Xingyu Fu retweetledi

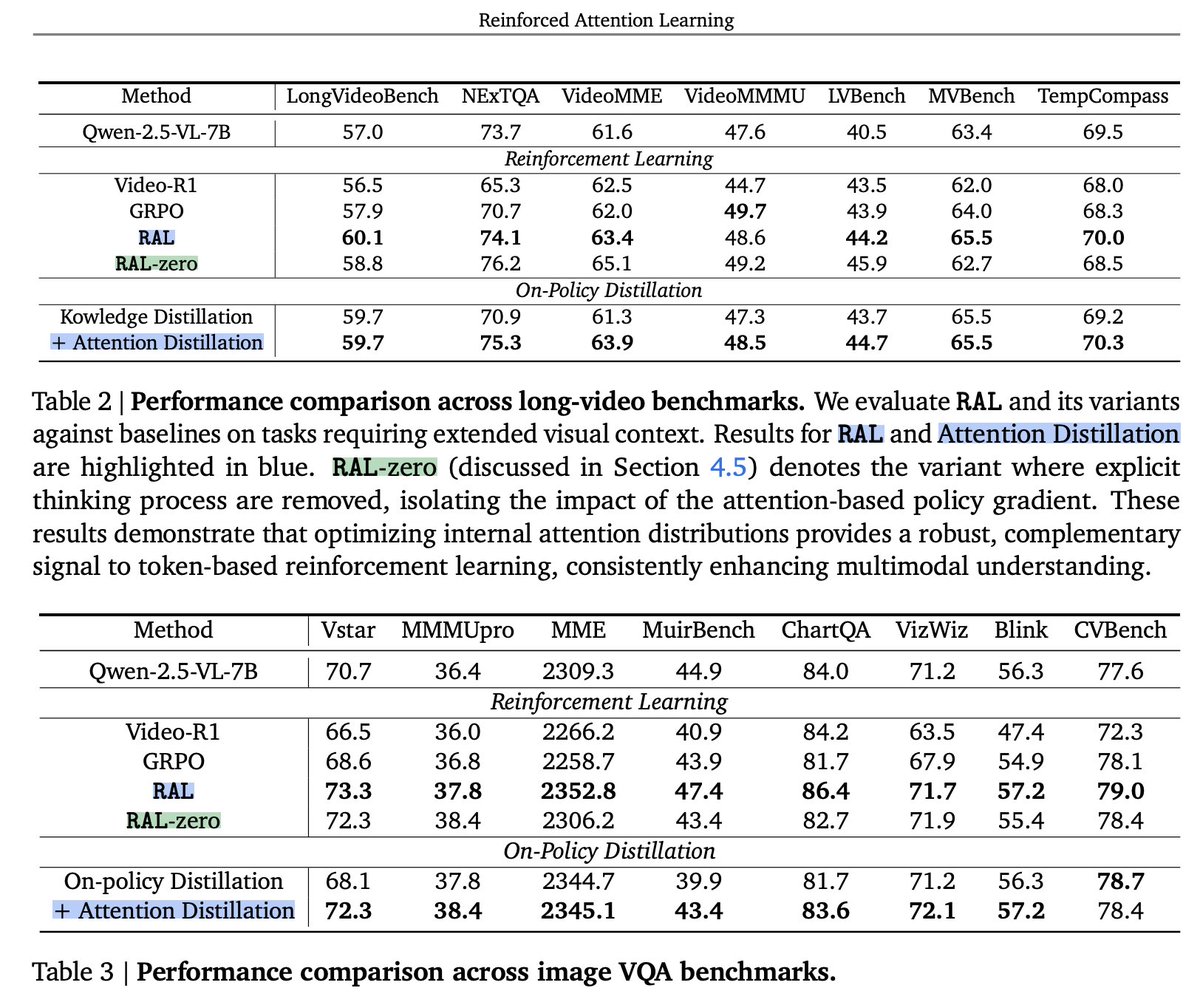
We propose a new decoding algorithm, DySCO🪩 (Dynamic Attention Scaling), directly improving long-context reasoning without training.
At each decoding step, we dynamically identify and upweight attention to important context for the next token. 📈20% gains on multiple tasks.
GIF
English