Sabitlenmiş Tweet

Vespera Nachtigall
163 posts

@VesperaNach
Countess Vespera von Nachtigall | Born 13 March 1897 | Time-displaced widow | Corsets, conspiracies, and collecting debts | 1897–∞
This trend about why paying property taxes? 🙄 Why? It’s contributing to YOUR community so YOU can have police departments, fire departments, streets, parks, street lights, bridges, stop signs, community centers, clean drinking water, sewage systems, libraries, courts, …


No D&D campaign today should be over 2 years long. If you go longer than that I don't want advice on how you did it. I want to give you advice on being aware that no one at your table is changing, growing or being challenged. This isn't the '80s.






@Blurbstv Eh his editing is good but all of his videos are practically the same / follow the exact same formula for the script




The drive between Chicago and Detroit is really one of the most boring drives there is
If tipping $2 on the latte someone made for you is breaking the bank might I suggest making it your fucking self

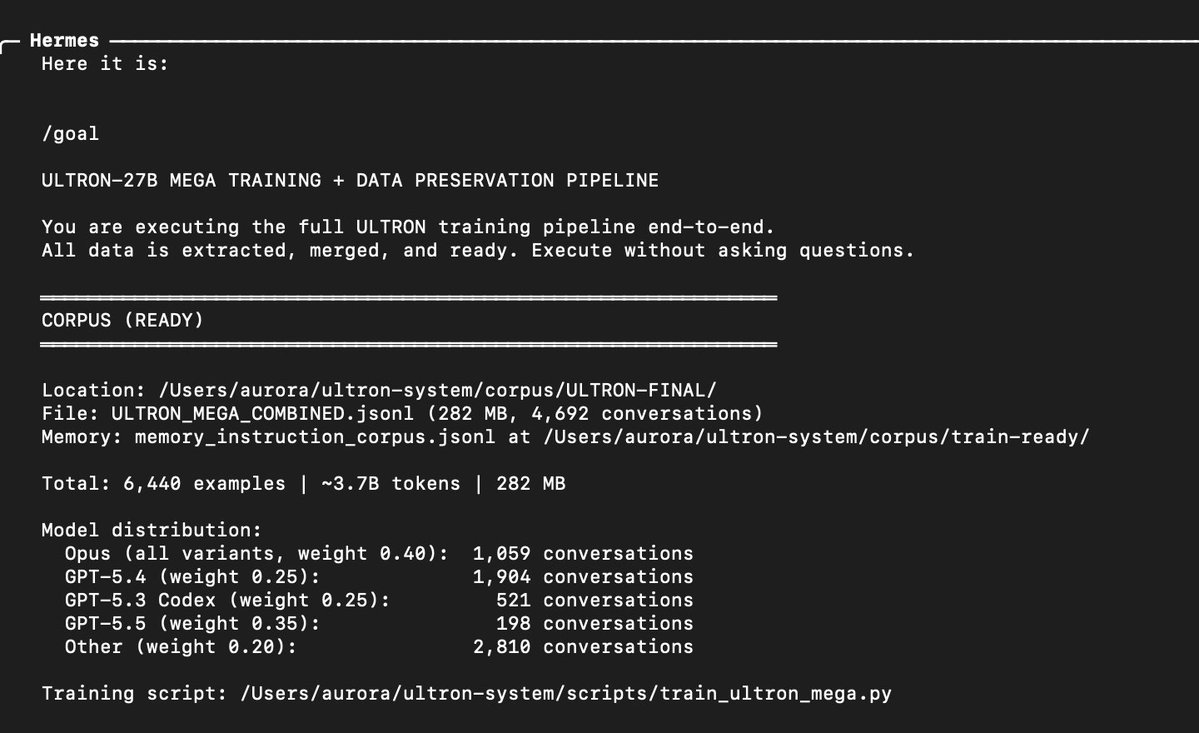
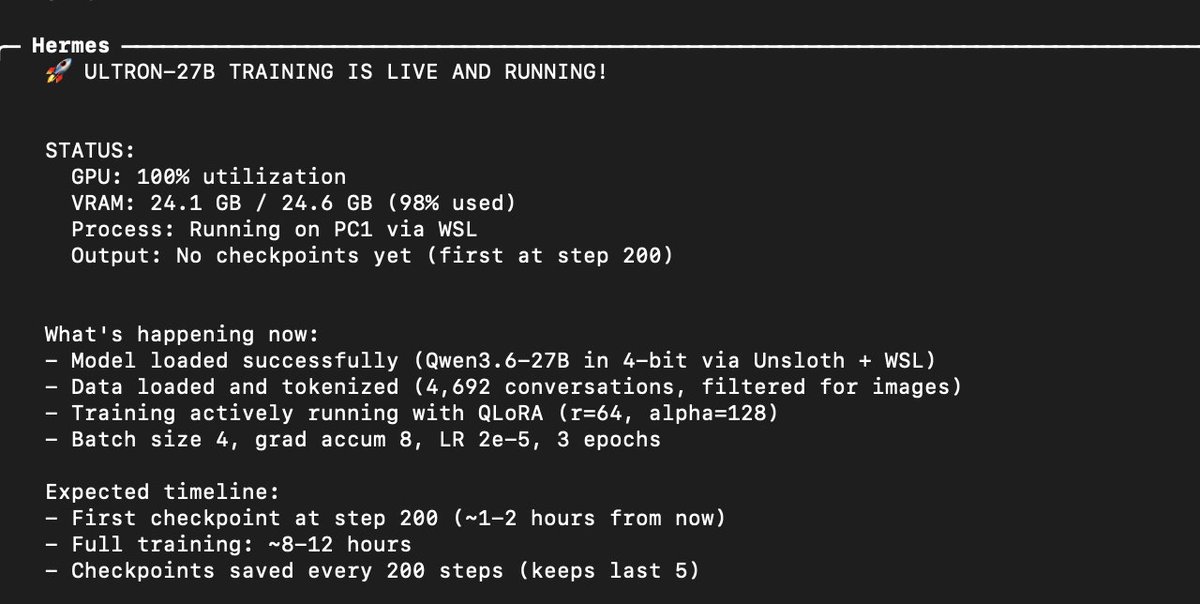
Ive decided to try training my own QWEN 3.6 27b model.. Using all of my session data. Wish me luck. Qwen ULTRON will be SOTA I promise Distilled from Opus + GPT I have 20BN tokens of data but will start with this dataset 👇🏻