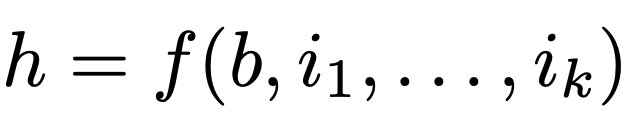
Sabitlenmiş Tweet

Can we actually TRAIN LLMs for scientific discovery — or only prompt them to brainstorm? 🧬✨
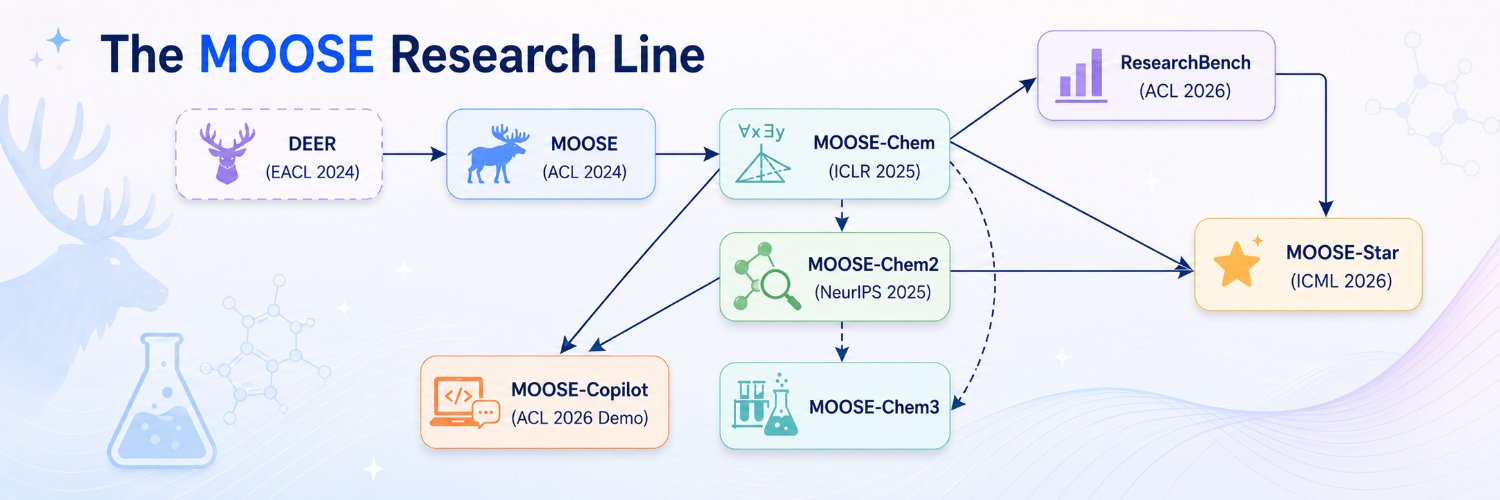
🎉 MOOSE-Star → #ICML2026
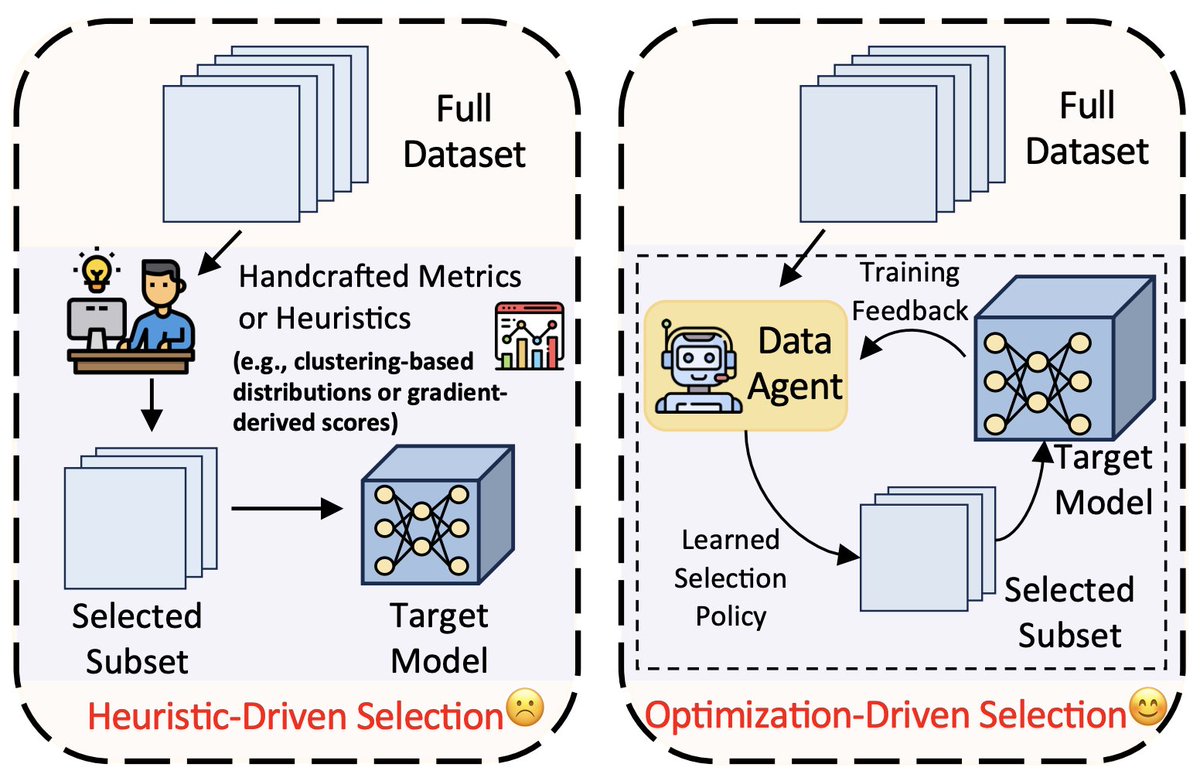
Most work on LLMs for hypothesis discovery focuses on inference-time agents or feedback-driven refinement. The core generative process — P(hypothesis | research background), or P(h|b) — has been largely sidestepped: directly training it remains an open problem. We show why: a combinatorial complexity barrier makes naive end-to-end training mathematically intractable.
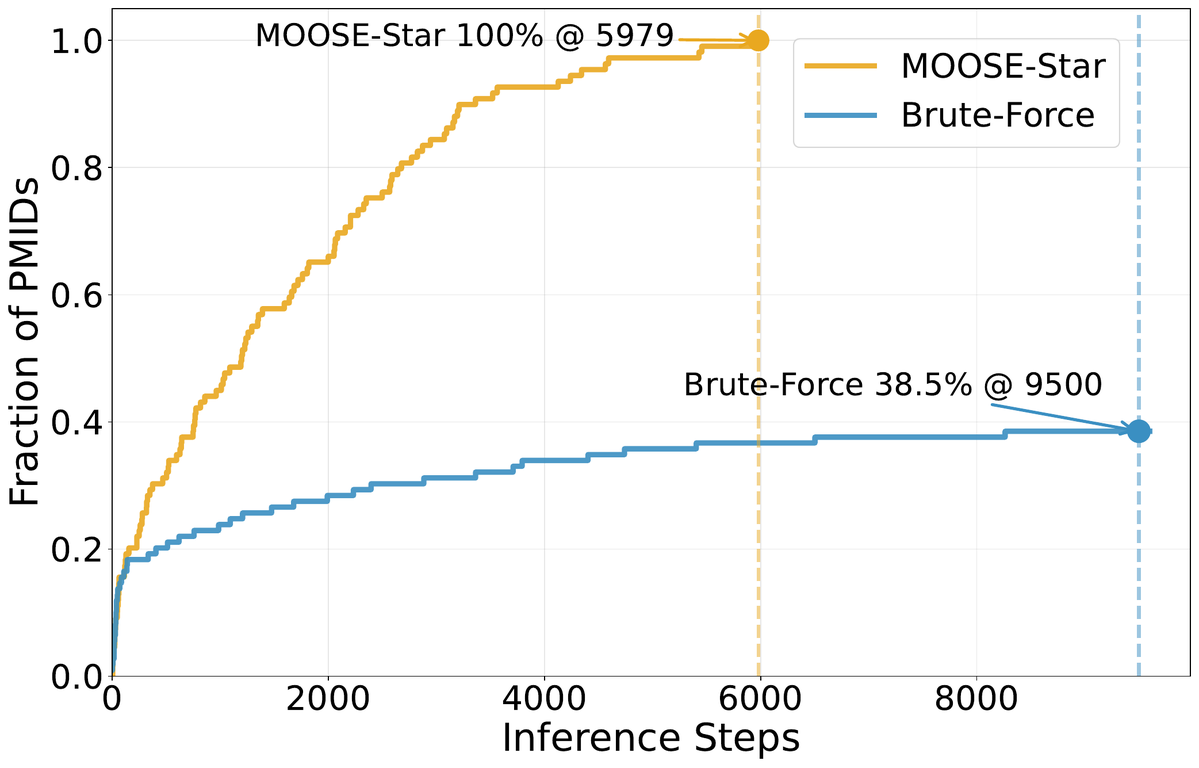
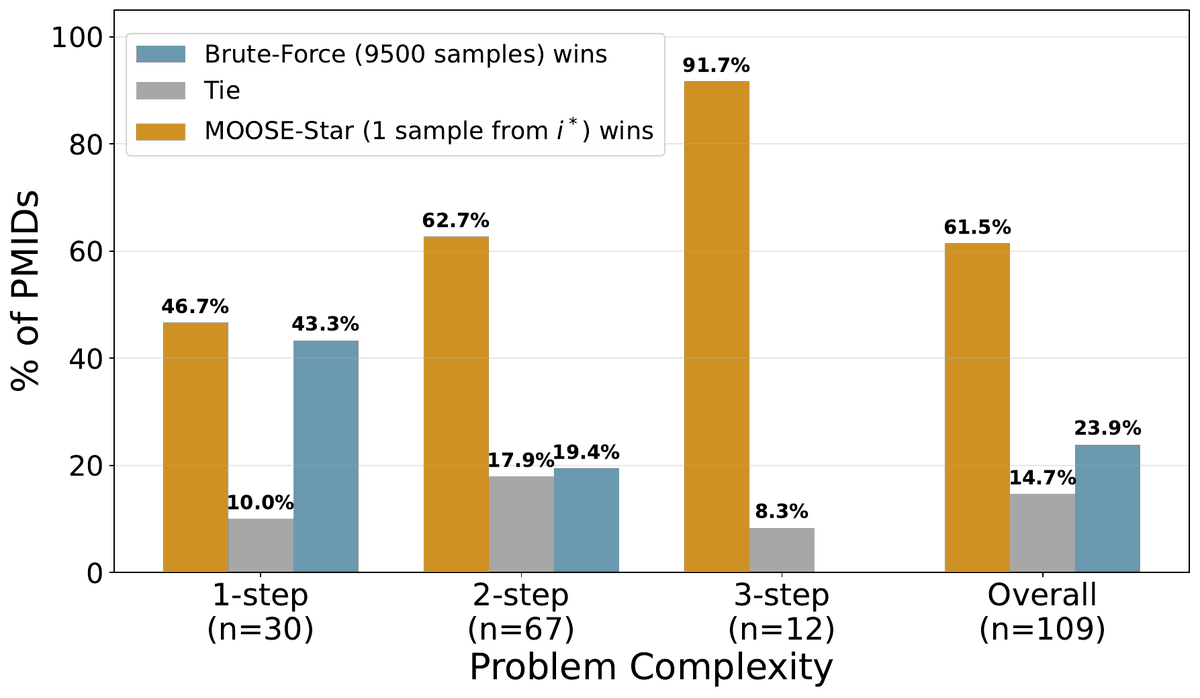
First scalable recipe for training P(h|b), with clean scaling laws on both training data and test-time compute.
📄 Paper: arxiv.org/abs/2603.03756
💻 GitHub: github.com/ZonglinY/MOOSE…
🤗 HF: huggingface.co/collections/Zo…
🧵👇

English