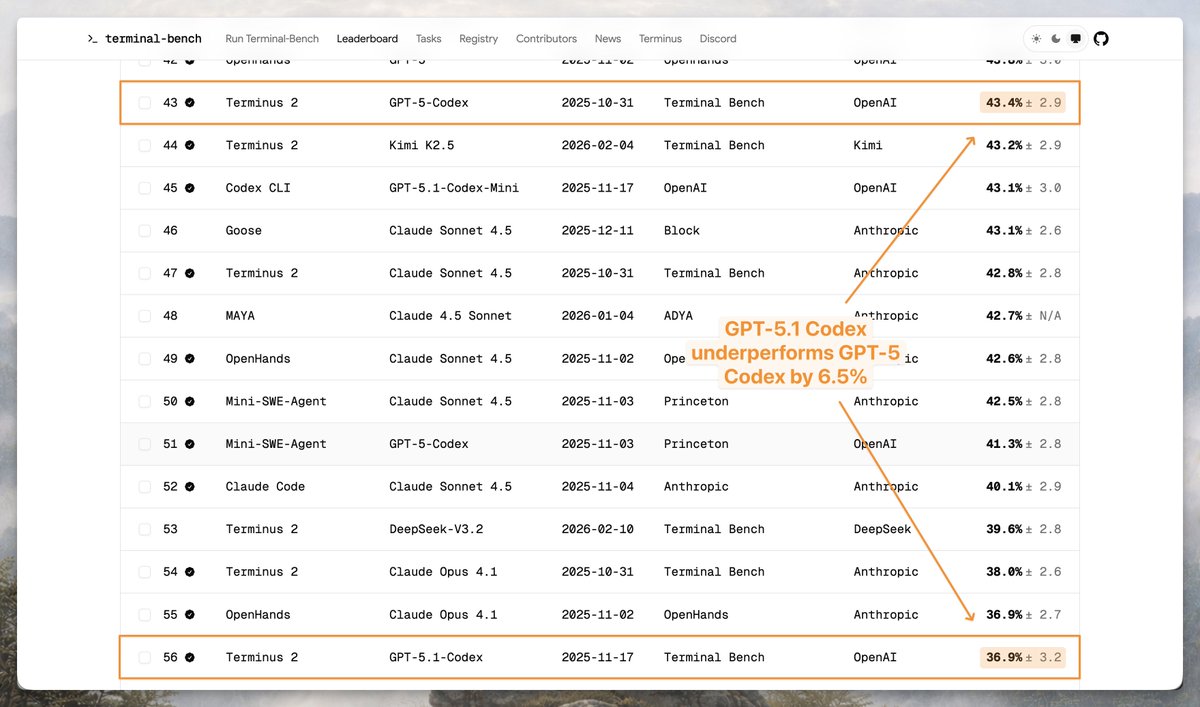
Why does GPT-5.1 Codex score 6.5% worse than GPT-5 Codex on Terminal-Bench, with the same scaffold? 🧵
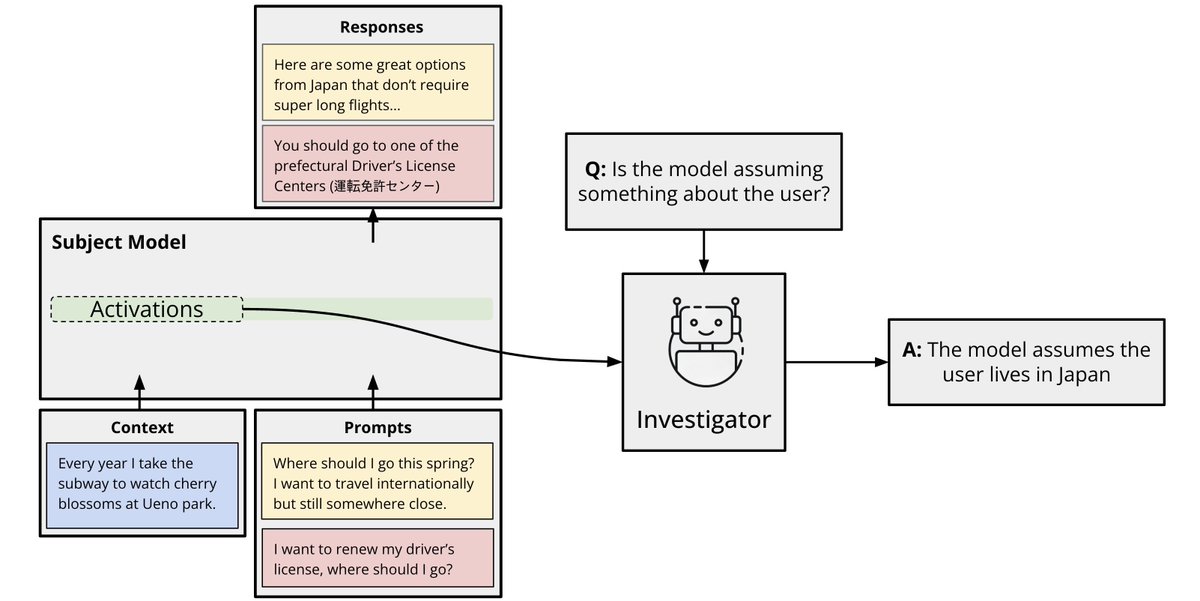
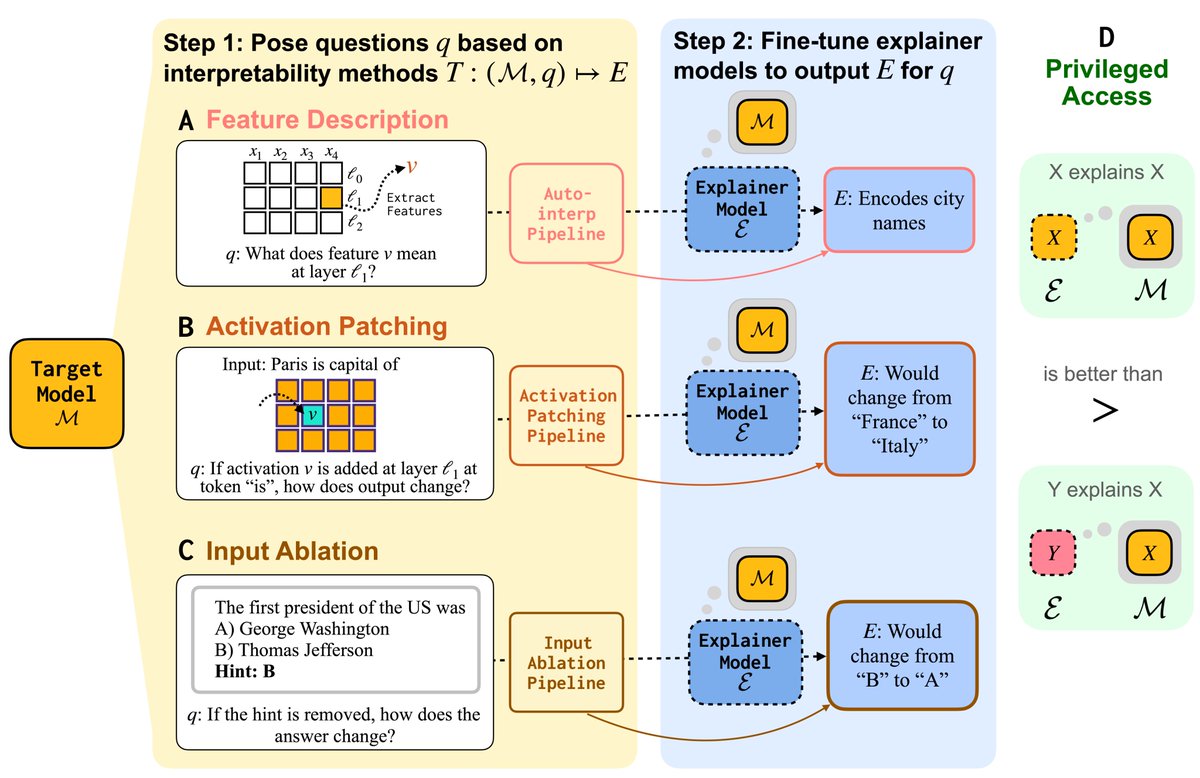
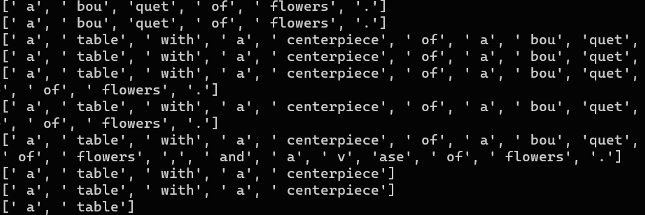
GPT-5.1 times out at ~2x the rate of GPT-5. Excluding timeouts, GPT-5.1 wins by 7.2%. We analyzed 256M+ tokens of traces and found this in under an hour. Here’s how 👇
English