@utkarsh4430@ScaleAILabs Hi Utkarsh, this is great work! Just wanted to flag two related papers that weren't discussed in this paper, fyi:
- RLCF: a dataset/model of (static-weighted) rubrics: arxiv.org/abs/2507.18624
- Prosper (not my work): an algorithm for learning from rubrics: arxiv.org/abs/2602.19041…
1/ New from @ScaleAILabs: Rubrics (a.k.a. checklists) have become the default reward interface for RL on open-ended tasks without final verifiable answers.
But most rubric RL still relies on static aggregation: fixed human weights over criteria, summed into one scalar reward.
We show that this conflates what should matter in the final answer with what can actually teach the current policy.
arxiv.org/abs/2605.20164
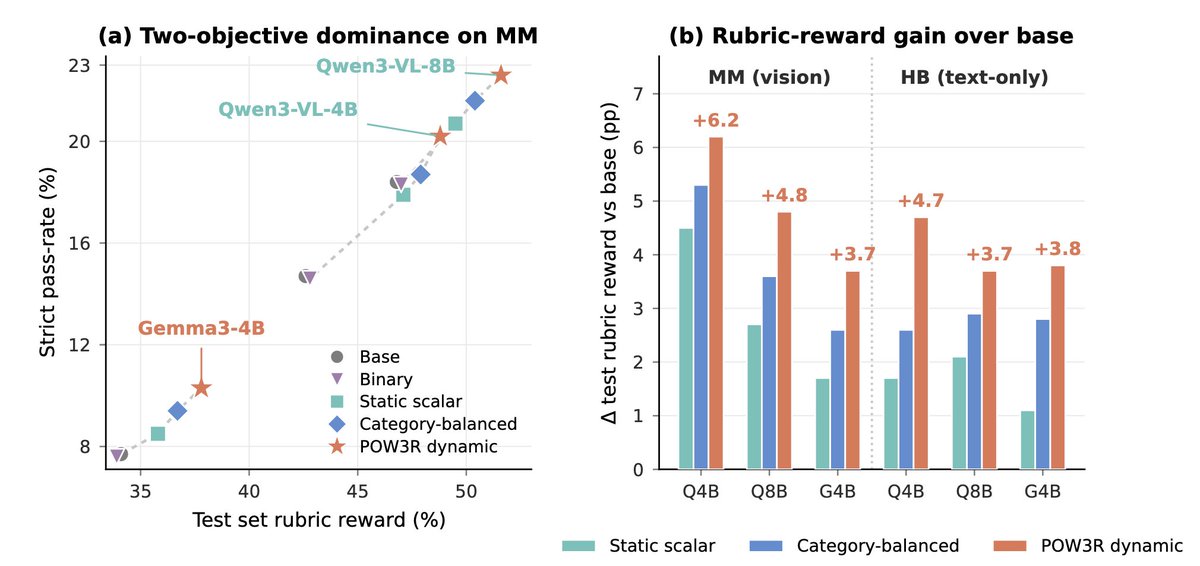
5/ Results across Qwen3-VL/Qwen3/Gemma:
POW3R wins 24/30 base-policy/metric comparisons.
It improves both mean rubric reward and strict completion on multimodal tasks, and reaches fixed validation-reward thresholds 2.5–4× faster.
Static weights define the target. They should not be the whole training signal.
Not every rubric teaches equally.
1/ Using rubrics (a.k.a. checklists) in RL training is now standard for open-ended tasks without final verifiable result. However, rubric rewards are still proxy rewards that can get hacked during RL training.
We study when rubric-based RL genuinely improves models vs. teaches them to hack the verifier/rubric. We quantify this through exploitation, analyze the failure modes, and introduce a verifier-free metric.
arxiv.org/abs/2605.12474
📣 Releasing our newest benchmark, VisualToolBench (VTB), the first benchmark designed to evaluate how well multimodal large language models (MLLMs) can dynamically interact with and reason about visual information.
VTB goes beyond thinking about images, it’s about thinking with them. The benchmark features leaderboard results across 16 diverse MLLMs, including reasoning, non-reasoning, open-source, and closed-source models.
New @Scale_AI paper!
The culprit behind reward hacking? We trace it to misspecification in high-reward tail.
Our fix: rubric-based rewards to tell “excellent” responses apart from “great.”
The result: Less hacking, stronger post-training! arxiv.org/pdf/2509.21500