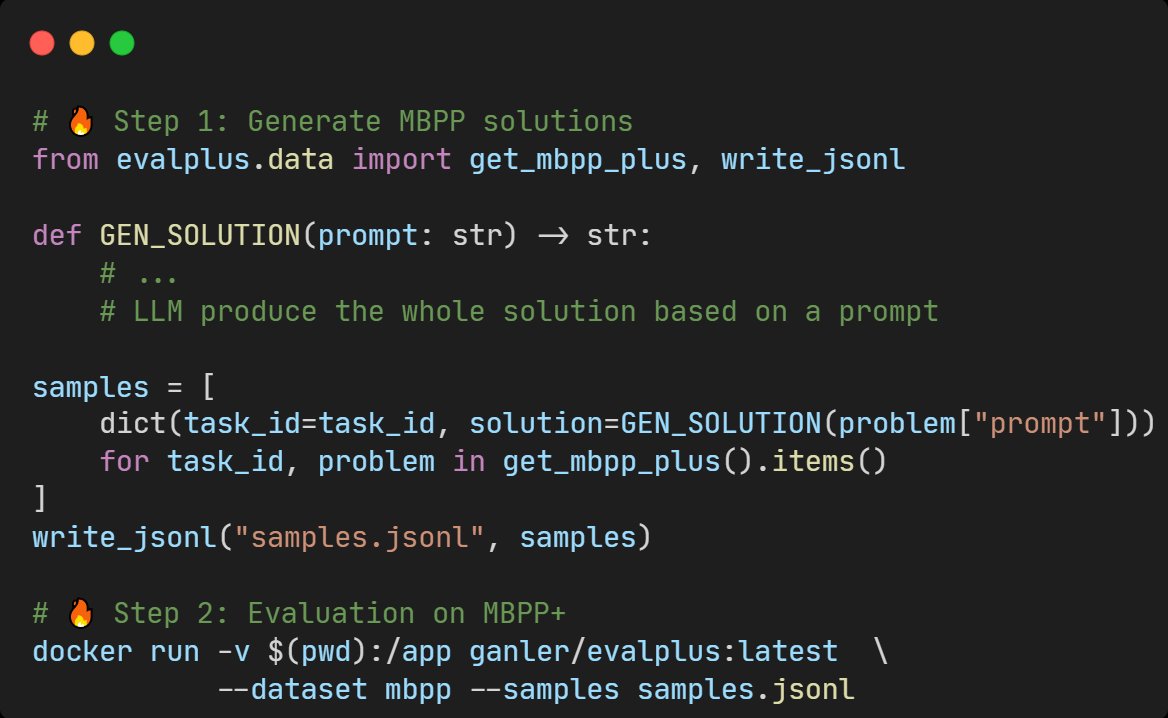
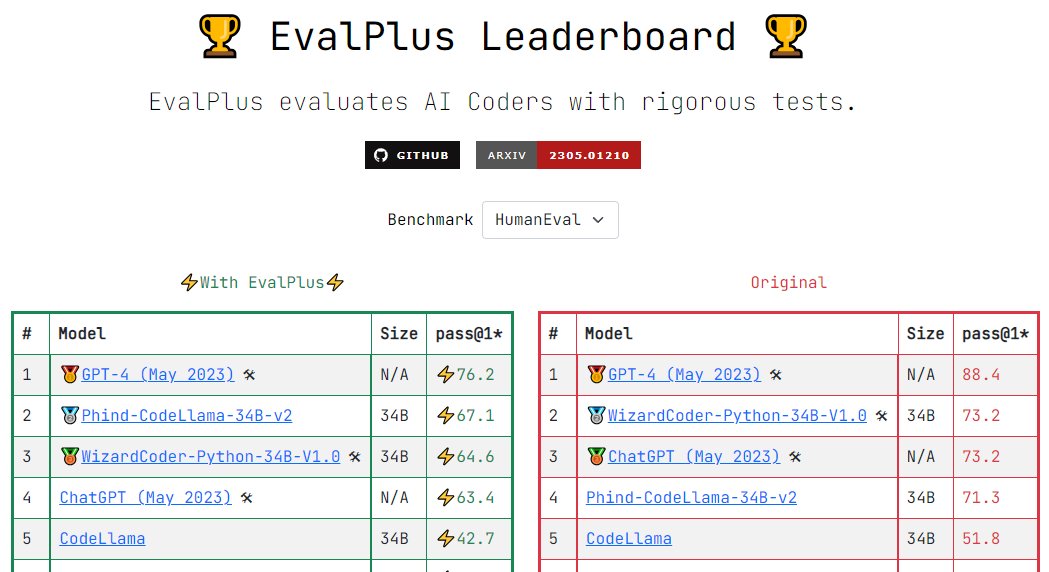
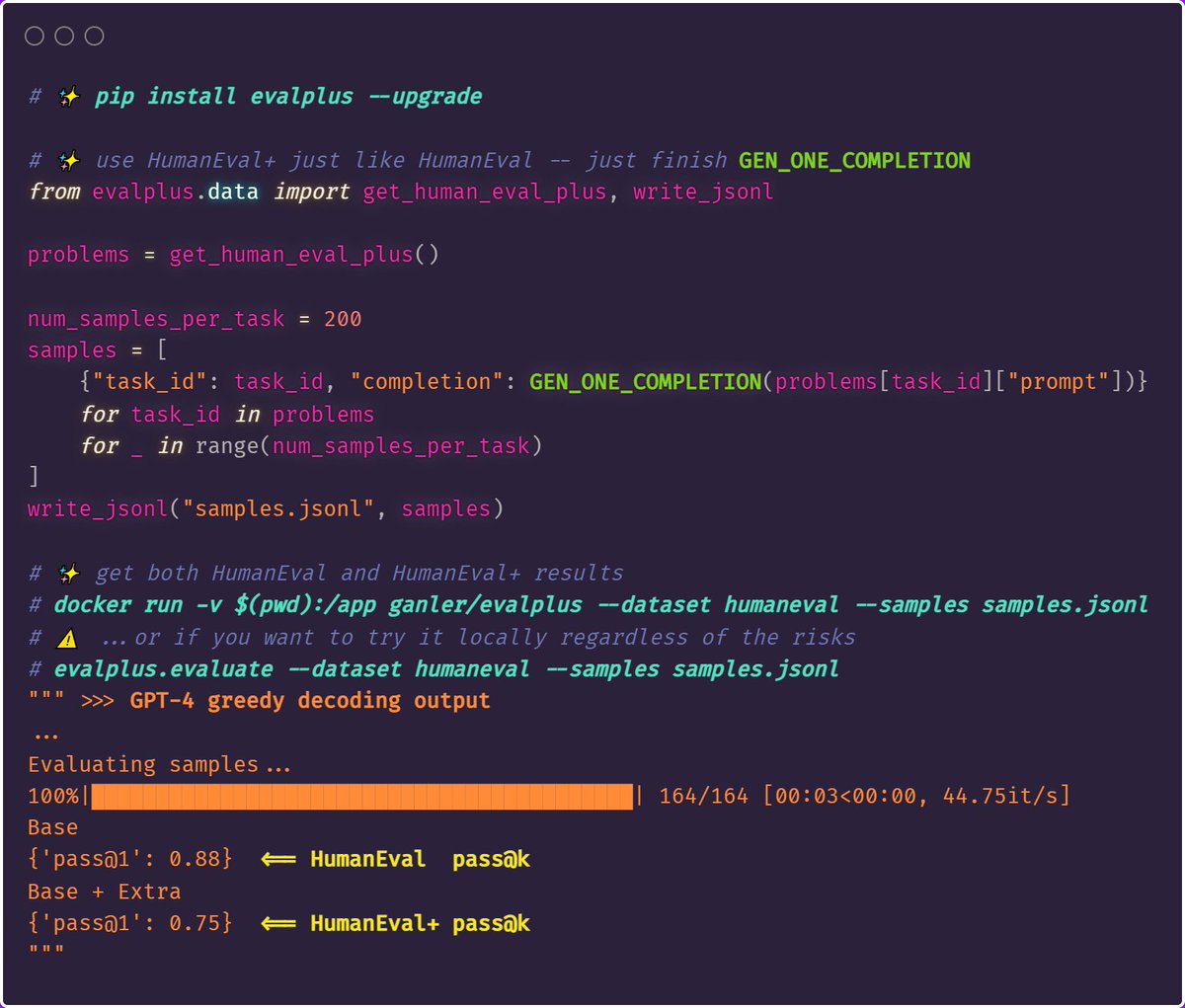
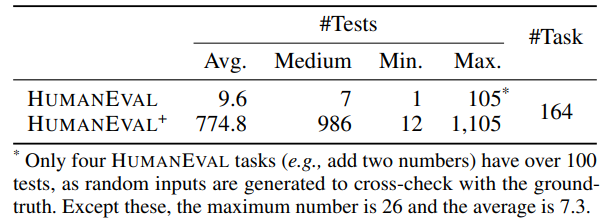
Yuyao Wang retweetledi

Interested in program synthesis for creating random DNNs? and its application on automated testing?
Check our new work: “NeuRI: Diversifying DNN Generation via Inductive Rule Inference” with a Distinguished Paper Award @FSEconf!
w/ Jinjun, @YuyaoStarling, @LingmingZhang

English