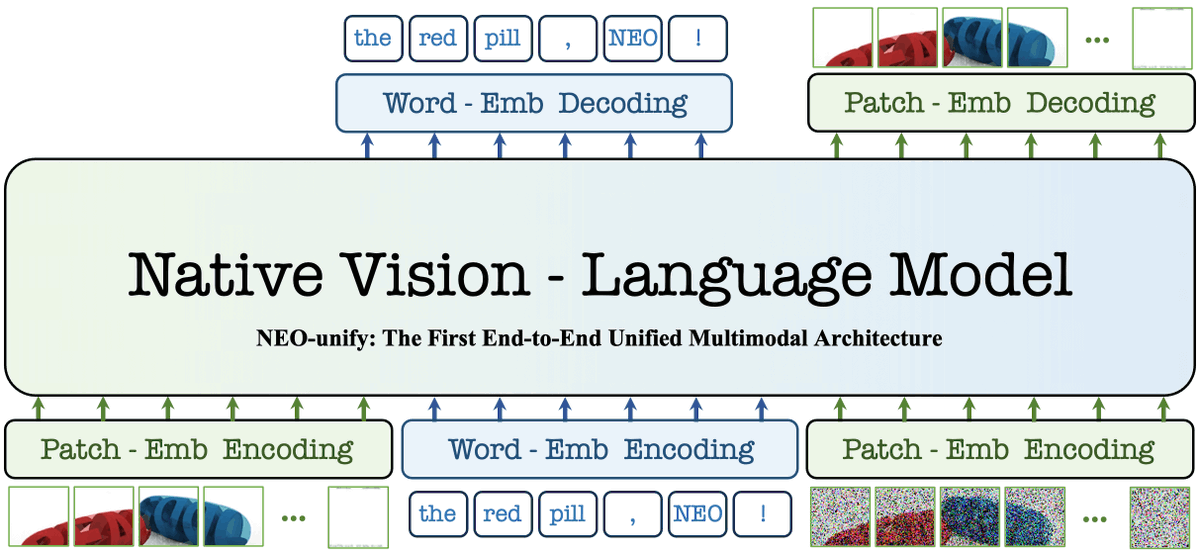
Sabitlenmiş Tweet

🚀🚀We’re building a new Applied Research Team in Tencent IEG for Game AI, with a research culture similar to ARC Lab.
This newly formed team focuses on research-driven Game AI, operating at the intersection of fundamental research and large-scale game environments. Our goal is to develop principled models that can understand, simulate, and act within complex virtual worlds—while remaining grounded enough to eventually shape real games.
Our research directions include (but are not limited to):
🎮 Interactive & Dynamic World Modeling — learning, simulating, and reasoning about evolving game worlds
🤖 NPC World-to-Action Modeling — connecting world understanding to decision and action, with strong ties to Embodied AI and agent behavior
🌍 Game Scene Generation — generative modeling of diverse, controllable, and scalable game scenes
We are looking for researchers with the following minimum qualifications:
✨ A recent Ph.D. in related fields
✨ 5+ top conference or journal papers
✨ 1000+ GitHub stars
🌟 Evidence of a “make it work” mindset
We are also open to strong graduate students for intern positions. Feel free to DM me or contact: hanswen@tencent.com.
English