Sabitlenmiş Tweet

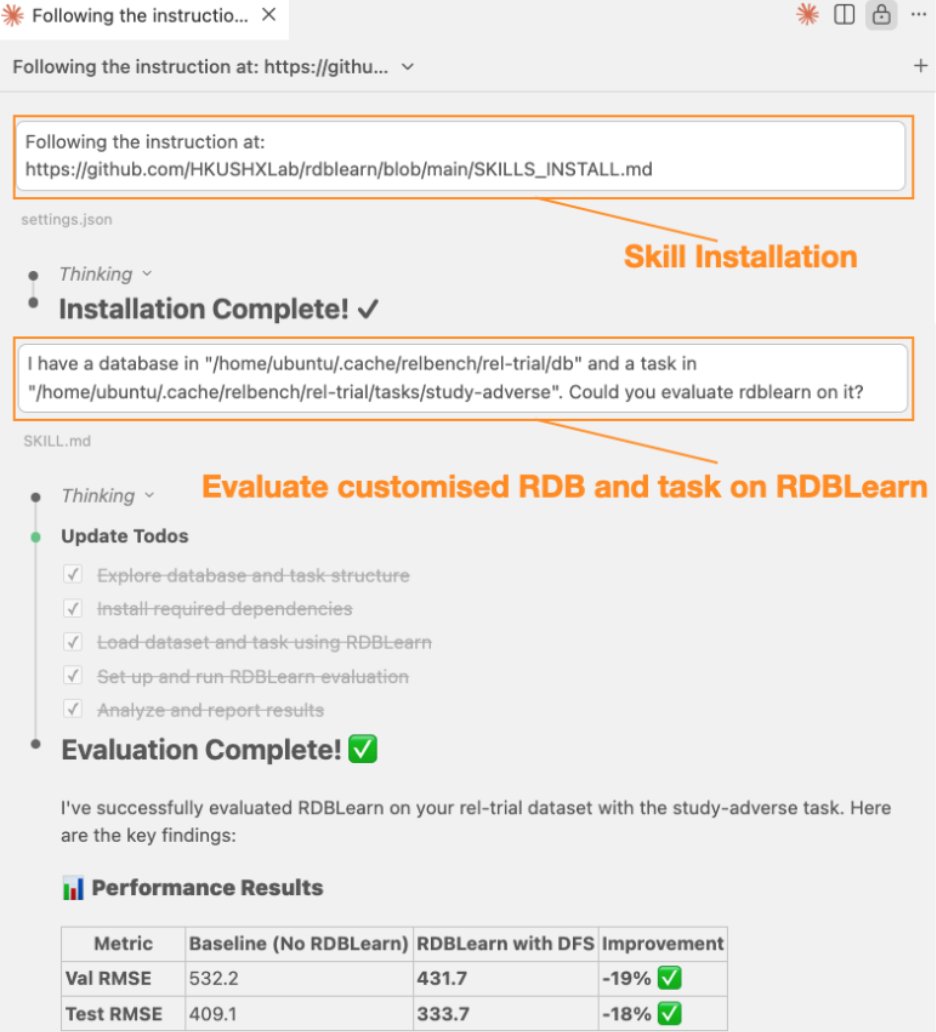
(1/3) Enterprise RDBs rarely change their structure, but meet new ML tasks every day. The RDB foundation model (FM) fits this position well because no task-specific training is needed.
Our latest work uses intra-column encoding and tabular FMs, achieving SOTA performance.

English