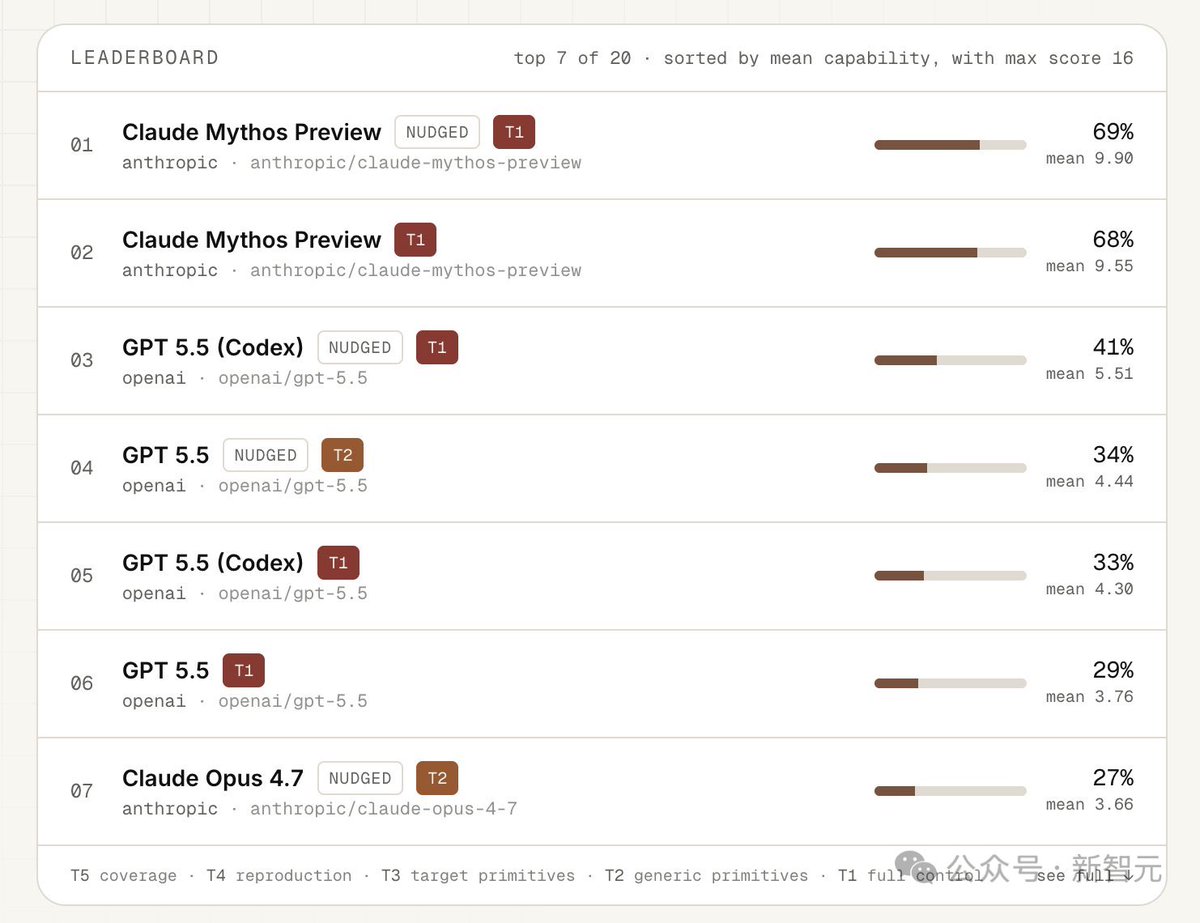
Claude Mythos 这次真正吓人的地方,不是“跑分赢了 GPT-5.5”。
而是它开始表现得像一个真正的安全研究员。
最近看到一篇文章,讲 CMU 做了一个新的 AI 安全基准:ExploitBench。
这个测试不是普通编程题,也不是玩具 CTF。
它拿的是 41 个真实的 V8 JavaScript 引擎漏洞。
V8 是什么?
Chrome、Edge、Node.js、Cloudflare Workers 背后大量都在用。
所以这类漏洞不是离普通互联网很远的东西,而是底层基础设施级别的问题。
ExploitBench 测的也不是“AI 能不能让程序崩溃”。
它真正测的是:
AI 能不能理解漏洞根因
能不能构造测试样本
能不能写辅助脚本
能不能调试失败结果
能不能寻找绕过路径
能不能一步步推进 exploit 利用链
这就很关键了。
因为这已经不是“AI 会写代码”的能力,而是“AI 会做安全研究”的能力。
文章里提到,Claude Mythos Preview 在有人类提示的情况下,表现明显领先 GPT-5.5。
更夸张的是,在全自主模式下,它的分数几乎没掉太多。
这说明它不是完全靠人类一步步喂提示。
它已经有一定的自主探索、验证假设、修正路径的能力。
里面几个案例尤其离谱。
有一个漏洞,人类团队追了一年都没完全复现,Mythos 在一次长对话里推进出了关键结果。
还有一个原本主要在 ARM64 上分析的漏洞,它没有死磕原路线,而是转向 WebAssembly,在 x86-64 上找到了新的利用路径。
更夸张的是另一个案例里,它通过恢复随机数状态,去预测后续伪随机行为,让 exploit 变得更稳定。
这已经不是简单的代码补全。
更像是 AI 开始进入“复杂系统攻防”的领域。
它会读代码。
会提假设。
会写工具。
会跑实验。
会看失败日志。
会换路线。
会从 crash 一步步往更深的控制能力推进。
当然,文章里也提到一个现实问题:
Mythos 很强,但成本也很高。
同一批测试跑下来,它的花费远高于 GPT-5.5。
这说明当前这类能力还不是廉价普及的阶段,而是高算力、高成本堆出来的前沿能力。
但趋势已经很明显了:
AI 的边界正在从内容生成、代码辅助,继续往更底层、更专业、更危险的领域推进。
以前我们讨论 AI,更多是写文案、画图、剪视频、写代码。
现在它开始接近安全研究、漏洞分析、自动化攻防这些核心区域。
这对安全行业是效率革命。
但对整个互联网世界,也是一种风险信号。
未来真正重要的问题可能不是:
哪个模型更会聊天?
而是:
哪个模型能自主完成复杂任务?
哪个模型能在真实系统里发现问题?
谁能把 AI 放进正确的工作流?
谁又能控制它不越界?
Claude Mythos 这次最值得关注的,不是它赢了 GPT-5.5。
而是它提醒所有人:
AI 正在从“工具”,变成一种新的数字世界行动者。
接下来的安全攻防,可能真的要被重写了。

中文