Sabitlenmiş Tweet

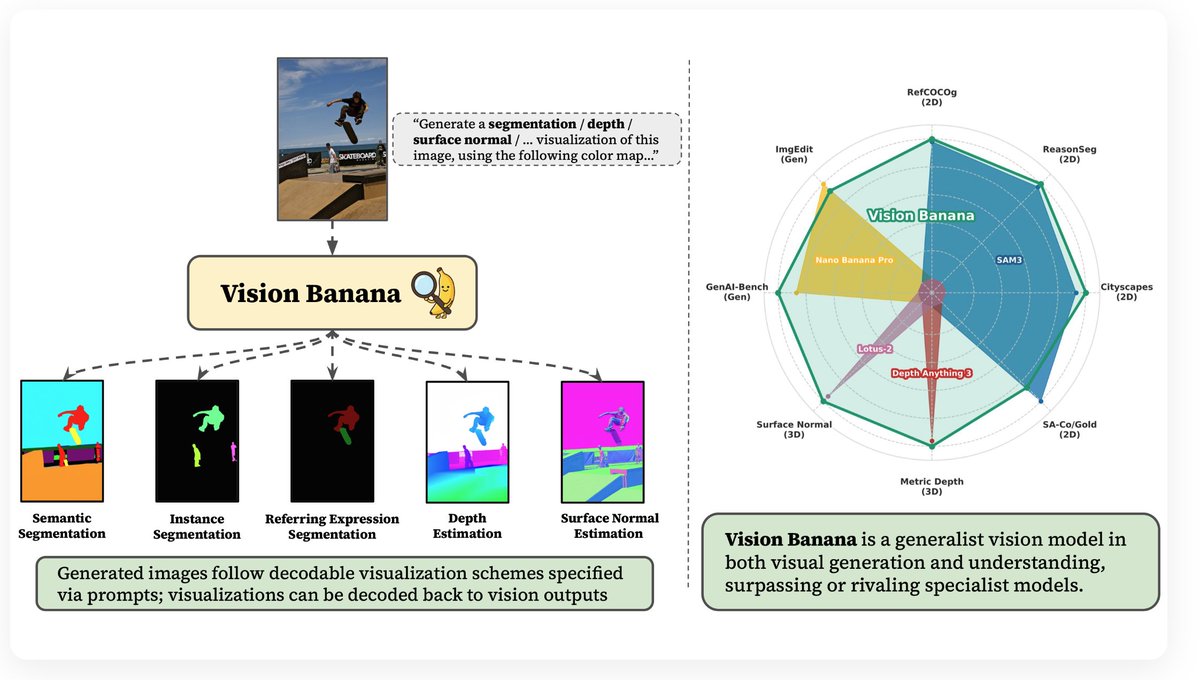
🚀 Excited to announce Vision Banana 🍌 and our new paper: “Image Generators are Generalist Vision Learners”. We turn Nano Banana Pro into a state-of-the-art visual generation and understanding model.
🖼️ Check out our gallery at vision-banana.github.io
🧵 (1/N) continue ⬇️
English