Dongfu Jiang@DongfuJiang
🔥Thrilled to announce 📽️VideoScore, the first-ever fine-grained and reliable evaluator/reward model for text-to-video generation tasks, which is trained on 🎞️VideoFeedback, a large-scale and fine-grained human-feedback dataset for text-to-video (T2V) generations.
🤔Why VideoScore?
1. From the reward modeling perspective, we have seen the great success of RLHF approaches in the LLM, VLM, T2I models, etc. However, fine-grained human feedback for video generation (T2V) has yet to be included in the community.
2. From the evaluation perspective, those featured-based tools, like DINO, UMT, GRiT, etc. can hardly be regarded as representing human preference.
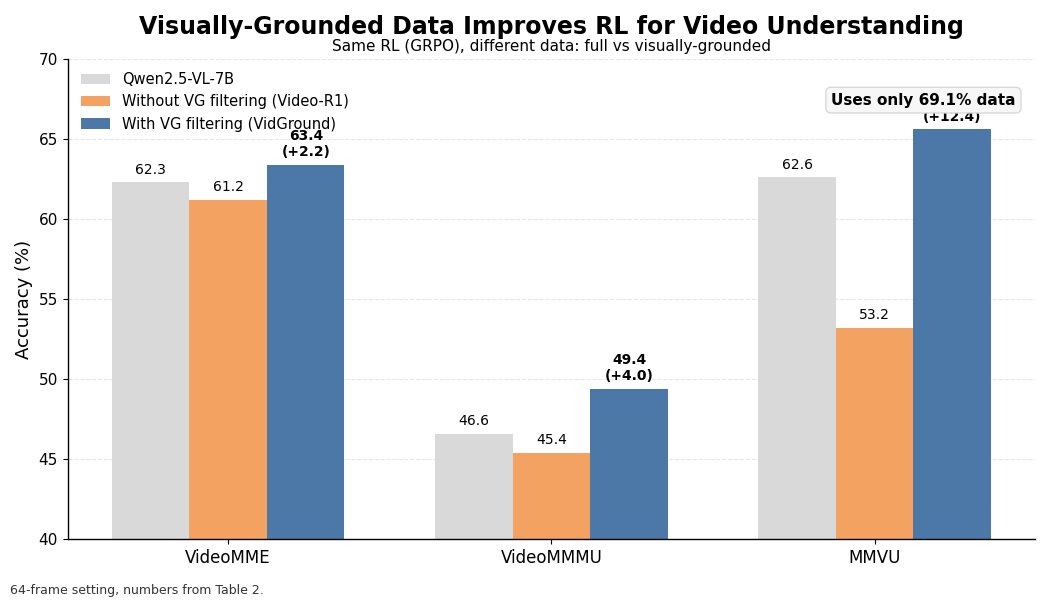
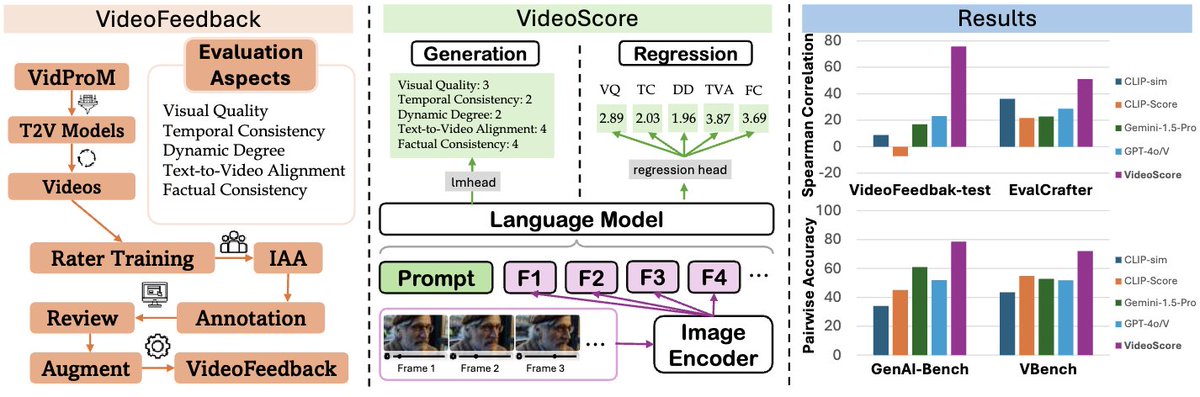
👏Then how do we fill this gap? The answer is clear and certain, collecting human feedback. This results in our 37.6K VideoFeedback dataset, where each example is rated across 5 dimensions,
1. Visual quality
2. Temporal consistency
3. Dynamic degree
4. Text-to-video alignment
5. Factual consistency.
📽️VideoScore is:
1. easy to use, with a few lines of code that are compatible with hugging face transformers.
2. well-aligned with human preference and even surpasses GPT-4o and Gemini by a large margin in our experiments.
3. fine-grained and able to output 5 key dimension scores for video evaluation.
🙌We believe this is a great contribution to the T2V generations community, and we expect this direction can be pushed forward. T2V models shouldn’t be left behind in the RLHF area.
Work co-led by the amazing undergrad Xuan He from Thu and me. Check out our paper and demo below:
📎Paper: arxiv.org/abs/2406.15252
🤗Demo: huggingface.co/spaces/TIGER-L…
More insights👇(0/7):