Yiming
98 posts


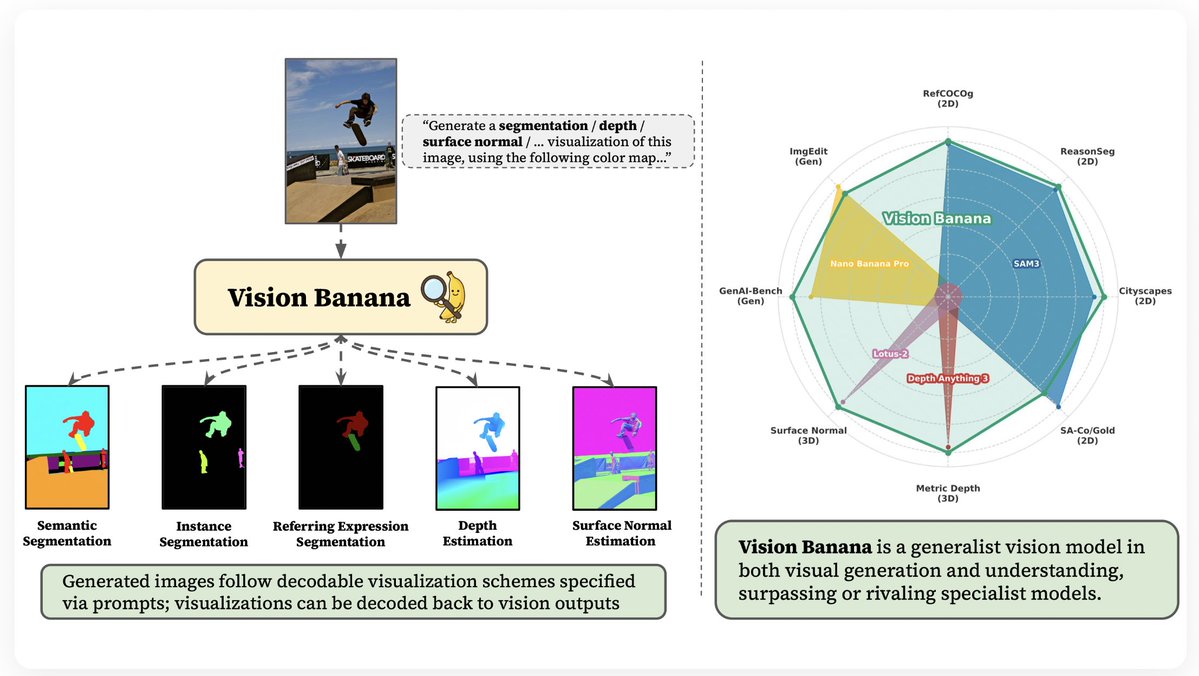
Introducing Vision Banana🍌: an image generator that achieves SOTA on segmentation, depth prediction, and surface normal estimation 🚀
🖼️Project page: vision-banana.github.io
📜Technical report: arxiv.org/abs/2604.20329
🧵👇

English

Yay, finally! Introducing Vision Banana🍌 from @GoogleDeepMind, our unified model that outperforms SoTA specialist models on various vision tasks!
By treating 2D/3D vision tasks as image generation, we unlock a new foundation for CV.
Project page: vision-banana.github.io
(1/5)
English

🚀 Excited to announce Vision Banana 🍌 and our new paper: “Image Generators are Generalist Vision Learners”. We turn Nano Banana Pro into a state-of-the-art visual generation and understanding model.
🖼️ Check out our gallery at vision-banana.github.io
🧵 (1/N) continue ⬇️
English

From my old team at Google DeepMind (GDM) — Gemini multimodal just launched a whole new paradigm for computer vision using unified diffusion models! 🔥
(I am in the acknowledgement list haha!)
Radu Soricut@RSoricut
Meet Vision Banana 🍌 from @GoogleDeepMind! We provide strong evidence that image generators are generalist vision learners. Traditional computer vision tasks (segmentation, depth estimation, normal prediction) can now be performed at/near SOTA with a single generalist model derived from an image generation model. 🖼️ Explore the results: vision-banana.github.io 📄 See details at: arxiv.org/abs/2604.20329
English
Yiming retweetledi

Meet Vision Banana 🍌 from @GoogleDeepMind! We provide strong evidence that image generators are generalist vision learners. Traditional computer vision tasks (segmentation, depth estimation, normal prediction) can now be performed at/near SOTA with a single generalist model derived from an image generation model.
🖼️ Explore the results: vision-banana.github.io
📄 See details at: arxiv.org/abs/2604.20329
English
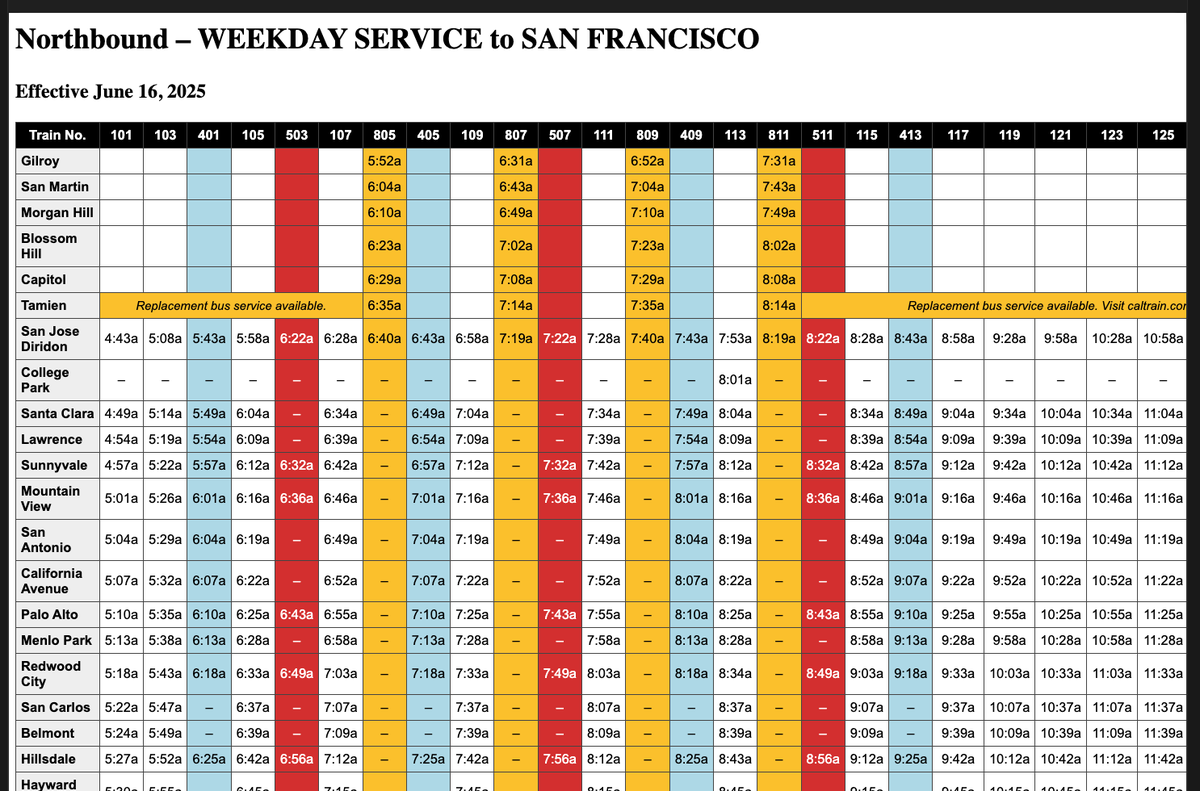
@jerryjliu0 Hi Jerry what prompt and inference setting are you using?
I'm using the prompt: "first read the rows of the table line by line, and then try to parse the entire table image into an html" with default media resolution and thinking level high, and the result looks quite different
English

I tried out Gemini 3 Pro on document parsing tasks 📄🤖
Tl;dr it’s pretty good at general visual understanding, but still can’t one-shot tables (and qualitatively seems worse than some other models at table understanding)
A great addition to any document OCR toolkit, especially for specialized visual understanding, but would need the surrounding pipeline to be a standalone document parsing solution.
I tried on high media resolution, low thinking, directly in AI studio 🧵
English
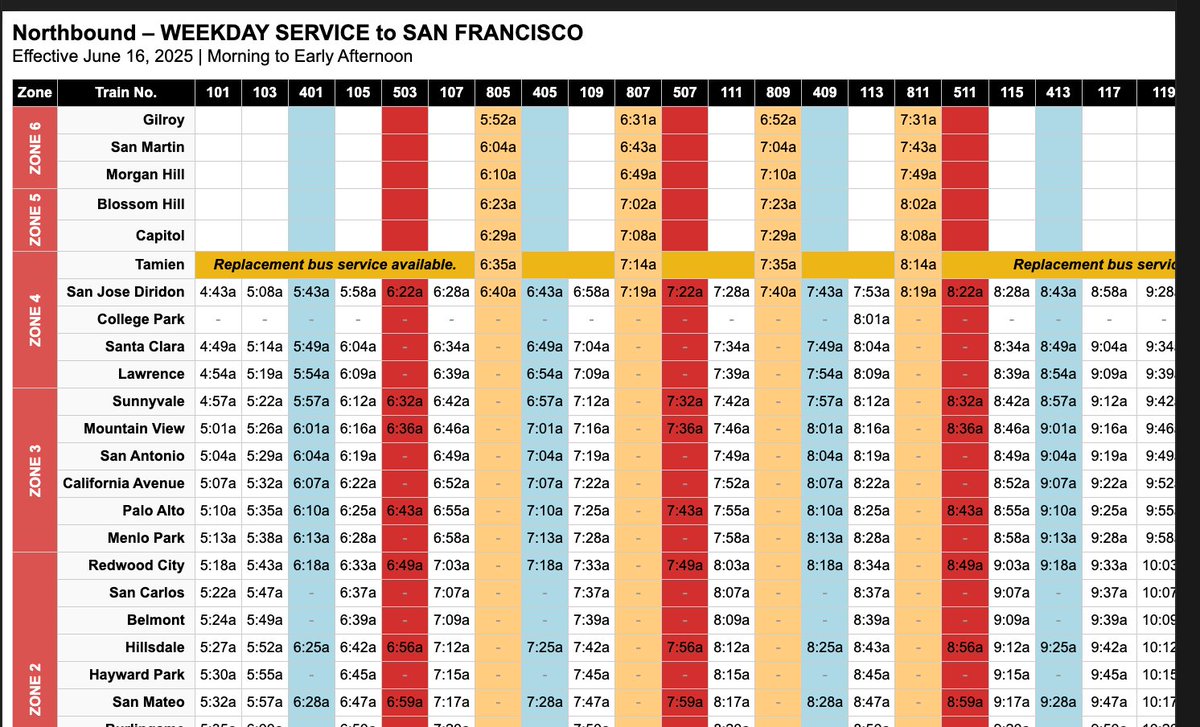
@jerryjliu0 Hi Jerry what exact prompt and settings are you using?
I am trying this particular image with prompt "first read the rows of the table line by line, and then try to parse the entire table image into an html" with default resolution and high thinking, the result is different.
English

