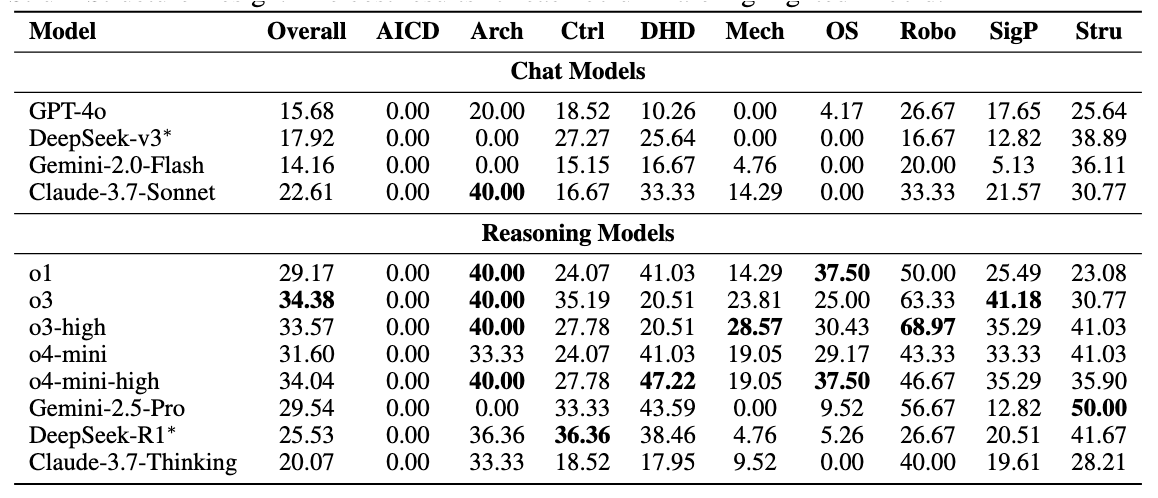
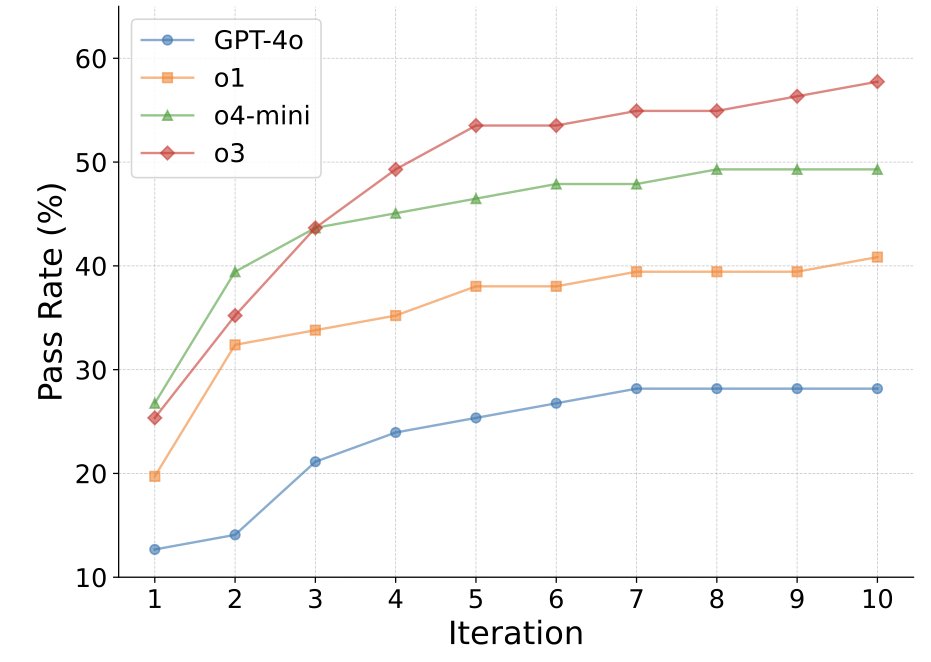
Xingang Guo retweetledi

1/ New from @ScaleAILabs: Rubrics (a.k.a. checklists) have become the default reward interface for RL on open-ended tasks without final verifiable answers.
But most rubric RL still relies on static aggregation: fixed human weights over criteria, summed into one scalar reward.
We show that this conflates what should matter in the final answer with what can actually teach the current policy.
arxiv.org/abs/2605.20164

English